- Home
- /
- Programming
- /
- Programming
- /
- Re: MERGE by group possible?
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
we have the following problem:
We would like to add certain observations from the data set TEST to the same data set TEST (thereby creating a new data set TEST2) where these observations to be added fulfill three conditions.
In addition, we would like to see this merge performed several times, i.e., for every group of observations classified by id_group.
Maybe that sounds a bit complicated and/or is not explained very well, so please take a look at the pictures below which should give a better explanation by showing the inital data set and the one we would like to create...
The initial data set TEST looks like:
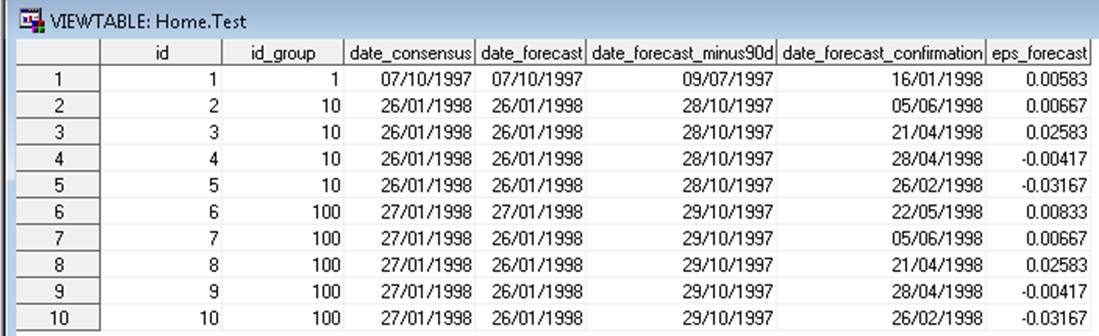
The data set we would like to create should look like:
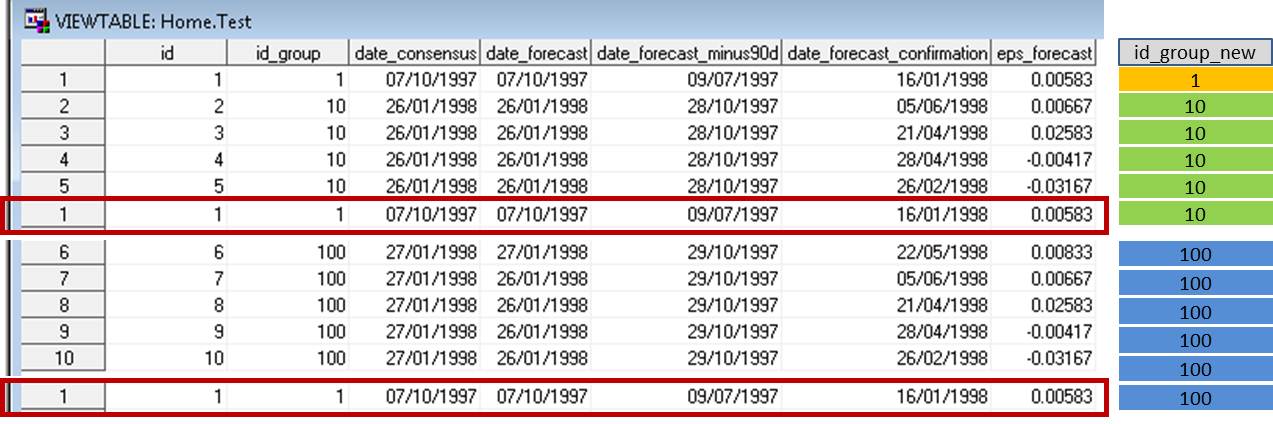
Our preliminary code looks like (not working):
PROC SQL;
CREATE TABLE test2
AS SELECT a.*
FROM test a
LEFT JOIN test b
ON a.date_consensus > b.date_forecast
AND a.date_forecast_minus90d <= b.date_forecast_confirmation
AND a.date_forecast_minus90d >= b.date_forecast
GROUP BY id_group;
QUIT;
I.e., SAS should do the following:
- Match no observation to id_group = 1 because the three conditions are not fulfilled by any of the 10 observations in test b
- Match observation with id = 1 to id_group = 10 as it is the only observation that fulfills:
- a.date_consensus (26.01.1998) > b.date_forecast (07.10.1997)
- a.date_forecast_minus90d (28.10.1997) <= b.date_forecast_confirmation (16.01.1998)
- a.date_forecast_minus90d (28.10.1997) >= b.date_forecast (07.10.1997)
- Match observation with id = 1 to id_group = 100 as it is the only observation that fulfills:
- a.date_consensus (27.01.1998) > b.date_forecast (07.10.1997)
- a.date_forecast_minus90d (29.10.1997) <= b.date_forecast_confirmation (16.01.1998)
- a.date_forecast_minus90d (29.10.1997) >= b.date_forecast (07.10.1997)
Any help or comment is more than appreciated (sorry, we are SAS beginners).
