- Home
- /
- Programming
- /
- Programming
- /
- How to keep IDs available in each year
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
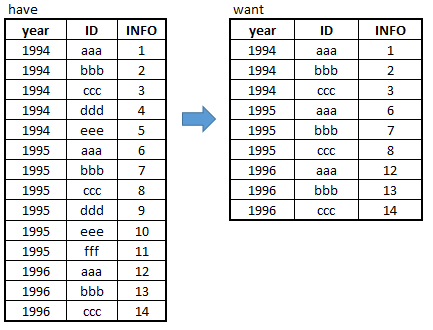
I have unbalanced panel data as showed below, there are many years and many IDs, and I want to keep those IDs available in each year, how to achieve that?
* I realized that my sample data set is too simple, which is kind of misleading. So I attached real data set below. Again, thank you guys for your help!
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That's because in our real sample {year, id} is not the primary composite key so condition "having count(id) = (select count(distinct year) from source.sample)" is not true.
Below code should deal with your real sample:
libname source "C:\test";
proc sql noprint;
create table want as
select *
from source.realsample
group by id
having count(distinct year) = (select count(distinct year) from source.realsample)
order by year, id
;
quit;
Message was edited by: Patrick Matter
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If {year, id} also makes up the composite primary key in your real data then some code as below should work:
libname source "C:\test";
proc sql;
create table want as
select *
from source.sample
group by id
having count(id) = (select count(distinct year) from source.sample)
order by year, id
;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Patrick for your reply. The code works well for the simple data I attached. I don't know why it doesn't work for my real data. When I apply the code to real data, the resulting dataset contains no observation. I have attached real sample in my post.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That's because in our real sample {year, id} is not the primary composite key so condition "having count(id) = (select count(distinct year) from source.sample)" is not true.
Below code should deal with your real sample:
libname source "C:\test";
proc sql noprint;
create table want as
select *
from source.realsample
group by id
having count(distinct year) = (select count(distinct year) from source.realsample)
order by year, id
;
quit;
Message was edited by: Patrick Matter
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I am not sure how to fix that problem. I tried to reorder the variables in the data set, still no observations in the result. Really appreciate your help.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
See above. I've added code which should work with your "realsample" data.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That works great! Many thanks, Patrick!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
proc sql;
select * from sample where id in (select id from sample group by id having count(year)>=3);
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Sichen. I tried your code with real data, the result contains IDs which only have observations in one year but not the other two years, for example, id=31656 (real sample is in my post). Since Patric's code also doesn't work for my data set, now I am wondering if it is my data set's problem..
.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data want(drop=n);
set data;
by year id;
if first.year then n=1;
else n+1;
if n<4;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I realized that my sample dataset is too simple, so I have updated real data set in the post. Thank you, stat@sas!
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
10 replies
-
05-22-2014 06:21 PM
-
3163 views
-
0 likes
-
4 in conversation
-
