- Home
- /
- Analytics
- /
- Stat Procs
- /
- Re: ANCOVA with "Day number" as covariate
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello!
I've got some problems with selecting right model/method in my analysis.
Two groups of animals (differ by "Treatment") were measured from 1-st to 42-nd day, one common value for each group was measured by each day (food consumption per day).
I need to compare this groups and I want to use ANCOVA with "Treatment" as fixed effect and "Day number" as covariate in the model.
There are many examples which contain covariates with some sort of randomness in their distribution (like weight, age, IQ, etc., where we can't directly control this variable).
But in our experiment we eliminate this variation by measuring groups day by day. Is it correct to use "Day number" as continious covariate?
Maybe the whole model is incorrect and you can suggest right one?
Best regards!
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
OK, then we can trim things down some, rearrange and see what happens:
proc glimmix data=yourdata method=laplace;
class treatment day_no ;
model response_variable=treatment day_no;
random day_no/subject=treatment type=ar(1) ;
lsmeans treatment/diff;
run;
At least this way the standard errors reflect the within subject correlation.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
What was measured on each day? It looks to me like a repeated measures design, so something like:
proc glimmix data=yourdata;
class treatment day_no anml_no;
model response_variable=treatment|day_no/ddfm=kr2;
random day_no/residual type=ar(1) subject=anml_no;
random intercept/subject=anml_no;
lsmeans treatment/diff;
lsmeans treatment*day_no/slicediff=day_no;
run;
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello Steve!
Thank you very much for answer! But it's impossible to use here a repeated measures design... in classical meaning.
I have just one average value of food consumption per day for each group, I haven't concrete subjects.
There is example of my data:
| Day | Treat | Av. value |
|---|---|---|
| 1 | treat 1 | 0.24 |
| 1 | treat 2 | 0.35 |
| 2 | treat 1 | 0.52 |
| 2 | treat 2 | 0.64 |
| ... | ... | ... |
| 41 | treat 1 | 5.47 |
| 41 | treat 2 | 5.20 |
| 42 | treat 1 | 5.31 |
| 42 | treat 2 | 5.43 |
Many thanks in advance!
Best wishes!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
OK, then we can trim things down some, rearrange and see what happens:
proc glimmix data=yourdata method=laplace;
class treatment day_no ;
model response_variable=treatment day_no;
random day_no/subject=treatment type=ar(1) ;
lsmeans treatment/diff;
run;
At least this way the standard errors reflect the within subject correlation.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Steve!
I'm really beginner at using methods above PROC GLM.
When I tried to solve the problem I used this code:
proc glm data=mydata;
class treatment;
model response_variable=treatment day_no;
lsmeans treatment;
run;
I planned to use day_no as covariate and to compare regression slopes.
Can you help me to understand what is my mistake?
Also I have some questions about your code.
1. Why did you use the GLIMMIX instead of, for example, MIXED?
2. You have use Laplace's approximation method for your analysis. Are there any criterions for choosing what method to use? SAS help does not give any advises for practical using just technical details.
3. There is the same problem with covariance structure type. I've checked a lot of sources and usually authors don't give any recommendations for choosing the right one c.s. for one or another real problem.
That would be really helpful if you turn me in the right direction.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The danger in the method with proc glm and assuming day_no as a covariate is an assumption of linearity. If your growth curve is linear, then that makes good sense. However, consider two treatments that start at exactly the same place, and end at the same place. In the first, the response goes up rapidly and then levels off (a bowl with the mouth down), while in the second the response is relatively flat until the end and then increases (same bowl with the mouth up). A linear covariate will not distinguish between these two cases--you will get nearly identical estimates of the slope.
Other questions:
1. Why GLIMMIX? It's more versatile than MIXED, so we use it almost exclusively for mixed model (including repeated measures).
2. I don't know what your response variable is--my guess is that it has a gaussian error. I just got slightly better results with method=laplace and a G side parameterization than with the default pseudo-REML and an R side parameterization. If your data has normally distributed errors, then the default is preferable.
3. Selecting covariance structures can get tricky, but for data with normally distributed errors, fit by default methods, using AICc is a good guide to choosing amongst various structures.
The idea of a semi-parametric approach to the day_no issue using a spline may be feasible, but I will need to explore my simulated data first.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks to all, who tried to help!
I will try to summarize information.
Helpful comment from another source:
The assumptions for an ANCOVA or similar general linear models are that the residuals are normally distributed and homoscedastic, and that each observation is independent.
Although not the residuals, the clear, curvy shape of your scatterplot indicates almost certain temporal autocorrelation, and therefore non-independence of observations.
Pictures of my data:
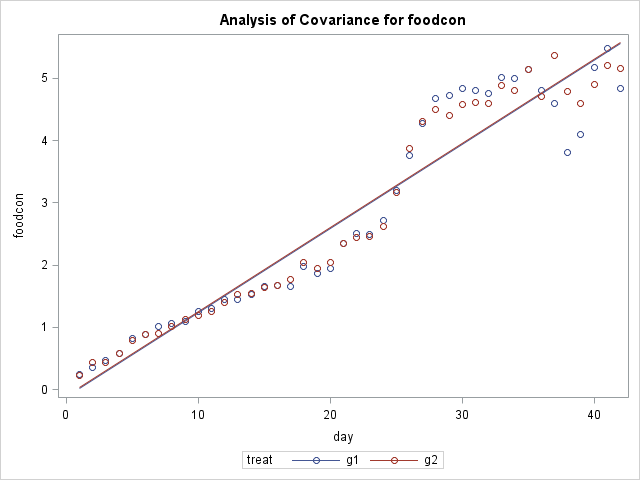
So the plan to using Repeated Measures ANOVA or ANCOVA with day number as covariate wasn't so good...
I have two ways to solve this problem today:
1. Classical (for my job colleagues) way and suggested by Nestor Rohowsky here: "to take the differences between means of Treatment 1 and Treatment 2 at each time to evaluate departures from 0."
2. Using GLIMMIX like SteveDenham wrote here.
I can't say, that everething is clear for me in second method, but it becouse of my low quality of knowledge of MIXED and GLIMMIX, so I feel, that it is the right way.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →ANOVA, or Analysis Of Variance, is used to compare the averages or means of two or more populations to better understand how they differ. Watch this tutorial for more.

Find more tutorials on the SAS Users YouTube channel.
-
6 replies
-
04-21-2014 07:06 AM
-
5676 views
-
6 likes
-
2 in conversation
-
