- Home
- /
- Programming
- /
- Programming
- /
- Re: proc surveyselec
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hallo SAS community.
I am stuck with a problem i hope you can help me with.
I have created the code:
proc surveyselect data= xxx.X201202 method=srs n=200 seed=200
out=test1;
Where department ne "AgroTech A/S";
Run;
However, i want to create a macro which loop through the data set
- Samlple1 .... Sample6
If the variable "Initials" from the sample1-6 is the same as initials in xxx.X201202 then these observationses should not be a part of the random sample of 200.
I hope you can help me.
/Jens

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I don't understand your question. If you simply want to randomly assign people to six different groups, without replication, then take a look at: 36383 - Randomly assign the observations in a data set to two or more groups
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have tried to make following code:
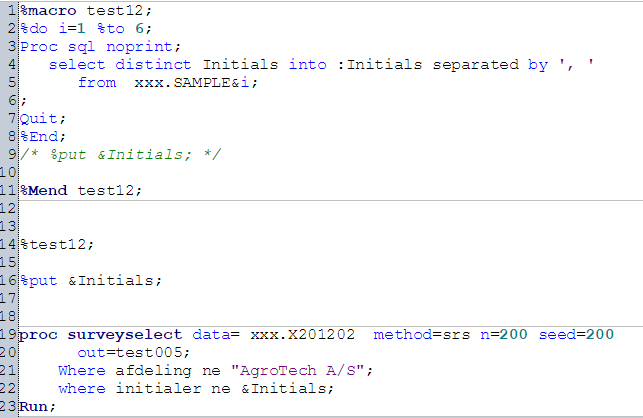
However, I have no idea if this is the right way to go. I hope you understand what my problem is...
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You have to indicate what you are trying to do. You're macro creates a local macro variable six times, each time discarding the previous version. I don't understand its purpose.
Your 2nd where statement doesn't make sense (to me). While you have shown any example data, a statement like:
where initialer ne 1, 3, 5;
won't work
I suggest you post some sample data, explain what you want to accomplish and, based on the sample data, what resulting file you want to obtain.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hallo again and thank you for your patience.
Data set 1
| Obs | Initials | Company | Cost |
|---|---|---|---|
1 | KLO | AgroTech A/S | 50000 |
| 2 | AVG | LEGO | 12000 |
| 3 | SLO | B&O | 53000 |
| 4 | NRL | AgroTech A/S | 98000 |
| 5 | PLA | INFINION | 15244 |
| n |
Data set 2
| Obs | Initials |
|---|---|
| 1 | AVG |
| 2 | KLP |
| 3 | QGY |
| 4 | DGY |
| 5 | MNJ |
| n |
Data set 3
| Obs | Initials |
|---|---|
| 1 | PLA |
| 2 | GTX |
| 3 | MLO |
| 4 | BBN |
| n | DYU |
What I am trying to do is to make an random sample of "data set 1".
However, I do not want to include observations with the same initials from data set 2 and 3. Therefore the random sample must not include obs 2 and 5, because their initials occur in data set 2 and 3.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sounds like you are trying to do something like the following:
data initials;
set sample1 sample2 sample3 sample4 sample5 sample6;
run;
proc sql noprint;
select distinct quote(strip(initials))
into :initials separated by ','
from initials
;
quit;
proc surveyselect data=x201202 method=srs n=200 seed=200
out=test005;
where afdeling ne "AgroTech A/S" and
initialer not in (&initials.);
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You might want to read the article "Sample with replacement in SAS" which discusses some of the issues and techniques for sampling with replacement.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
So, what I understand is that you already have samples and you want the new sample to exclude cases already selected. Try this (not tested) :
/* Create a set of existing samples */
data sampSet / view=sampSet;
set xxx.sample:;
keep initials;
run;
/* Create a subset of x201202 excluding existing samples */
proc sql;
create view newSet as
select *
from xxx.X201202
where
initials not in (select initials from sampSet);
quit;
/* Create a new sample from X201202, excluding previous samples */
call surveyselect data=newSet method=srs n=200 seed=200 out=test005;
run;
PG
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
7 replies
-
02-22-2015 09:20 AM
-
3878 views
-
0 likes
-
4 in conversation
-
