- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Subtotal count and percentage using proc sql
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi there,
I am now learning proc sql procedure and have a question on counting and calculating percentages of subtotal.
Suppose I create one dataset looks like below:
| group | gender | enrolled | finished |
|---|---|---|---|
| group 1 | M | Y | Y |
| group 1 | M | Y | Y |
| group 1 | F | Y | Y |
| group 1 | F | Y | N |
| group 2 | M | Y | Y |
| group 2 | M | Y | Y |
| group 2 | M | Y | Y |
| group 2 | F | Y | N |
| group 1 | F | Y | N |
| group 1 | F | Y | Y |
| group 2 | M | Y | Y |
| group 2 | F | Y | Y |
And I would like to get some summaries on counts and percentages based on groups and gender.
The output table looks like this:
| stat | group 1 | group 2 |
|---|---|---|
| enrolled | 6 | 6 |
| finished | 4(66%) | 5(83%) |
| F | 2(50%) | 4(80%) |
| M | 2(50%) | 1(20%) |
I just calculate the counts and percentages by hands but the basic ideas are the percentages of finished will be finished/enrolled, and the percentages in the gender are the proportions of finished people.
I would like to know how I can get the correct numbers and percentages using proc sql and count function in it. I also do not know whether I can transpose the output table in proc sql or not.
Any thought or explanations will help, thanks!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
There are a lot of different features that you can use to get your desired output. I'm assuming you are not familiar with proc freq or proc transpose? Is it necessary to only use proc sql;?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Mark,
I can use proc transpose and proc freq but sometimes I find it is hard to save the results from the procedure outputs and to change the sorting options. I think maybe there is a better way when using proc sql or using proc sql proc freq and proc transpose together. I just would like to find out an easy method to get the desired output. I think this is a typical example so I would like to know more, If you have any suggestions that would be helpful.
Thanks

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here's something to get you going (not tested):
proc sql;
select 'Enrolled' as Stat, sum(Enrolled='Y' AND Group='group 1') as Group1 'Group 1',
sum(Enrolled='Y' AND Group='group 2') as Group1 'Group 2'
from YourData
union
select 'Finished' as Stat,
cats( sum(Finished='Y' AND Group='group 1'),'(',sum(Finished='Y' AND Group='group 1')/sum(Group='group 1'),'%)' )
cats( sum(Finished='Y' AND Group='group 2'),'(',sum(Finished='Y' AND Group='group 2')/sum(Group='group 2'),'%)' )
from YourData;
quit;
You can also try processing with 'GROUP BY Group' clause but then your output will have two rows for Group 1 and Group 2 respectively--not columns. You could transform the resulting table.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I created a data set to test your codes and got several errors.
data test;
input group $ gender $ Enrolled $ Finished $ @@;
datalines;
group1 M Y N
group1 F Y N
group1 M Y Y
group1 F Y Y
group1 F Y Y
group1 M Y Y
group1 M Y N
group1 M Y N
group1 F Y Y
group1 M Y Y
group2 F Y N
group2 M Y Y
group2 F Y Y
group2 M Y Y
group2 F Y Y
group2 M Y N
group2 M Y N
group2 F Y Y
group2 F Y Y
group2 M Y Y
;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Your output doesn't appear to match your data. How are you calculating enrolled, finished, etc?
This gives you a quick test output:
proc tabulate data=test out=want;
class group gender enrolled finished;
table enrolled finished gender , group=''*(N='N'*f=8. colpctn='%'*f=8.);
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here's an updated and tested SQL code to get what you want:
proc sql;
select 'Enrolled' as Stat,
put(sum(Enrolled='Y' AND Group='group1'),8.) as Group1 'Group 1',
put(sum(Enrolled='Y' AND Group='group2'),8.) as Group1 'Group 2'
from Test
union
select 'Finished' as Stat,
cats( sum(Finished='Y' AND Group='group1'),' (',sum(Finished='Y' AND Group='group1')/sum(Group='group1')*100,'%)' ),
cats( sum(Finished='Y' AND Group='group2'),' (',sum(Finished='Y' AND Group='group2')/sum(Group='group2')*100,'%)' )
from Test
union
select 'Gender=M' as Stat,
cats( sum(Gender='M' AND Group='group1'),' (',sum(Gender='M' AND Group='group1')/sum(Group='group1')*100,'%)' ),
cats( sum(Gender='M' AND Group='group2'),' (',sum(Gender='M' AND Group='group2')/sum(Group='group2')*100,'%)' )
from Test
union
select 'Gender=F' as Stat,
cats( sum(Gender='F' AND Group='group1'),' (',sum(Gender='F' AND Group='group1')/sum(Group='group1')*100,'%)' ),
cats( sum(Gender='F' AND Group='group2'),' (',sum(Gender='F' AND Group='group2')/sum(Group='group2')*100,'%)' )
from Test
;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Below is a pure PROC SQL solution to your question. The output would look like this:
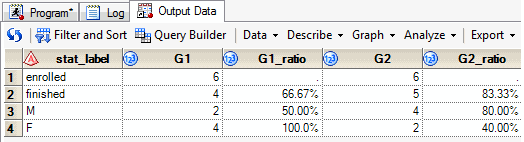
As others have alluded to, there are most certainly many other ways to tackle this problem. That being said, these series of SQL statements run efficiently ... potentially more efficiently than using several separate PROC FREQ statements that generate datasets using the OUT option (for which the output would still have to be reassembled).
