- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: how to add rows when there is missing obs.
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
A sample from the dataset attached below. There are some missing month by each ID number(Table1. before). I want to add rows of missing month per each ID(Table2.after). Since I am having more than 30000 IDs, it seems hard to add rows one by one. Is there anyone who have an idea? Thank you in advance.
Table1. before. (what I have now)
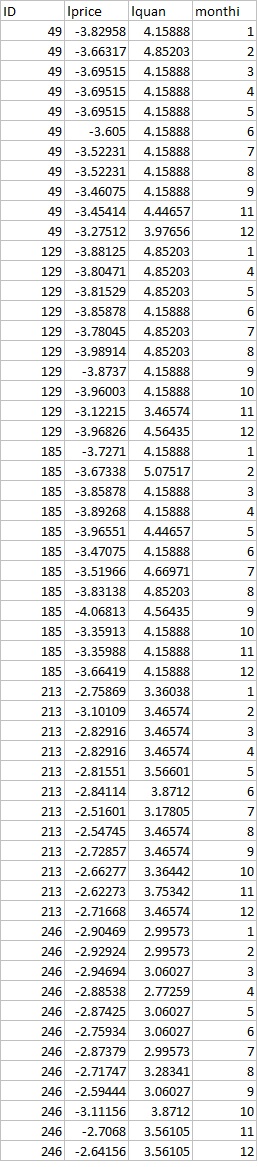
Table2. after (what I want to see)
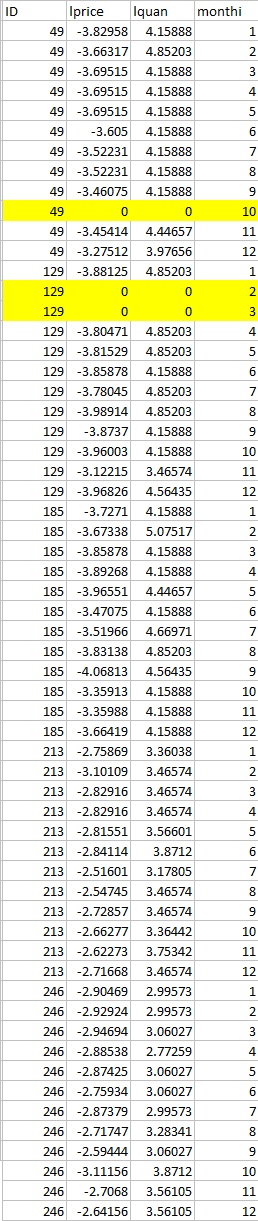
Miyoung
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I would do a cartesian join to get all the combination on months and id... so something like this? Probably not the most efficient though!
data test;
infile datalines dlm=',' dsd missover;
input id : 8.
month : 8.
value : 8.
;
datalines;
1,1,23
1,2,334
1,3,25
2,1,45
2,3,450
;
run;
proc sql;
create table unique_months as
select distinct month
from test
;
quit;
proc sql;
create table unique_id as
select distinct id
from test
;
quit;
proc sql;
create table cartesian as
select i.id,
m.month
from unique_id i,
unique_months m
;
quit;
proc sql;
create table final as
select c.id,
c.month,
t.value
from cartesian c
left join test t
on c.id = t.id
and c.month=t.month
;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
try:
data have;
input id month ;
something=30;
cards;
1 1
1 2
1 3
1 4
1 5
1 6
1 8
1 10
1 12
2 1
2 2
2 3
2 4
2 5
2 7
2 8
2 10
2 12
;
proc sort data=have out=temp(keep=id) nodupkey;
by id;
data temp;
set temp;
something=0;
do month=1 to 12;
output;
end;
run;
data want;
merge temp have;
by id month ;
run;
proc print;run;
Linlin
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks much! I like this short answer!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I would do a cartesian join to get all the combination on months and id... so something like this? Probably not the most efficient though!
data test;
infile datalines dlm=',' dsd missover;
input id : 8.
month : 8.
value : 8.
