- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Parse a long text field with varying length results to new variabl...
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have a long text variable, already in a SAS dataset, that has this format (2 rows shown, I apologize for the lack of input statement, but with the semicolons (yes, really!) in there, I was not sure how to get them in as datalines):
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
Additional rows have more like that. Basically the part before the colon is text of some kind and many lengths, and the part after the colon is a number, each pair are separated by a semicolon. There are up to 13 pairs of text with a number in a given observation.
I want to be able to make new variables, splitting the field up at the colons and semicolons. This is the desired result for the example (and wow, cannot paste here?):
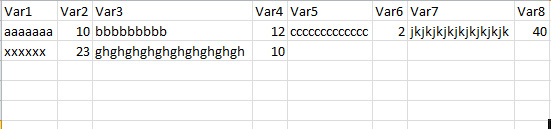
Sorry for the image, my browser does not seem to support my pasting here.
I have searched the discussion groups, tried various combinations of creating arrays, using the scan function. But those assume you know how may variables each row will create. I tried using call symput to assign the count of the number of : and ; to a macro variable, which could then be used to assign the dimension for the array for each row.
I could probably cop out and figure out my biggest set of pairs, use double that number as a dimension, figure out my longest new variable length, and then set all the new variable made from the array to the length.
I will keep looking online. I just thought I would ask. This is like excel's text to column function. I basically need to tell sas "split this long text field into new variables at the ; and : marks"
Thank you,
Nicole
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Another shot:
data have;
infile cards truncover ;
input var $300.;
cards4;
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
;;;;
data want1;
set have;
n=_n_;
do _n_=1 by 1 while (not missing (scan(var,_n_,':;')));
temp=scan(var,_n_,':;');
output;
end;
run;
proc transpose data=want1 out=want (drop=n _name_);
by n;
var temp;
run;
This should be dynamic, you can play with prefix option if you are not happy with the default 'col's
Good luck,
Haikuo

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Would your first line have a different meaning if the order of label:value pairs was changed? I.e. if it was
bbbbbbbbb:12;aaaaaaa:10;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
PGStats, no, I do not think that it would make a difference. I provided dummy data. In the real world, the text is a department, and the number is the number of hours spent there. Although it would be convenient if Var1 was always the same department when the long field had the same ones in it. In other words, if another row starts with aaaaaaa:8, I would want the aaaaaaa to appear in Var1.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I would do something like this:
data have;
length text $200;
input text;
datalines4;
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
;;;;
data list;
length pair $64 label $24;
set have;
line + 1;
do i=1 to countw(text,";");
pair = scan(text,i,";");
label = scan(pair, 1, ":");
if not missing(label) then do;
value = input(scan(pair, 2, ":"), best.);
output;
end;
end;
keep line label value;
run;
proc transpose data=list out=want(drop=_name_);
by line;
id label;
var value;
run;
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
PGStats--thank you, I will attempt to apply that code to my situation, and report back on how it works. However, if my initial reading of your code is correct, it still requires me to go in and figure out the length of my future variables ahead of time. so I can set the length of pair and label. Again, I was hoping for a way for that to by determined dynamically. But I guess, in thinking about it, that is not realistic, since SAS requires us to either set the length, or uses the first value received to set it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
My code doesn't generate any character variable. The labels become the names of numeric variables (they are limited to 32 characters by SAS naming rules). Intermediate character variables pair and label can be given a rather large size since they are not kept in the end.
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Ok, thank you for clarifying PGStats. The statistician actually wants the character part in a variable, not as a name of the numeric variables. Like I pointed out in my original post......that is the desired format (although there will be more fields). I am going to keep your code on hand though, as there are times when they do want the character portion to label the numeric. :smileygrin:
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Will something like this work for you?
data test;
infile cards truncover dsd dlm=';:';
input (var1-var8) (:$30.);
cards4;
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
;;;;
Haikuo
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Hai.kuo. Infiling data is not my strong suit---most of my stuff comes from access or excel or sql server.![]() And my data is already in a SAS dataset. I have to pull apart what I already have. Unless you think I should save it out to a text file and try infiling it back in?
And my data is already in a SAS dataset. I have to pull apart what I already have. Unless you think I should save it out to a text file and try infiling it back in?
But that will not work overall, because there can be up to 13 pairs (so 26 new variables created) and the length of the text portions can vary quite a bit.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
A variation on Hai.kuo's approach:
data want;
infile datalines missover dsd dlm=';:';
length var1 var3 var5 var7 var9 var11 var13 var15 var17 var19 var21 var23 var25 $ 256;
input var1-var26;
cards4;
... the data lines that you would like ...
;;;;
It's important to remove formatting instructions from the INPUT statement when scanning a line from left to right. When using the combination of (: $30.) the software searches for a non-delimiter and then reads the next 30 characters regardless of whether or not they contain a delimiter.
Good luck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Astounding, for the response.
Maybe I am missing something.........I'm not sure why an infile statement would be appropriate. This long text variable is already in SAS. It is in a dataset that was provided to me by another group where I work--they created it from sql server. I do not have access to the "raw" data. And there are a bunch of other variables in the sas dataset, so I am really just looking to parse this long field into new variables.
I literally have a 600 length field with one long string in it. The string is text and numbers, separated by : and ; as indicated above.
Is the only way to do this to export it and bring it back in? I was thinking there might be a more dynamic way to use what is already there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Another shot:
data have;
infile cards truncover ;
input var $300.;
cards4;
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
;;;;
data want1;
set have;
n=_n_;
do _n_=1 by 1 while (not missing (scan(var,_n_,':;')));
temp=scan(var,_n_,':;');
output;
end;
run;
proc transpose data=want1 out=want (drop=n _name_);
by n;
var temp;
run;
This should be dynamic, you can play with prefix option if you are not happy with the default 'col's
Good luck,
Haikuo
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Haikuo--I will try yours too. I appreciate the support!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have tried this static code.....
data have;
infile datalines missover;
input text $63.;
datalines4;
aaaaaaa:10;bbbbbbbbb:12;ccccccccccccc:2;jkjkjkjkjkjkjkjkjk:40;
xxxxxx:23;ghghghghghghghghghgh:10;
;;;;
data want(drop=text);
set have;
array var(8) $ var1-var8;
do i=1 to 8;
var(i) = scan(text,i,':;');
end;
Ofcourse there are better solutions above..... 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
No, I was the one who was missing something. Here's part 1, determine the lengths needed.
data _null_;
retain max_pair max_label 0;
set have end=done;
i=0;
length next_piece $2000;
do until (next_piece=' ');
i+1;
next_piece = scan(long_var, i, ';:');
if mod(i,2)=1 then max_pair = max(max_pair, length(next_piece));
else max_label = max(max_label, length(next_piece));
end;
if done;
call symputx('max_pair', max_pair);
call symputx('max_label', max_label);
run;
That gives you macro variables holding the length needed for the section before the colon (&max_pair) and the section after the colon (&max_label). They could be used in a later program in various ways, such as:
array pairs {13} $ &max_pair;
Do you need a more specific solution than that? For example, in your diagram, would you like VAR1 and VAR3 to have the same length, or should we assign separate lengths to each? (Or doesn't it matter?)
For part 2, I was unsure of the proper result. Are you guaranteed a maximum of 13 pairs per observation? Do you want to keep the data in its current structure as in your original diagram? The alternative would be to output each pair as a separate observation. Either is possible ... just want to make sure I solve the right problem.
Sorry for all the questions, but they do affect the solution. And there definitely are possible solutions.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
18 replies
-
08-13-2014 01:40 PM
-
10310 views
-
8 likes
-
7 in conversation
-
