- Home
- /
- Programming
- /
- Programming
- /
- Picking subjects with missing visit
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
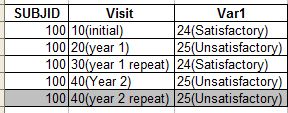
I have a scenario where I need to pick subject who doesn't have a corresponding repeat visit for occurance of an UNSATISFACTORY in Var1. Here in the above example subject 100 has a unsatisfactory for Year 1 visit so he comes in for a repeat visit Year 1 Repeat. But I need to find out subjects who doesn't make it to that repeat visit. I made up a Year 2 Repeat visit as greyed out here as expected record but right now missing in the database table. I can split this dataset into different datasets and somehow find out the missing repeat visit for a UNSATISFACTORY Visit but I would like to know if there is any other efficient way of find this out.
Regards
Bob
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi. I'm not sure that I understand all the possibilities, but given these criteria ...
Per subjid-
for every occurrence of Visit=10 and var1=25 there should be a corresponding Visit=30 row
for every occurrence of Visit=20 and var1=25 there should be a corresponding Visit=40 row
one idea is to use EXCEPT in PROC SQL to find observations in the 1st data set
not present in the 2nd data set (here they are the same data set). The ALL results in
subjid 300 being listed twice in the first query (two occurrences of visit=10, var1=25
and no corresponding visit=40) ...
data x;
input subjid visit var1;
datalines;
100 10 24
100 20 25
100 30 24
200 10 25
200 30 24
300 10 25
300 10 25
300 20 25
400 20 25
400 40 24
;
run;
proc sql;
title "subjects with visit=10, var1=25 and no visit=30";
select subjid from x (where=(visit eq 10 and var1 eq 25))
except all
select subjid from x (where=(visit eq 30));
title "subjects with visit=20, var1=25 and no visit=40";
select subjid from x (where=(visit eq 20 and var1 eq 25))
except all
select subjid from x (where=(visit eq 40));
quit;
You could also merge the data set with itself BY SUBJID (given a sorted data set) ...
data a;
merge x (where=(visit eq 10 and var1 eq 25) in=a) x (where=(visit eq 30) in=b);
if a and ^b;
by subjid;
run;
data b;
merge x (where=(visit eq 20 and var1 eq 25) in=a) x (where=(visit eq 40) in=b);
if a and ^b;
by subjid;
run;
or a hash object (visit_ is the original value of visit in an unmatched observation) ...
data ab;
declare hash h(dataset:'x(where=(visit in (30 40))');
h.defineKey('subjid','visit');
h.defineDone();
do until(done);
set x (where=(visit in (10 20) and var1 eq 25)) end=done;
visit_ = visit;
visit = ifn(visit eq 10, 30, 40);
if h.find() then output;
end;
stop;
drop visit;
run;
etc.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Bob,
I think you'll get the best response if you state your requirements in terms of what your data state. Are your fields for visit coded 10, 20, etc. or do they also include the (description). Same question for var1.
If they include the descriptions, are they in mixed case as shown in your example (e.g., year and Year)?
Regardless, what is your specific requirement. My initial guess would be that your data include both numbers and description and that you want those who have a visit=20(year 1) and var1=25(unsatisfactory) as well as having a visit=40(year 2) and a var1=25(unsatisfactory).
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
First, Visit and Var1 are coded only numeric. NO DESCRIPTION.
Second, Per subjid- for every occurance of Visit=10 and var1=25 there should be a corresponding Visit=30 row and
for every occurance of Visit=20 and var1=25 there should be a corresponding Visit=40 row present in the database table. If this above criteria is missing I want to know.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi. I'm not sure that I understand all the possibilities, but given these criteria ...
Per subjid-
for every occurrence of Visit=10 and var1=25 there should be a corresponding Visit=30 row
for every occurrence of Visit=20 and var1=25 there should be a corresponding Visit=40 row
one idea is to use EXCEPT in PROC SQL to find observations in the 1st data set
not present in the 2nd data set (here they are the same data set). The ALL results in
subjid 300 being listed twice in the first query (two occurrences of visit=10, var1=25
and no corresponding visit=40) ...
data x;
input subjid visit var1;
datalines;
100 10 24
100 20 25
100 30 24
200 10 25
200 30 24
300 10 25
300 10 25
300 20 25
400 20 25
400 40 24
;
run;
proc sql;
title "subjects with visit=10, var1=25 and no visit=30";
select subjid from x (where=(visit eq 10 and var1 eq 25))
except all
select subjid from x (where=(visit eq 30));
title "subjects with visit=20, var1=25 and no visit=40";
select subjid from x (where=(visit eq 20 and var1 eq 25))
except all
select subjid from x (where=(visit eq 40));
quit;
You could also merge the data set with itself BY SUBJID (given a sorted data set) ...
data a;
merge x (where=(visit eq 10 and var1 eq 25) in=a) x (where=(visit eq 30) in=b);
if a and ^b;
by subjid;
run;
data b;
merge x (where=(visit eq 20 and var1 eq 25) in=a) x (where=(visit eq 40) in=b);
if a and ^b;
by subjid;
run;
or a hash object (visit_ is the original value of visit in an unmatched observation) ...
data ab;
declare hash h(dataset:'x(where=(visit in (30 40))');
h.defineKey('subjid','visit');
h.defineDone();
do until(done);
set x (where=(visit in (10 20) and var1 eq 25)) end=done;
visit_ = visit;
visit = ifn(visit eq 10, 30, 40);
if h.find() then output;
end;
stop;
drop visit;
run;
etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Mike-
Perfect. This is what I needed.
Thanks a bunch.
Bob
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
4 replies
-
09-29-2011 05:57 PM
-
4763 views
-
0 likes
-
3 in conversation
-