;
datalines;
1,1,23
1,2,334
1,3,25
2,1,45
2,3,450
;
run;
proc sql;
create table unique_months as
select distinct month
from test
;
quit;
proc sql;
create table unique_id as
select distinct id
from test
;
quit;
proc sql;
create table cartesian as
select i.id,
m.month
from unique_id i,
unique_months m
;
quit;
proc sql;
create table final as
select c.id,
c.month,
t.value
from cartesian c
left join test t
on c.id = t.id
and c.month=t.month
;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It was very helpful. Thank you very much for your time!!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
@PaulLee: Your solution has a drawback when all ids are missing one or more months. You will only get the months tthat exist in the data. You should create all 12 months instead.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes, you are very correct! Creating the months using dataline statement would have been better. Thanks.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
My solution is basically the same as Paul Lee's.
data months (keep=monthi);
do monthi = 1 to 12;
output;
end;
run;
proc sql;
create table IDs as
select distinct ID
from original_dataset;
create table cartesian as
select
a.ID,
b.monthi
from
IDs as a,
months as b;
create table new_dataset as
select
a.ID,
a.lprice,
a.lquan,
b.monthi
from
original_dataset as a
right join
cartesian as b
on
a.ID = b.ID and
a.monthi = b.monthi;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for your time. It helped!!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is an alternative, without merging or joining, just assuming the original data is ordered by id and monthi. This solution requires only one pass though the data set.
I generated similarly structured data with just one variable, then deleted few rows to create gaps.
data old;
do id=49,129,185;
do monthi=1 to 12;
lprice=-3-ranuni(0);
output;
end;
end;
run;
data oldmiss;
set old;
if id=49 and monthi=10 then delete;
if id=129 and monthi in (2,3) then delete;
if id=185 and monthi in (5,6,7,8) then delete;
run;
proc print data=oldmiss;
title "Original raw data with month gaps";
run;
*Original raw data with month gaps
Obs id monthi lprice
1 49 1 -3.94038
2 49 2 -3.43387
3 49 3 -3.99733
4 49 4 -3.43186
5 49 5 -3.02512
6 49 6 -3.34443
7 49 7 -3.28744
8 49 8 -3.62029
9 49 9 -3.85440
10 49 11 -3.74302
11 49 12 -3.62365
12 129 1 -3.83959
13 129 4 -3.32539
14 129 5 -3.97315
15 129 6 -3.38563
16 129 7 -3.04920
17 129 8 -3.39072
18 129 9 -3.38264
19 129 10 -3.00922
20 129 11 -3.08115
21 129 12 -3.54783
22 185 1 -3.66660
23 185 2 -3.55456
24 185 3 -3.49099
25 185 4 -3.60728
26 185 9 -3.22515
27 185 10 -3.67814
28 185 11 -3.50221
29 185 12 -3.79233 ;
data new;
set oldmiss;
by id monthi;
if _N_=1 or first.id then do;
month=1;
end;
else do;
month+1;
end;
if month<monthi then do;
lprice_hold=lprice;
monthi_hold=monthi;
do i=1 to monthi-month;
lprice=0; monthi=month;
output;
month=month+1;
end;
lprice=lprice_hold;
monthi=monthi_hold;
output;
end;
else output;
drop i monthi_hold lprice_hold month;
run;
proc print data=new;
title "Filled in data with no month gaps";
format lprice best8.;
run;
*Filled in data with no month gaps
Obs id monthi lprice
1 49 1 -3.94038
2 49 2 -3.43387
3 49 3 -3.99733
4 49 4 -3.43186
5 49 5 -3.02512
6 49 6 -3.34443
7 49 7 -3.28744
8 49 8 -3.62029
9 49 9 -3.8544
10 49 10 0
11 49 11 -3.74302
12 49 12 -3.62365
13 129 1 -3.83959
14 129 2 0
15 129 3 0
16 129 4 -3.32539
17 129 5 -3.97315
18 129 6 -3.38563
19 129 7 -3.0492
20 129 8 -3.39072
21 129 9 -3.38264
22 129 10 -3.00922
23 129 11 -3.08115
24 129 12 -3.54783
25 185 1 -3.6666
26 185 2 -3.55456
27 185 3 -3.49099
28 185 4 -3.60728
29 185 5 0
30 185 6 0
31 185 7 0
32 185 8 0
33 185 9 -3.22515
34 185 10 -3.67814
35 185 11 -3.50221
36 185 12 -3.79233
;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
9 replies
-
07-18-2012 02:16 PM
-
8672 views
-
13 likes
-
5 in conversation
-
