- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Proc Transpose
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Everyone
I have a data set where I would like to make one column into a row. I understand that transpose moves a row into a column, but I am having trouble wrapping my head around how to transpose a column into a record.
Below is a link to a data set that has the following columns:
cnty_name
startyear
exit
agecat4
exitMonth
cohortyeartotal
cohortyeartotalage
distributionnumber
distributionpercent
cumulativenumber
cumulativepercent
outofhomecare
http://www.nycourts.gov/surveys/cwcip/transpose-issue.zip
What I would like to do is to make the outofhomecare column into a record. The current value that is in the outofhomecare column would be the cumulativenumber value and the value for the exit column would be "outofhomecare". The values for most of the other columns would be as they are.or blank (for calculations).
Does transpose correctly work for mapping a column to a record?
Paul
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You seem to be using COLUMN and ROW in different ways than I expect. Perhaps if we switch to VARIABLES and OBSERVATIONS instead?
The variable (_NAME_) that you see with the text string 'OutofHomeCare' on every observations is just put the automatic variable that PROC TRANSPOSE creates to indicate where the values for that observation (row) came from. If we had used two variable names in the VAR statement then the two variables (columns) would have been transposed into two observations (rows) in the output dataset. Then the value of the _NAME_ variable could help you see which variable (column) was use to create that observation (row) in the output dataset. The ID statement was what caused it to use the value of the EXIT variable to name the variables it created to store the multiple observations that it saw for each BY group. Without the ID statement those variables would instead just be named COL1, COL2, ...., COLn, where n is the maximum number of observations (rows) over all of the BY groups.
You have a variable in your dataset called OutofHomeCare that appears to be numeric. It appears to have a different value for each observation in the dataset. I do not know what you mean by converting it to a ROW if you did not want to rotate the values up into multiple variables.
Perhaps if you posted an example with just five or ten observations showing what you want to change?
It might also help if you could explain how you want to use the newly formatted dataset. Perhaps there is a better structure for your intended use.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Paul, I don't understand. Do you want one row with 2721 values for outofhomecare?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
No, what I need to do is to create one outofhomecare record for each unique instance of cnty_name, startyear, agecat4 exitmonthcategory. To make it easier to see, I changed the below example file to include only one county's worth of data. So there are 2040 records in the amended file (for only one county). There are 6 different values of startyear, 5 different values of agecat4 and 17 different value of exitmonthcategory. This would be 510 total records of outofhomecare for this one county. 'Exit' would equal the actual word 'outofhomecare', 'cnty_name' would be county-ABC, 'startyear' would be each of the start years (2006-2011), agecat4 would be each of the categories (0, 1 to 5, 6 to 12, etc.) and cumulativenumber would be the current value under the outofhomecare column. The other categories are blank for now.
That is what I am trying to do.
http://www.nycourts.gov/surveys/cwcip/transpose-issue.zip
Paul
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Still not sure what you want. Does the following come close?
proc transpose data=have (keep=cnty_name
startyear
agecat4
exitmonthcategory
OutOfHomeCare)
out=want;
by cnty_name startyear agecat4 exitmonthcategory;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Art
This behaves the same way as Tom's transpose--it creates new columns in addition to moving the outofhomecare column to records. I need to take a closer look to determine if the new columns created contain the correct values for the new outofhomecare records.
Paul

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Do tell me if I am wrong but as far as I get to know what you want is making outofhomecare to be in records not in columns.
