- Home
- /
- Programming
- /
- SAS Procedures
- /
- Request for immediate assistance
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello everybody,
My table currently contains:
subject1 | subject2
2 | 4
2 | 5
2 | 6
2 | 8
4 | 7
4 | 11
6 | 9
6 | 10
6 | 12
10 | 15
10 | 16
13 | 14
16 | 17
I need change this to:
2 | 4 | 5 | 6 | 8 | 7 | 11 | 9 | 10 | 12 | 15 | 16 | 17
13 | 14
What is the best way to do this? Any suggestions would be helpful.
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
proc transpose
by subject1
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Dear Peter, thanks for your cooperation
You know that with "proc transpose by subject 1" output file will be:
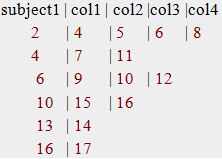
I want a program that support the following:
According to subject1 researching in col 1 to col nth respectively, if find it in each these columns, query it, otherwise don’t any change it (e.g. 2 in subject column that it is not observed in each other columns).
Input data:

Expected output:
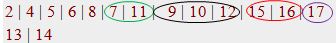

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Look into Proc BOM if you have the appropriate license of course...
There's a good solution on here to this problem by either Ksharp or FriedEgg, try searching under the term recursive lookup perhaps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
With SAS 9.1.3 you will have to rely on the skillful programming proposed, but with SAS/OR 12.1 you could use PROC OPTNET and request connected components, as follows:
data have;
infile datalines delimiter='|';
input subject1 subject2;
datalines;
2 | 4
2 | 5
2 | 6
2 | 8
4 | 7
4 | 11
6 | 9
6 | 10
6 | 12
10 | 15
10 | 16
13 | 14
16 | 17
;
proc optnet data_links=have out_nodes=want_long;
links_var from=subject1 to=subject2;
concomp;
run;
proc sort data=want_long; by concomp node; run;
data want;
length subjects $200;
do until (last.concomp);
set want_long; by concomp;
subjects = catx(" | ", subjects, node);
end;
keep subjects;
run;
proc print data=want noobs; run;
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi PG, thanks for your replay. I try to have that (SAS 12.1), but i can not found it. What should i do for it? zana
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SAS Analytics packages (STAT - ETS - OR - etc) are now numbered independently from Base SAS. To quote SAS:
"Core analytical products are now released every 12–18 months and are independent of Base SAS. To mark this independence, these products now have their own release numbers—the August 2012 releases are numbered 12.1—and they are available with SAS 9.3 TS1M2."
SAS 9.3 TS1M2 or after is thus required to get access to SAS/OR 12.1 or after.
PG

