- Home
- /
- Programming
- /
- SAS Procedures
- /
- how to stitch many datasets together
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi, I have a large task... This may be a 2 step process. I have 2 large datasets with about 3 by variables and Price. They're both time-series data, where one (Data1) goes as far back as 15 years and the second (Data2) only 5 years back. One of the problem is that the By varaibles (eg, Stores) some start further eg.6 years and some 4 years in Data2... Step1 - I would like to delete the first 6 months of Data2 (because of rolling averages) and the Step 2- STITCH where the period of the Data2 ended with the furthest data from Data1.
Sample Data1:
Store Date Price Product
A 2000.01 234 A1
A 2000.02 246 A1
A 2000.03 258 A1
B 2000.01 564 B2
B 2000.02 534 B2
B 2000.03 533 B2
B 2000.01 345 B1
B 2000.02 354 B1
Sample Data2: similar to Data1 but later start dates by Product and Store.. to stitch Data2 after I delete the first 6 months (in the sample 1 month)..
Is this possible ?
thanks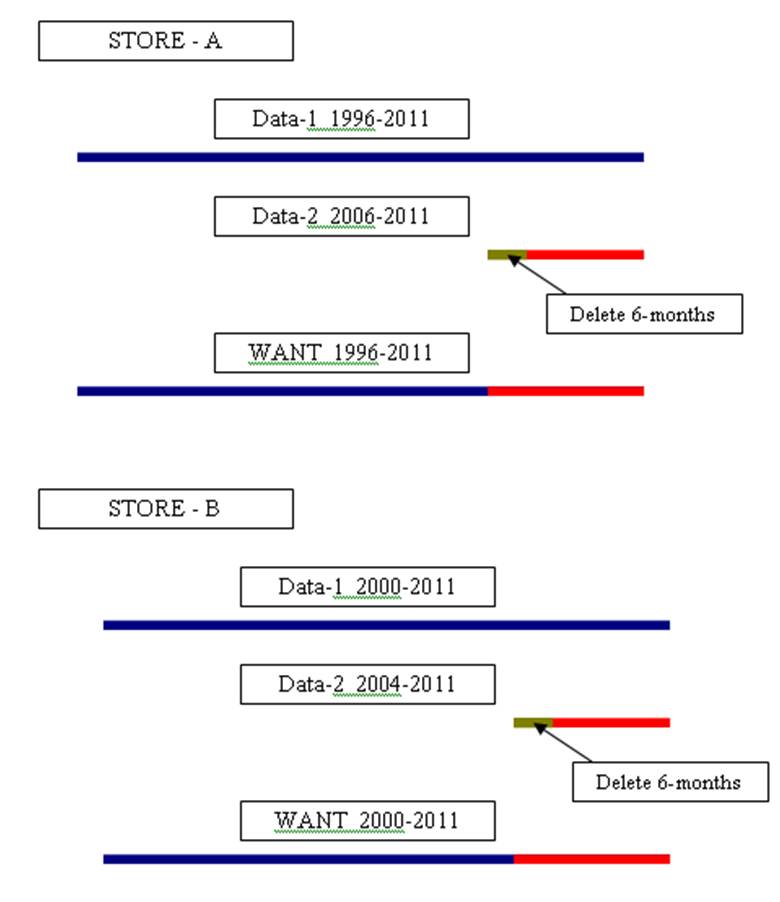

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Not sure if I understood your requirement 100% but I believe a SQL UNION CORR would give you what you're after.
If there are overlapping rows (duplicates) coming from the 2 data sets then UNION CORR will fold them together - in case you want to keep such duplicates then use OUTER UNION CORR.
data Set1;
input Store $ DateC $ Price Product $;
format date date9.;
date=input(compress(DateC,'.'),yymmn6.);
datalines;
A 2000.01 234 A1
A 2000.02 246 A1
A 2000.03 258 A1
B 2000.01 564 B2
B 2000.02 534 B2
B 2000.03 533 B2
B 2000.01 345 B1
B 2000.02 354 B1
;
run;
data Set2;
set Set1;
date=intnx('month',date,2,'s');
run;
proc sql;
select *
from set1
union corr
select *
from set2
where date>'01Mar2000'd
order by Store,Date
;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Patrick.. eager to try it.. but I'm not sure I understand what you mean by if they are overlapping rows or keep duplicates.. Data1 and Data2 will 'stitch' only if they have matching stores and products.. so they have to match.. but I just thought of another approach... if there is a way to detect the earlies dates in Data2, delete the first 6 months , and then merge Data1 and Data2 by Store and Product, only is the dates don't match... would that approach work.. given that Data2 has 1000 sores and Data1 300.. There may be some stores that belong to Data1 and not Data2, I have no idea how SAS would treat those.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
As I understood your requirement it's actually more about concatenating than merging 2 data sets (=horizontal vs vertical combination).
Below link explains much better than I ever could how UNION works
http://support.sas.com/documentation/cdl/en/sqlproc/62086/HTML/default/viewer.htm#a001361224.htm
I don't really understand what this "delete the first 6 months" is about. Do you just need a combined time series without gaps? And would that be per store or store/product or overall?