I am not writing the sas code right now because 1st I want to be sure what u are actually asking for.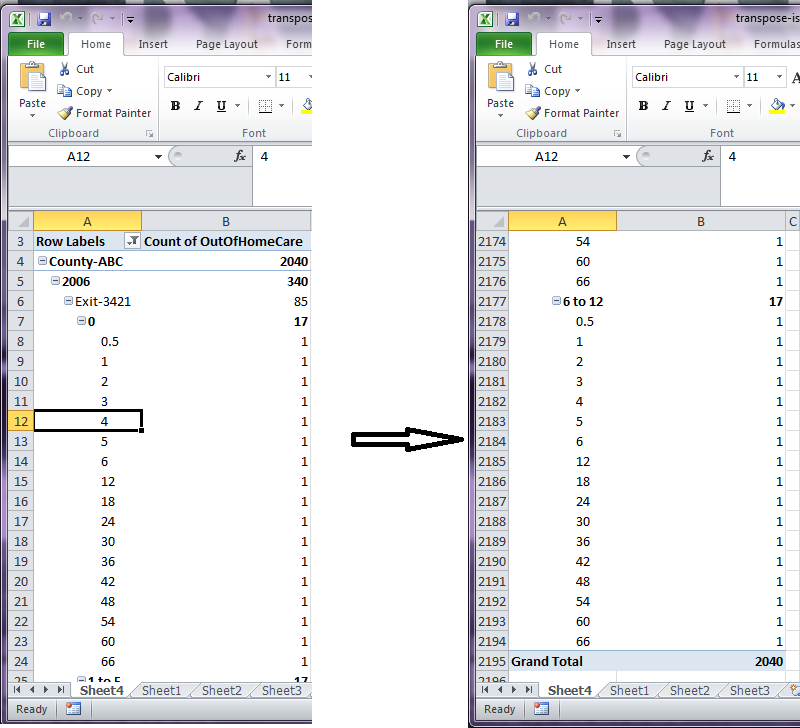
I have done something in excel to show you ,what i really get from your problem. Image shows the how for each cnty_name, startyear, agecat4 exitmonthcategory, the outofhomecare is divided.Is this you want sas?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Manu, can you post that spreadsheet so I can take a closer look at it?
Paul
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Paul
here it is...do let me know if i get you correctly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If looks like your data is grouped by
cnty_name
startyear
agecat4
exitMonth
cohortyeartotal
cohortyeartotalage
Do you want to use the value of EXIT as the name of the variable that contains the value from OutOfHomeCare?
proc transpose data=have out=want ;
by
cnty_name
startyear
agecat4
exitMonth
cohortyeartotal
cohortyeartotalage
;
id exit;
var OutOfHomeCare;
run;
What do you want to do with the columns
distributionnumber
distributionpercent
cumulativenumber
cumulativepercent
That also seem to have different values for each EXIT value?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Tom. I ran the above transform. It definitely put the outofhomecare column into rows under the _NAME_ column. However it also moved all the rows that were previously under Exit into columns, with each value being a different column. Is there a way to keep the existing values under the Exit column?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Paul: You could always use the copy statement (see: http://support.sas.com/documentation/cdl/en/proc/61895/HTML/default/viewer.htm#a000063666.htm )
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You seem to be using COLUMN and ROW in different ways than I expect. Perhaps if we switch to VARIABLES and OBSERVATIONS instead?
The variable (_NAME_) that you see with the text string 'OutofHomeCare' on every observations is just put the automatic variable that PROC TRANSPOSE creates to indicate where the values for that observation (row) came from. If we had used two variable names in the VAR statement then the two variables (columns) would have been transposed into two observations (rows) in the output dataset. Then the value of the _NAME_ variable could help you see which variable (column) was use to create that observation (row) in the output dataset. The ID statement was what caused it to use the value of the EXIT variable to name the variables it created to store the multiple observations that it saw for each BY group. Without the ID statement those variables would instead just be named COL1, COL2, ...., COLn, where n is the maximum number of observations (rows) over all of the BY groups.
You have a variable in your dataset called OutofHomeCare that appears to be numeric. It appears to have a different value for each observation in the dataset. I do not know what you mean by converting it to a ROW if you did not want to rotate the values up into multiple variables.
Perhaps if you posted an example with just five or ten observations showing what you want to change?
It might also help if you could explain how you want to use the newly formatted dataset. Perhaps there is a better structure for your intended use.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The below transpose may work with some modifications, thank you. While it did not come out the way I was envisioning, I'll report back on the result.
Paul
proc transpose data=have out=want ;
by
cnty_name
startyear
agecat4
exitMonth
cohortyeartotal
cohortyeartotalage
;
id exit;
var OutOfHomeCare;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
12 replies
-
11-26-2012 05:38 PM
-
6447 views
-
3 likes
-
4 in conversation
-
