- Home
- /
- Programming
- /
- SAS Procedures
- /
- Obtaining Unique Variable Profiles For Categorical Variables
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have a dataset in which I have several categorical (and continuous) variables. I am only interested in the unique variable profiles (i.e. combinations) of the categorical variables.
Is there a way in a single or several datasteps to 1) obtain the unique variable profiles, and 2) indicate to which variable profile a particular observation belongs. For example, I've attached a small table below in which I have 3 categorical variables, Cat1-Cat3 (for simplicity, they are binary), and 5 different observations. With the 3 categorical variables, there should be 2^3 variable profiles. Observations 2 and 3 should have the same variable profile, while 1,4, and 5 are unique. I want to be able to extract this information from a dataset and then assign the profile # to each observation. Thanks!
| Obs | Cat1 | Cat2 | Cat3 |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
3 | 0 | 1 | 0 |
| 4 | 1 | 1 | 1 |
| 5 | 1 | 0 | 1 |

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Would a new data set with a frequency count for each combination help? Then try
PROC SUMMARY DATA= your.data MISSING NWAY ;
CLASS _CHARACTER_ ;
OUTPUT OUT= combo_counters( DROP= _type_ ) ;
RUN ;
If you only want to generate an extra variable that could be a unique reference to the combinations the following might help.
* find the "final" character variable ;
%LET your_data = YOUR.DATA ;
PROC SQL NOPRINT ;
SELECT name INTO :final_name
FROM dictionary.columns
WHERE libname = "%UPCASE(%SCAN(&your_data,1,.))"
AND memname = "%UPCASE(%SCAN(&your_data,-1,.))"
GROUP BY 1 HAVING varnum = MAX( varnum )
;
QUIT ;
* put data into combo order ;
PROC SORT DATA = &your_data OUT= ordered ;;
BY _CHARACTER_ ;
RUN ;
* assign variable COMBO_REF unique for each combination of the character variables ;
DATA combos_flagged ;
SET ordered ;
BY _CHARACTER_ ;
combo_ref + FIRST.&final_name ;
RUN ;
(beware untested code)

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is my try...
data have;
input cat1 - cat3;
_temp1 = compress(cat1||cat2||cat3); /* Create Macro Variable if number of variables are more */
cards4;
1 0 0
0 1 0
0 1 0
1 1 1
1 0 1
;;;;
proc sort data = have;
by _temp1;
run;
data want(drop = _temp1);
set have;
by _temp1;
if first._temp1 EQ last._temp1 then unique_profiles + 1;
run;
If there are so many variables in your dataset then include all those variable names in to one macro variable...
-Urvish

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I was a bit shocked that the arguments to INDEX data set option do not accept "SAS Variable Lists".
input cat1-cat3;
cards;
1 0 0
0 1 0
0 1 0
1 1 1
1 0 1
;;;;
run;
proc summary data=have nway completetypes;
class cat:;
output
out=profile
(
drop=_type_
rename=(_level_=profile)
index=(cat=(cat1 cat2 cat3))
)
/ levels;
run;
proc print;
run;
data cat2;
set cat;
set profile key=cat/unique;
run;
proc print;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
John,
I think you'll find that the problem is much simpler if you reverse the order. Assign PROFILE to each observation, then get a dataset holding the unique profiles. For example:
data want;
set have;
profile = catx('#', var1, var2, var3);
run;
proc sql noprint;
create table profile_list as select distinct profile from want;
quit;
Good luck.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
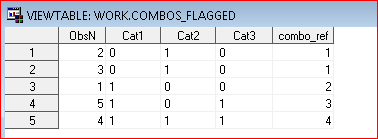
JohnPura
sorry about my earlier untested code (with bug)
The line
GROUP BY 1 HAVING varnum = MAX( varnum )
should not use that GROUP BY
I have tested data and process, like
LIBNAME YOUR (WORK) ;
DATA DATA ;
INPUT ObsN 3. (Cat1 Cat2 Cat3)( :$5. ) ;
LIST;CARDS;
1 1 0 0
2 0 1 0
3 0 1 0
4 1 1 1
5 1 0 1
;
%LET your_data = YOUR.DATA ;
%LET VARLIST = CAT1 CAT2 ;
PROC SQL NOPRINT ;
SELECT name
INTO :final_name separated by '/'
from ( select name
FROM dictionary.columns
WHERE libname = "%UPCASE(%SCAN(&your_data,1,.))"
AND memname = "%UPCASE(%SCAN(&your_data,-1,.))"
having varnum=max(varnum) /* fixing error on earlier*/
)
QUIT ;
* put data into combo order ;
PROC SORT DATA = &your_data OUT= ordered ;;
BY _CHARACTER_ ;
RUN ;
* assign variable COMBO_REF unique for each combination of the character variables ;
DATA combos_flagged ;
SET ordered ;
BY _CHARACTER_ ;
combo_ref + FIRST.&final_name ;
RUN ;
The code is structured to avoid having to specify any column names.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
5 replies
-
01-08-2014 12:39 AM
-
3159 views
-
2 likes
-
5 in conversation
-