"are overlapping rows or keep duplicates"
I don't know your data. Just thinking that if there should be an entry in both datasets for exactly the same date, store and product then you might want to add it only once to your target table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The first 6 months of Data2 is a 6-month rolling average that I don't want. So Data1 has 15 years of Pricing info for 300 stores and 5 products (1996 to 2011 by month).. Data2 has different prices for the same 300 stores +another 700 stores..but depending on the product and store some series might start in 2009 or 2008 or 2007, etc. So I want to merge the better data from Data2 from 2011 up to whenever the earliest month is (minus the last 6-months for the rolling reason) with all the info from Data1 by Store and product, but only up to the earliest date in Data2.. This is more of a matching data by the proper store/product to different points in time.. I know it's a bit confusing, but I'm sure there is a simple way of doing it, I just can't think of it right now.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
So is this "last 6 months" per store and product, or per store, or over the whole dataset. Just trying to figure out (logically) what removing 6 months means.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The outside company that gave me the dataset (Dataset2) has set the prices at rolling 6-month averages. But the first 5 months of every Store and Product, shows spikes because they were not able to do a 6-month rolling average for those.. so I want to delete any FIRST 6-months of every series of Store/Product from Dataset2. But I also have another Dataset1, that goes back futher than the Dataset2 dates and I just want to use it's earlier values that I don't have in Dataset2.. For example from 1996 to 2005 use dates/prices by eg. Store=A / Product=A1 from Dataset1 and from 2005 to 2011 use dates/prices from Dataset2.. Now for Store=B / Product B2 the dates might start differently, like Dataset2 may go as far back as 2003 to 2011 and so I would use the Dataset1 dates/prices from 1996 to 2003 and from Dataset2 2003 to 2011.. each product and store my have different end-start dates for Dataset2... I need to fina an automatic process that simplifies and stitches these 2 datasets at different point in times, dependable on the Store/Product and it's availabilities on the dates they have.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
O.K: I hope I understood now what you have and what you want. If not then I hope that below code gives you at least the idea of how to tackle your challenge.
I've used a coalesce() function for cases where there are data for the same month, store and product in both data sets (just in case this is possible).
If this happens then the price information from DS2 will be taken (unless it is missing).
Make sure that you have only one row per month, store and product in your source data sets (=check data quality).
The SQL code is written for source data stored as SAS data sets.
In case your tables are stored in a DB like Oracle then the SQL code needs some changes (for performance reasons).
data DS1;
input Store $ DateC $ Price Product $;
format date date9.;
date=input(compress(DateC,'.'),yymmn6.);
datalines;
A 2000.01 234 A1
A 2000.02 246 A1
A 2000.03 258 A1
B 2000.01 564 B2
B 2000.02 534 B2
B 2000.03 533 B2
B 2000.01 345 B1
B 2000.02 354 B1
C 2000.07 111 A1
C 2000.08 222 A1
C 2000.09 333 A1
C 2000.10 444 A1
C 2000.11 555 A1
;
run;
data DS2;
set DS1;
date=intnx('month',date,2,'s');
run;
%let N_months_to_exclude=1; /* exclude the first N months in DS2 per store and product */
proc sql;
create view V_DS2 as
select *,min(date) as min_date format=date9.
from DS2
group by store,product
having date>=intnx('month',min(date),&N_months_to_exclude,'s')
;
quit;
proc sql;
select
case when(r.date ne .) then 'DS2' else 'DS1' end as Source,
coalesce(r.date,l.date) format=date9. as date,
coalesce(r.store,l.store) as store,
coalesce(r.product,l.product) as product,
coalesce(r.Price,l.Price) as Price
from
DS1 l
full outer join
V_DS2 r
on l.date=r.date and l.store=r.store and l.product=r.product
order by store,product,date
;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Patrick, I will give it a try and post.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Patrick, finally tried the code and it looks like if there is a date that is shared by both it takes the DS1 data. I need it to take the DS2 data... the Price for these 2 tables will most likely be different even for the same product/Store and Date..
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Please look up how the coalesce() function works. It will show you that in the code I've posted the price of DS1 will only be selected (for matching rows) where DS2.price is missing.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
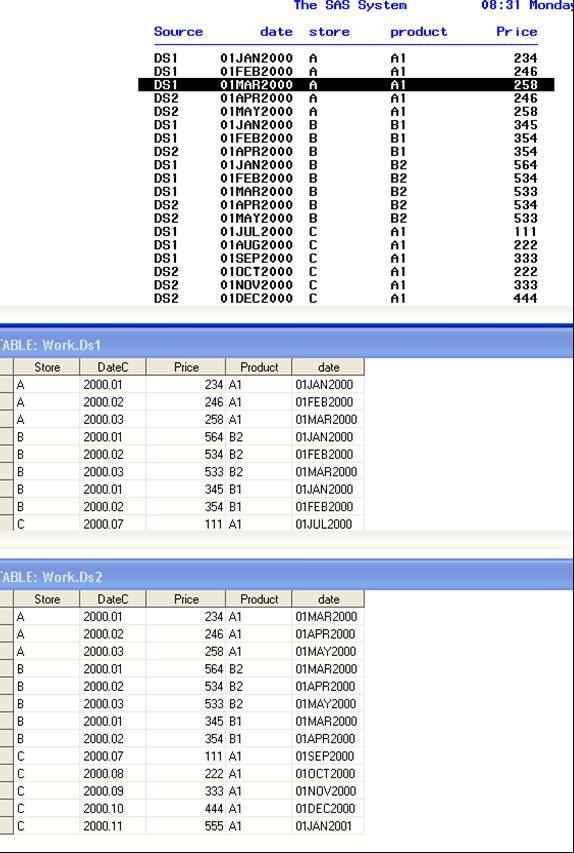
HI Patrick, after running your code, I noticed that in case of a duplicated month, it take the DS1, rather than DS2. or am I missing something.. Please take a look at the pciture. I highlighted the observation that is taking DS1 (258) when it should have the DS2 (234) .. Thanks
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
11 replies
-
02-29-2012 04:46 PM
-
4598 views
-
0 likes
-
2 in conversation
-
