- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Using maximum likelihood to estimate parameter of generalized pare...
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
I'm trying to fit my precipitation data to a generalized pareto distribution and find the 95th percentile . And of the three parameters in generalized pareto distribution (sigma, mu, and xi), sigma and mu are fixed, parameter xi is unknown.
I'm considering to use maximum likelihood to estimate xi of generalized pareto distribution, but I don't know what procedure should I use.
I tried the "proc nlin":
proc nlin data= have;
parameters kai=1;
model F=(1/sigma)*((1+xi*((Prep-mu)/sigma)**(-1-1/xi)));
run;
Prep as the precipitation samples, F as corresponding frequencies (probabilities), mu and sigma are fixed parameters. But under proc nlin, the estimation methods I could choose don't include maximum likelihood.
Anyone has any ideas about using maximum likelihood to estimate xi in generalized pareto distribution?
Or if there has any other method to fit my data to a generalized pareto distribution with fixed mu and sigma and get the parameter xi and get the percentile?
I will really appreciate if there has any ideas or thoughts from you all!
Regards,
Hua
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
> 1. I could get the parameters now, but did not see where is the percentile. And don't know how to output them in a new table(dataset).
You didn't specify the SIGMA= value. You originally said that the threshold and scale parameters are fixed.
You can use the ODS OUTPUT statement to create a data set from any SAS table. The FitQuantiles table contains the results of the PERCENT= option, but the table will only appear if the MLE for the Pareto distribution converges. Here is an example that generates the tables and saves the estimates:
ods trace on;
proc univariate data=sashelp.cars;
where EngineSize>3;
var enginesize;
histogram enginesize / pareto(theta=2.9 sigma=1.5 percents=(5 95));
ods output ParameterEstimates=PE FitQuantiles=FQ;
ods select Histogram ParameterEstimates FitQuantiles GoodnessOfFit;
run;
ods trace off;
> 2. Since I have a lot of groups with different parameters, it's not possible to manually write every corresponding parameter in each code. And I tried but it seems like I could not use one variable in the dataset as a parameter in the code. What I means is : I add a column named "a" in dataset "have", and use THETA=a in the pareto options.
I don't think PROC UNIVARIATE supports an option like that.
> 3. Do you know how can I define :
-
 width of histogram interval
width of histogram interval -
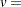 vertical scaling factor
vertical scaling factor
You don't need to worry about those parameters. They appear in the formula for a mathematical reason (so that the density integrates to 1 on whatever vertical scale is being used.) PROC UNIVARIATE handles those values automatically.
> 4. How can I know that how does the data fit the distribution, like R2, how to evaluate this fitting.
Look at the GoodnessOfFit table, which provides GOF statistics such as Kolmogorov-Smirnov and Anderson-Darling tests.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Proc univariate fits generalized Pareto distributions with the histogram statement. Check the PARETO and PERCENTS options.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
@PGStats wrote:
Proc univariate fits generalized Pareto distributions with the histogram statement. Check the PARETO and PERCENTS options.
Thank you for giving ideas that using proc univariate, I viewed the SAS Procedures Guide about proc univariate, and used following code:
proc univariate data=have;
histogram Prep/ pareto(THETA= 3 PERCENT=0.95);
ods select histogram;
run;
But I still have some questions:
1. I could get the parameters now, but did not see where is the percentile. And don't know how to output them in a new table(dataset).
2. Since I have a lot of groups with different parameters, it's not possible to manually write every corresponding parameter in each code. And I tried but it seems like I could not use one variable in the dataset as a parameter in the code. What I means is : I add a column named "a" in dataset "have", and use THETA=a in the pareto options.
3. Do you know how can I define :
-
width of histogram interval
-
vertical scaling factor
these two parameters? It seems like the histogram I get from the code is automatically have an interval? Where should I define them?
4. How can I know that how does the data fit the distribution, like R2, how to evaluate this fitting.
Really thank you for help! It helped me a lot!
Best,
Hua
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
As @PGStats says, PROC UNIVARIATE can fit the generalized Pareto distribution. However, to address your question, you can use PROC NLMIXED (without a random component) to fit data using MLE. For details and an example, see "Two ways to compute maximum likelihood estimates in SAS."