Thank you very much,
Alex and Niklas

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Can you please provide the data in a more usable format, so that I don't have to manually create it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Oh, sorry. I forgot to attach it.
Thanks!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Something like this???
data test_new;
set test;
match = 0;
/* id 10 */
if date_consensus (26.01.1998) > date_forecast (07.10.1997)
and date_forecast_minus90d (28.10.1997) <= date_forecast_confirmation (16.01.1998)
and date_forecast_minus90d (28.10.1997) >= date_forecast (07.10.1997)
then do;
id_group_new = 10;
match=1;
output;
end;
/* id 100 */
if date_consensus (27.01.1998) > date_forecast (07.10.1997)
and date_forecast_minus90d (29.10.1997) <= date_forecast_confirmation (16.01.1998)
and date_forecast_minus90d (29.10.1997) >= date_forecast (07.10.1997)
then do;
id_group_new = 100;
match=1;
output;
end;
/* original post if not met by any condition above */
if match eq 0 then do;
id_group_new = 1;
output;
end;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi FrederikE,
thanks for your effort.
Unfortunately, your code results in the following table:
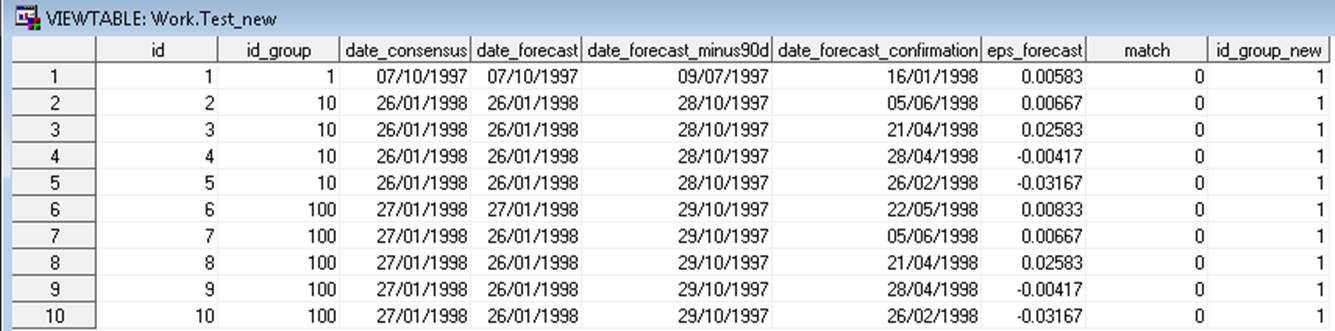
Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
hmm, like this....:)
proc sql;
create table res as select * from
(select *, id_group as id_group_new from kk.test)
union
(
select a.*,b.id_group_new from kk.test as a
inner join
(select *,id as bid,id_group as id_group_new from kk.test where id_group eq 10) as b
ON b.date_consensus > a.date_forecast
AND b.date_forecast_minus90d <= a.date_forecast_confirmation
AND b.date_forecast_minus90d >= a.date_forecast
and a.id_group eq 1
)
union
(
select c.*,d.id_group_new from kk.test as c
inner join
(select *,id_group as id_group_new from kk.test where id_group eq 100) as d
ON d.date_consensus > c.date_forecast
AND d.date_forecast_minus90d <= c.date_forecast_confirmation
AND d.date_forecast_minus90d >= c.date_forecast
and c.id_group eq 1
)
;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I don't think variables matter. The issue is getting a row to repeat, once for each group at the beginning of each group.
