- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: creating additional columns with proc sql
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
would like to create additional columns with dataset like the following:
| club | name | GPA | City |
|---|---|---|---|
| SAS | Kent | 3.0 | LA |
| tennis | Lisa | 4.0 | NY |
| basketball | Steve | 2.9 | NJ |
| SAS | Steve | 2.9 | NJ |
| SAS | Abbie | 3.2 | NJ |
| basketball | George | 3.1 | NY |
| tennis | George | 3.1 | NY |
want the result to look like the following: ( the very last row to have a count of all the members in a particular club)
| member info | SAS | tennis | basketball |
|---|---|---|---|
name Kent GPA 3.0 City LA | X | ||
name Lisa GPA 4.0 city NY | X | ||
name Steve GPA 2.9 city NJ | X | X | |
name Abbie GPA 3.2 City NJ | X | ||
name George GPA 3.1 City NY | X | X | |
| total | 3 | 2 | 2 |
it is possible to create clubs columns SAS, basketball, tennis individually, but what is the best way to create additional club columns using proc sql or other proc methods? thanks.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is a quick and simple example using PROC TRANSPOSE to convert the CLUB values into variables.
I had to introduce a dummy variable to give PROC TRANSPOSE something to put into the variables it created.
Not sure why you would want to merge the other three variables into one, but you can use on of the CATX functions to do that if you want.
data have ;
length club $30 name $20 gpa 8 city $8 ;
input club -- city;
dummy=1;
cards;
SAS Kent 3.0 LA
tennis Lisa 4.0 NY
basketball Steve 2.9 NJ
SAS Abbie 3.2 NJ
basketball George 3.1 NY
run;
proc transpose data=have out=want (drop=_name_) ;
by name gpa city notsorted ;
id club;
var dummy;
run;
proc print ;
var _all_;
sum _numeric_;
run;
Obs name gpa city SAS tennis basketball
1 Kent 3.0 LA 1 . .
2 Lisa 4.0 NY . 1 .
3 Steve 2.9 NJ . . 1
4 Abbie 3.2 NJ 1 . .
5 George 3.1 NY . . 1
==== === ====== ==========
16.2 2 1 2
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Perhaps you can re-post or edit to make it readable?
Did you mean that you want a column (variable) for each club with a flag to indicate if the person represented by the current row (observation) is a member of that club? Is it possible for the person to be a member of more than one club? If so then should that person always have the same values GPA and CITY?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
yes, I want to have one column for each club with a flag if a person belongs to that club as you described. and it's possible that a person belongs to more than one club.
and want to keep the GPA and City in the same column as name is in. so what it looks like above is exactly what it's needed.
I think db2 sql has a way to put name, GPA and CITy into the same column, but not sure how to extend the table so it has the club membership info to the right.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is a quick and simple example using PROC TRANSPOSE to convert the CLUB values into variables.
I had to introduce a dummy variable to give PROC TRANSPOSE something to put into the variables it created.
Not sure why you would want to merge the other three variables into one, but you can use on of the CATX functions to do that if you want.
data have ;
length club $30 name $20 gpa 8 city $8 ;
input club -- city;
dummy=1;
cards;
SAS Kent 3.0 LA
tennis Lisa 4.0 NY
basketball Steve 2.9 NJ
SAS Abbie 3.2 NJ
basketball George 3.1 NY
run;
proc transpose data=have out=want (drop=_name_) ;
by name gpa city notsorted ;
id club;
var dummy;
run;
proc print ;
var _all_;
sum _numeric_;
run;
Obs name gpa city SAS tennis basketball
1 Kent 3.0 LA 1 . .
2 Lisa 4.0 NY . 1 .
3 Steve 2.9 NJ . . 1
4 Abbie 3.2 NJ 1 . .
5 George 3.1 NY . . 1
==== === ====== ==========
16.2 2 1 2
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
if Kent belongs to both SAS and tennis clubs, and there is another observation such as the following, can Kent have a value of 1 under tennis, too? don't have to merge name, gpa and city into one cell.
cards;
SAS Kent 3.0 LA
tennis Kent 3.0 LA
tennis Lisa 4.0 NY
basketball Steve 2.9 NJ
SAS Abbie 3.2 NJ
basketball George 3.1 NY
want to have:
Obs name gpa city SAS tennis basketball
1 Kent 3.0 LA 1 1 .
2 Lisa 4.0 NY . 1 .
3 Steve 2.9 NJ . . 1
4 Abbie 3.2 NJ 1 . .
5 George 3.1 NY . . 1
==== === ====== ==========
16.2 2 2 2

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
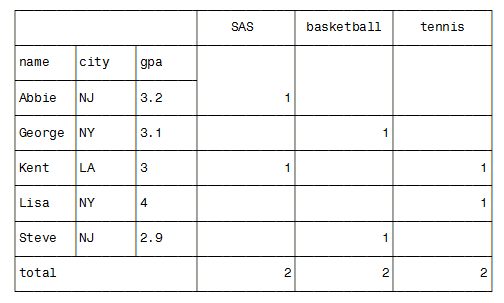
Or you could use this :
options missing="";
proc tabulate data=have;
class name city club gpa;
table name*city*gpa*format=3.1 all="total", club=""*n=""*format=12.;
run;
and get this :
PG
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
5 replies
-
04-25-2012 01:52 PM
-
3743 views
-
3 likes
-
3 in conversation
-