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
> 1. I could get the parameters now, but did not see where is the percentile. And don't know how to output them in a new table(dataset).
You didn't specify the SIGMA= value. You originally said that the threshold and scale parameters are fixed.
You can use the ODS OUTPUT statement to create a data set from any SAS table. The FitQuantiles table contains the results of the PERCENT= option, but the table will only appear if the MLE for the Pareto distribution converges. Here is an example that generates the tables and saves the estimates:
ods trace on;
proc univariate data=sashelp.cars;
where EngineSize>3;
var enginesize;
histogram enginesize / pareto(theta=2.9 sigma=1.5 percents=(5 95));
ods output ParameterEstimates=PE FitQuantiles=FQ;
ods select Histogram ParameterEstimates FitQuantiles GoodnessOfFit;
run;
ods trace off;
> 2. Since I have a lot of groups with different parameters, it's not possible to manually write every corresponding parameter in each code. And I tried but it seems like I could not use one variable in the dataset as a parameter in the code. What I means is : I add a column named "a" in dataset "have", and use THETA=a in the pareto options.
I don't think PROC UNIVARIATE supports an option like that.
> 3. Do you know how can I define :
-
width of histogram interval
-
vertical scaling factor
You don't need to worry about those parameters. They appear in the formula for a mathematical reason (so that the density integrates to 1 on whatever vertical scale is being used.) PROC UNIVARIATE handles those values automatically.
> 4. How can I know that how does the data fit the distribution, like R2, how to evaluate this fitting.
Look at the GoodnessOfFit table, which provides GOF statistics such as Kolmogorov-Smirnov and Anderson-Darling tests.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
@Rick_SAS wrote:
> 1. I could get the parameters now, but did not see where is the percentile. And don't know how to output them in a new table(dataset).
You didn't specify the SIGMA= value. You originally said that the threshold and scale parameters are fixed.
You can use the ODS OUTPUT statement to create a data set from any SAS table. The FitQuantiles table contains the results of the PERCENT= option, but the table will only appear if the MLE for the Pareto distribution converges. Here is an example that generates the tables and saves the estimates:
ods trace on; proc univariate data=sashelp.cars; where EngineSize>3; var enginesize; histogram enginesize / pareto(theta=2.9 sigma=1.5 percents=(5 95)); ods output ParameterEstimates=PE FitQuantiles=FQ; ods select Histogram ParameterEstimates FitQuantiles GoodnessOfFit; run; ods trace off;
> 2. Since I have a lot of groups with different parameters, it's not possible to manually write every corresponding parameter in each code. And I tried but it seems like I could not use one variable in the dataset as a parameter in the code. What I means is : I add a column named "a" in dataset "have", and use THETA=a in the pareto options.
I don't think PROC UNIVARIATE supports an option like that.
> 3. Do you know how can I define :
You don't need to worry about those parameters. They appear in the formula for a mathematical reason (so that the density integrates to 1 on whatever vertical scale is being used.) PROC UNIVARIATE handles those values automatically.
> 4. How can I know that how does the data fit the distribution, like R2, how to evaluate this fitting.
Look at the GoodnessOfFit table, which provides GOF statistics such as Kolmogorov-Smirnov and Anderson-Darling tests.
Thank you so much for your answer. It's very helpful for me. And I'm still reading the website you provided about PROC NLMIXED, hope it can help me in some way.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes. See the article "Choosing bins for histograms in SAS", which discusses the MIDPOINTS= and ENDPOINTS= options on the HISTOGRAM statement.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes! Thank you so much, I tried the code you provided, it works well, but still I'm wondering if I could output the parameters and percentile in a new dataset, not only displayed in a view window.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I've already answered that question, and the code I provided writes two data set. Read the article
"ODS OUTPUT: Store any statistic created by any SAS procedure"
If you run PROC PRINT or PROC CONTENTS on the 'PE' and 'FQ' data sets, you should see the information you want.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
9 replies
-
10-22-2017 04:40 PM
-
6905 views
-
4 likes
-
3 in conversation
-