I'm thinking a data step with multiple set statements....
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Fredrik,
yeah, that's it (almost)! Thank you very much! ![]()
However, what shall we do if we have like 100,000 id_groups in our FULL sample?
Is it possible to implement some kind of loop/macro?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
This works, though I think there should be a simpler answer...I did have to create an new ID group to merge in with, so you may want to rename them afterwards or drop one.
You could probably simplify it to one bigger SQL query, but I would find that harder to understand personally.
proc sql ;
create table merge1 as
select distinct t1.id_group as id_group, t3.id, t3.id_group as id_group_old, t3.date_consensus, t3.date_forecast, t3.date_forecast_minus90d, t3.date_forecast_confirmation, t3.eps_forecast
from test t1
cross join
(select * from test t2
where t2.id_group=1) t3;
quit;
data merge2;
set test (in=a where=(id_group ne 1)) merge1;
if a then id_group_old=id_group;
run;
proc sort data=merge2;
by id_group id id_group_old;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Reeza,
thanks for sharing your approach, too. Yes, it works. ![]()
However, regarding the fact that we would like to run this code on our FULL sample, I think we will not be able to implement your approach as it requires knowing which ids should be merged to which id_group, i.e., we would have to manually look which ids fulfill our 3 conditions mentioned above for each id_group (... and our FULL sample consists of more than 100,000 id_groups).
Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Maybe loading the dataset into memory can help you (SAS(R) 9.2 Language Reference: Dictionary, Fourth Edition).
It might help whn you read it multiple times....
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for posting the link. We'll work on it.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If I understand the problem right then one of the challenges is to compare "everything with everything" without the need of a Cartesian product. Below is some code attempting to do this.
Based on the sample result you've given I wasn't sure what should happen with cases where you have multiple rows in the same id_group so eventually the code needs some tweaking to return what you're after. I've added a column "Source_Flg" telling whether a row comes from the source or got added based on your rules. That should help you to tell us whether the logic I've used is what you're after or not.
I was also thinking about using hash/hiter objects but as it appears you're dealing with quite a bit of rows you would first need to tell us how big your source data set is (uncompressed) and how much memory you've got available.
In the "Do Loop" section of the code the source data set gets read multiple times. As FrederikE suggested I've loaded the source data set into memory. If you haven't got enough memory then remove the "SASFILE" statements.
How much difference it makes whether the source data set is loaded into memory or not will depend on how the disk where you're source data set lives is attached to the server and how the disk caching options are set for this disk. If performance is "bad" then it's eventually worth to first copy the data set to "WORK" as the SAS work area is normally pointing to a storage area with throughput as good as available.
And here what I could come up with:
libname test 'C:\Tests';
SASFILE test.test load ;
data want(drop=_:);
length Source_flg 8;
length id_group_new 8;
set test.test nobs=_stop;
Source_flg=1;
id_group_new=id_group;
output;
Source_flg=0;
if _n_=1 then
do;
if 0 then _id_group=id_group;
dcl hash h (hashexp:5);
_rc=h.defineKey('_id_group');
_rc=h.defineDone();
end;
_start=_n_+1;
do _i=_start to _stop;
set test.test
(
keep=id_group date_consensus date_forecast_minus90d date_forecast_confirmation
rename=(id_group=_id_group date_consensus=_date_consensus date_forecast_minus90d=_date_forecast_minus90d date_forecast_confirmation=_date_forecast_confirmation)
)
point=_i
;
if h.check()=0 then continue;
if id_group = _id_group then
do;
h.add();
continue;
end;
if _date_consensus > date_forecast
and _date_forecast_minus90d <= date_forecast_confirmation
and _date_forecast_minus90d >= date_forecast
then;
do;
_rc=h.add();
id_group_new=_id_group;
output;
end;
end;
_rc=h.clear();
run;
SASFILE test.test close ;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Patrick,
thank you!
I will respond to your post ASAP.
We will try your approach on our full sample and see if it works.
Regards,
Alex
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Please verify first that the result from the code I've posted is what you're after before running it over the full sample.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
18 replies
-
10-17-2013 06:06 AM
-
7470 views
-
0 likes
-
6 in conversation
-