PROC SQL;
CREATE TABLE example_data (
group VARCHAR(10)
, gender VARCHAR(1)
, enrolled VARCHAR(1)
, finished VARCHAR(1)
);
QUIT;
/* same as your data */
PROC SQL;
INSERT INTO example_data values ('group 1', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 1', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 1', 'F', 'Y', 'Y');
INSERT INTO example_data values ('group 1', 'F', 'Y', 'N');
INSERT INTO example_data values ('group 2', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 2', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 2', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 2', 'F', 'Y', 'N');
INSERT INTO example_data values ('group 1', 'F', 'Y', 'N');
INSERT INTO example_data values ('group 1', 'F', 'Y', 'Y');
INSERT INTO example_data values ('group 2', 'M', 'Y', 'Y');
INSERT INTO example_data values ('group 2', 'F', 'Y', 'Y');
QUIT;
/* create one record table similar to Oracle's SYS.DUAL table */
/* this handy technique allows us to select macro variables within a SQL statement out of thin air */
DATA dummy_row; dummy = 'X'; RUN;
/* set up macro variables for later use */
PROC SQL;
SELECT SUM(CASE WHEN enrolled = 'Y' AND group = 'group 1' THEN 1 ELSE 0 END) AS G1
, SUM(CASE WHEN enrolled = 'Y' AND group = 'group 2' THEN 1 ELSE 0 END) AS G2
INTO :enrolled_g1, :enrolled_g2
FROM example_data;
SELECT SUM(CASE WHEN finished = 'Y' AND group = 'group 1' THEN 1 ELSE 0 END) AS G1
, SUM(CASE WHEN finished = 'Y' AND group = 'group 2' THEN 1 ELSE 0 END) AS G2
INTO :finished_g1, :finished_g2
FROM example_data;
QUIT;
/* use "UNION ALL" because using "UNION" will impact sort position */
PROC SQL;
CREATE TABLE example_summary AS
SELECT "enrolled" length=20 AS stat_label
, &enrolled_g1 AS G1
, . format=percent8.2 AS G1_ratio
, &enrolled_g2 AS G2
, . format=percent8.2 AS G2_ratio
FROM dummy_row
UNION ALL SELECT "finished" AS stat_label
, &finished_g1 AS G1
, (&finished_g1/&enrolled_g1) AS G1_ratio
, &finished_g2 AS G2
, (&finished_g2/&enrolled_g2) AS G2_ratio
FROM dummy_row
UNION ALL SELECT 'M' AS stat_label
, SUM(CASE WHEN gender = 'M' AND group = 'group 1' THEN 1 ELSE 0 END) AS G1
, (CALCULATED G1/&finished_g1) AS G1_ratio
, SUM(CASE WHEN gender = 'M' AND group = 'group 2' THEN 1 ELSE 0 END) AS G2
, (CALCULATED G2/&finished_g2) AS G2_ratio
FROM example_data
UNION ALL SELECT 'F' AS stat_label
, SUM(CASE WHEN gender = 'F' AND group = 'group 1' THEN 1 ELSE 0 END) AS G1
, (CALCULATED G1/&finished_g1) AS G1_ratio
, SUM(CASE WHEN gender = 'F' AND group = 'group 2' THEN 1 ELSE 0 END) AS G2
, (CALCULATED G2/&finished_g2) AS G2_ratio
FROM example_data;
QUIT;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
7 replies
-
08-27-2015 01:31 PM
-
9376 views
-
0 likes
-
5 in conversation
-
