- Home
- /
- Analytics
- /
- Stat Procs
- /
- Re: GLIMMIX why does it give me pseudo akaike?
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I'm running a glimmix procedure in sas. But the outcomes it gives me are "pseudo"akaike values, and does not give a akaike weights for each model. Why this is happening? And how could I get akaike weights?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi! Nobosy answered, but I found the answer somewhere else. FYI if you use "laplace"method (METHOD=laplace) it will give you the aic values. BUT I'm not sure about other effects of this method... actually I'm trying to figure that out
Bye!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi FranAstorga.
I only just got to helping out on this forum recently. Good on you for finding the explanation. I'm a fan of the laplace method in GLIMMIX as it has decreased estimation time and memory resource demands on big data sets dramatically. Another effect of this method is that in some situations it may introduce estimate bias..there is a note to this effect in the GLIMMIX documentation..from memory when number of repeat measure on subject are low. However if GLIMMIX fits a psuedo-likelhood with another option successfully as well to your data you could always use that as a check for bias and if none is evident then use the non-psuedo AIC (sounds better than it is I suspect!) with confidence where needed.
Good luck with your GLIMMIX analysis.
- Damien Mather

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Actually, the pseudo-likelihood method (the default) is the method that may give biased results, not the Laplace method. The Laplace method, or even better, the quadrature method, will have the lowest bias. However, the criticisms of the pseudo-likelihood method for bias are often overblown. Only with very small number of observations per unit will there be bias with random effects. Walt Stroup writes a lot about all of this in his excellent book on generalized linear mixed models.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ivm,
I agree with your point when there are plenty of repeated observations in each subject cluster, either as discrete observations or via a frequency variable in the data. At least one other of our highly esteemed and luminary community members also agrees with you. However where this is not always the case, to quote
"
... In this case, provided that the constant ![]() is large, the Laplace approximation to the marginal log likelihood is
is large, the Laplace approximation to the marginal log likelihood is
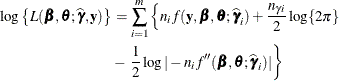
"
I researched what is considered 'large' and found some surprising opinions - like 30(!) so I compared some of my own models, and found, to my relief, that 3-4 repeated measures did indeed indicate the laplace method was preferred. I'm now not so sure about precision of the LL approximation when there are fewer measures per subject cluster.
Has anybody else noticed thought about this?
Cheers.
Damien
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The meaning of "large" is definitely context dependent. And there is no doubt that all the GLMMs can lead to biased parameter estimates. The bias will depend on many things, and usually has to be assessed with simulation, since GLMMs depend on many approximations. In his textbook, Stroup (2013) has an excellent presentation on this, with extensive results for (conditional) binomial data. His results show the least bias for quadrature (almost unbiased), followed by Laplace (small bias), and then pseudo-likelihood (highest bias). But even pseudo-likeilihood has only minor bias when the number of observations per cluster is moderate.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
In my opinion, the real drawback to the pseudo-likelihood method in GLMMs is the inability to use information criteria as a guide in selecting covariance structures, as the pseudo-data at each iteration will differ depending on the structure being examined. If the potential structure is limited to a single type due to other considerations (spacing in time, etc.) then this isn't a problem, and the PL methods, which are numerically less intensive, have a lot to offer.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I agree with Steve: pseudo-likelihood is a very good method. A few papers were overly harsh on it. It holds up well under many circumstances.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi there! I moved this inquiry over to the Statistical Procedures community, where you're sure to get other helpful perspectives.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →ANOVA, or Analysis Of Variance, is used to compare the averages or means of two or more populations to better understand how they differ. Watch this tutorial for more.

Find more tutorials on the SAS Users YouTube channel.
-
8 replies
-
07-08-2014 05:48 PM
-
4545 views
-
0 likes
-
5 in conversation
-
