- Home
- /
- Programming
- /
- SAS Procedures
- /
- identifying incomplete observations
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
I have a specific problem which I'm not sure how to solve. Suppose I have the following data called all.all:
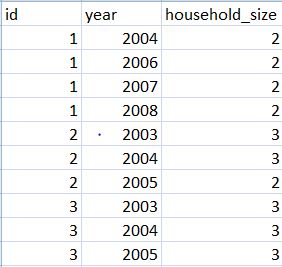
I want to identify id's such as id 3. Eventually, I need to create a data subset that includes id's that:
1. do not have a change in household_size over years (e.g., id 2 had household_size change between 2004 and 2005.)
2. do nto have a gap year (e.g., id 1 is missing 2005)
Thanks,
Chris

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is one way:
proc sql noprint;
create table want1 as
select *
from have (where=(year in (2004, 2005)))
group by id
having min(household_size) eq
max(household_size) and
count(*) eq 2
;
create table want2 as
select *
from have
group by id
having max(year)-min(year)+1 eq
count(*)
;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data want ;
yeargap = 0;
sizechange=0;
do until (last.id) ;
set have ;
by id ;
yeargap = max(yeargap , year ne lag(year) and not first.id);
sizechange = max(sizechange, size ne lag(size) and not first.id);
end;
keep id yeargap sizechange;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
How about:
data temp; input id year household_size; cards; 1 2004 2 1 2006 2 1 2007 2 1 2008 2 2 2003 3 2 2004 3 2 2005 2 3 2003 3 3 2004 3 3 2005 3 ; run; proc sql noprint; create table want as select * from temp group by id having count(distinct household_size) eq 1 and range(year) eq count(year)-1; quit;
Ksharp
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
3 replies
-
09-25-2011 03:38 PM
-
2030 views
-
0 likes
-
4 in conversation
-