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Are you just trying to obtain a unique subject list? If so, how about something like:?
data want (keep=subject);
set have;
subject=subject1;
output;
subject=subject2;
output;
run;
proc sort data=want nodupkey;
by subject;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Reeza, thank you to refer to me and Matt . I have once done it for a sas user named sas_forum .
Here is what I got.
One more thing, if the following happened ,what are you going to do ?
subject1|col1|col2|col3|col4
2|4|5|6|8
99|7|6|.|.
Wait a minute..... I am thinking about a faster way. someone any thought ?
data have;
infile cards delimiter='|';
input subject1 $ subject2 $ ;
cards;
2 | 4
2 | 5
2 | 6
2 | 8
4 | 7
4 | 11
6 | 9
6 | 10
6 | 12
10 | 15
10 | 16
13 | 14
16 | 17
;
run;
proc sort data=have ;by subject1;run;
proc transpose data=have out=test(drop=_name_) ;
by subject1;
var subject2;
run;
proc sql noprint;
select quote(strip(name)) into : list1 separated by ',' from dictionary.columns where libname='WORK' and memname='TEST';
select name into : list2 separated by ' ' from dictionary.columns where libname='WORK' and memname='TEST';
select count(name) into : n from dictionary.columns where libname='WORK' and memname='TEST';
quit;
%put &list1;
%put &list2;
options compress=yes;
data want(keep=&list2 household);
/*to make speed faster*/
declare hash ha(hashexp : 20,ordered : 'a');
declare hiter hi('ha');
ha.definekey('count');
ha.definedata('count',&list1 );
ha.definedone();
declare hash _ha(hashexp: 20,ordered : 'a');
_ha.definekey('key');
_ha.definedone();
do until(last);
set test end=last;
/*Remove obs which variable's are all missing firstly*/
if cmiss(of &list2) lt &n then do;
count+1;
ha.add();
end;
end;
length key $ 40;
array h{*} $ 40 &list2 ;
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
do while(_rc eq 0); *until the end of Hash Table HA;
/*assign a unique cluster flag(i.e. household)*/
household+1;
do i=1 to &n;
/*push not missing value of current obs into another Hash Table _HA*/
if not missing(h{i}) then do; key=h{i}; _ha.replace();end;
end;
/*start to run over Hash Table HA ,until can not find any more
observation which is the same cluster with current observation*/
do until(x=1);
x=1;
/*copy the first obs from Hash Table HA into PDV*/
rc=hi.first();
do while(rc=0);
found=0;
do j=1 to &n;
/*find whether any one of value is included in the current obs*/
key=h{j};rcc=_ha.check();
if rcc =0 then found=1;
end;
if found then do;
/*if any one of value is included,then push the obs which is copied from
Hash Table HA into Hash Tables _HA,flag it the same cluster with the
current obs and output it into dataset*/
do k=1 to &n;
if not missing(h{k}) then do;
key=h{k};_ha.replace();end;
end;
output;x=0; _count=count;*keep this found obs's
index;
end;
rc=hi.next();
/*remove the found obs from Hash Table HA,since it has been seared*/
if found then rx=ha.remove(key : _count);
end;
end;
/*clear up all the index which is the same cluster with the current obs*/
_ha.clear();
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
end;
run;
data final;
set want;
by household;
length m $ 400;
retain m;
array x{*} $ &list2;
do i=1 to &n ;
if not findw(m,strip(x{i})) and not missing(x{i}) then m=catx(' ',m,x{i});
end;
if last.household then do;output;call missing(m);end;
keep household m;
run;
Xia Keshan
Message was edited by: xia keshan
Message was edited by: xia keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
: I definitely misunderstood what the OP was asking and like your solution. My only recommendations concern (1) why you would bother to sort and transpose the data as both steps seem unnecessary and (2) while extremely minor, why take three passes in the proc sql call when only one is needed?
I think that the following has the same result as your original code:
data have;
infile cards delimiter='|';
input subject1 subject2;
cards;
2 | 4
2 | 5
2 | 6
2 | 8
4 | 7
4 | 11
6 | 9
6 | 10
6 | 12
10 | 15
10 | 16
13 | 14
16 | 17
;
proc sql noprint;
select quote(strip(name)), name, count(name)
into :list1 separated by ',',
:list2 separated by ' '
:n
from dictionary.columns
where libname='WORK' and
memname='HAVE'
;
quit;
data need(keep=&list2 household);
declare hash ha(hashexp : 20,ordered : 'a');
declare hiter hi('ha');
ha.definekey('count');
ha.definedata('count',&list1 );
ha.definedone();
declare hash _ha(hashexp: 20,ordered : 'a');
_ha.definekey('key');
_ha.definedone();
do until(last);
set have end=last;
/*Remove obs which variable's are all missing firstly*/
if cmiss(of &list2) lt &n then do;
count+1;
ha.add();
end;
end;
length key $ 40;
array h{*} $ 40 &list2 ;
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
do while(_rc eq 0); *until the end of Hash Table HA;
/*assign a unique cluster flag(i.e. household)*/
household+1;
do i=1 to &n;
/*push not missing value of current obs into another Hash Table _HA*/
if not missing(h{i}) then do; key=h{i}; _ha.replace();end;
end;
/*start to run over Hash Table HA ,until can not find any more
observation which is the same cluster with current observation*/
do until(x=1);
x=1;
/*copy the first obs from Hash Table HA into PDV*/
rc=hi.first();
do while(rc=0);
found=0;
do j=1 to &n;
/*find whether any one of value is included in the current obs*/
key=h{j};
rcc=_ha.check();
if rcc =0 then found=1;
end;
if found then do;
/*if any one of value is included,then push the obs which is copied from
Hash Table HA into Hash Tables _HA,flag it the same cluster with the
current obs and output it into dataset*/
do k=1 to &n;
if not missing(h{k}) then do;
key=h{k};
_ha.replace();
end;
end;
output;
x=0;
_count=count;*keep this found obs's index;
end;
rc=hi.next();
/*remove the found obs from Hash Table HA,since it has been seared*/
if found then rx=ha.remove(key : _count);
end;
end;
/*clear up all the index which is the same cluster with the current obs*/
_ha.clear();
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
end;
run;
data want;
set need;
by household;
length m $ 400;
retain m;
array x{*} $ &list2;
do i=1 to &n ;
if not find(m,strip(x{i})) and not missing(x{i}) then m=catx(' ',m,x{i});
end;
if last.household then do;
output;
call missing(m);
end;
keep household m;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Arthur.T,
Do you remember that question posted by sas_forum about clustering obs a year ago? You try to use proc format to get it ?
For Q.
1)I have no choice at least for now and my ability .But I can make it faster to transpose data . I am also glad to see someone get a better and faster code .
2)Yeah. You are right. I can get three of them in the same statement. I just want make it align neat .Hope not cost too much time.
Xia Keshan
Message was edited by: xia keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi, Ksharp.
thank you for your reply.
Your code did not works with the sample data.
[ERROR 68-185: The function CMISS is unknown, or cannot be accessed.
ERROR 68-185: The function FINDW is unknown, or cannot be accessed]
However, maybe my information was not enough. Please find exact sample data (but better) with more explanation at follow
I should inform you that i run all the proposed code for those (even yours), but unfortunately none of them were implemented (for those sample data).
zana
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
What version of SAS are you using?
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
25 replies
-
04-18-2014 11:25 AM
-
7029 views
-
6 likes
-
7 in conversation
-
