- Home
- /
- Programming
- /
- SAS Procedures
- /
- "fill out" or expand a dataset
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Does anyone know a way to "fill out" a dataset with values from a second dataset using merge or set or other simple statements? For example, I might have one dataset as:
letter num
a .
b .
c .
And a second datset:
num
1
2
3
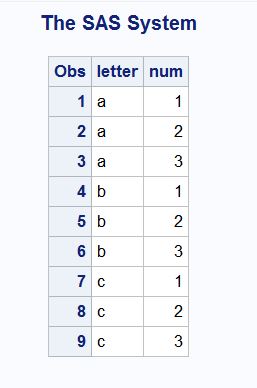
I need the resulting dataset to look like:
letter num
a 1
a 2
a 3
b 1
b 2
b 3
c 1
c 2
c 3
I really don't want to use an array. Thanks for any ideas!
Jon
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
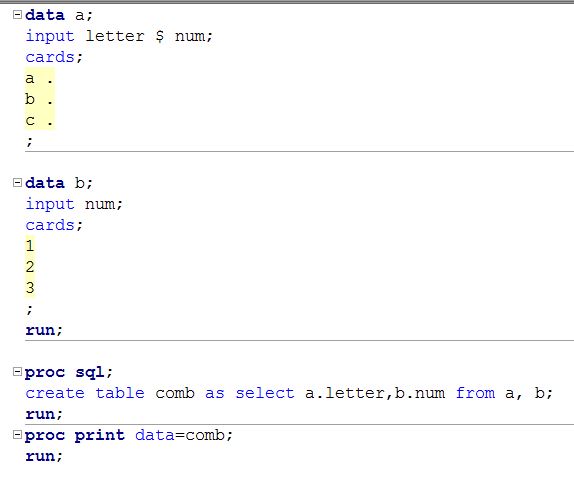
proc sql;
create table want as
select letter,set2.num
from set1,set2;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
proc sql;
create table ab as
select letter, coalesce(a.num, b.num)
from a,b;
select * from ab;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I really think the sql-version is an option here. But this might work as well, if the number of observations to fill out is fixed:
Data A;
Input Letter $ @@;
Call Missing (Num);
Datalines;
a b c
;
Run;
Data B;
Input Num @@;
Datalines;
1 2 3
;
Run;
Data Want;
Set A;
By Letter;
If First.Letter Then Do;
i=0;
Set B Nobs=MaxNum;
Do Until (i=MaxNum);
i=i+1;
Set B Point=i;
Output;
End;
End;
Run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
data master;
input letter $ num;
datalines;
a .
b .
c .
x .
y .
z .
;
data trans;
input num;
datalines;
1
2
3
;
data want;
do until(ltrans);
i+1;
set trans end=ltrans;
call symput('var'||put(i,1.), put(num, 1.));
end;
do until(lmaster);
j+1;
set master end=lmaster;
if mod(j,3)=1 then num=symget('var1');
else if mod(j,3)=2 then num=symget('var2');
else if mod(j,3)=0 then num=symget('var3');
output;
end;
stop;
drop i j;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Output
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
5 replies
-
11-02-2014 03:40 PM
-
3979 views
-
6 likes
-
6 in conversation
-
