- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Proc Compare: First Obs/Last Obs
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have been given a program that macros a proc compare so that we can automate that step across numerous datasets. However, for some of the datasets, First Obs is not = 1. See example output below; note that there are 74,901 records but First Obs = 74,902 and Last Obs = 149,802. Since the macro is meant to handle any dataset, it does not use an ID statement. I found that if I did a separate proc compare, using ID variables, I get First Obs = 1 and Last Obs = 74,901.
Can someone explain why this is? Obviously something is being handled differently within the proc compare when using ID variables vs. not using them, but I'm curious why it seems to double the number of observations, then compares the 2nd half.
Dataset Created Modified NVar NObs Label
LIB1_LOC.LB 06APR15:11:54:44 06APR15:14:22:31 43 74901 Laboratory Tests Results
LIB2_LOC.LB 06APR15:11:54:44 06APR15:14:22:31 43 74901 Laboratory Tests Results
Variables Summary
Number of Variables in Common: 43.
Observation Summary
Observation Base Compare
First Obs 74902 74902
Last Obs 149802 149802
Number of Observations in Common: 74901.
Total Number of Observations Read from LIB1_LOC.LB: 74901.
Total Number of Observations Read from LIB2_LOC.LB: 74901.
Number of Observations with Some Compared Variables Unequal: 0.
Number of Observations with All Compared Variables Equal: 74901.
NOTE: No unequal values were found. All values compared are exactly equal.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
With the ID statement it is basically a merge on the given id values. In your instance it appears that none of the given id values match between datasets, hence you get double out e.g.:
data a;
id=1;output;
id=2;output;
run;
data b;
id=3; output;
id=4; output;
run;
If I compare using id = id, neither match the other, so the resulting table is:
id=1
id=2
id=3
id=4
So thin of it a bit like a merge, if you still have issues post some test data and the code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks! But the datasets are identical--one is just a copy of the other (the proc compare is just for documentation purposes that we have the same dataset in LIB1_LOC as in LIB2_LOC). And they do have ID variables in common; when I created a separate proc compare and compared on the ID variables, it was fine. It's only when we don't use ID that we get the weird First Obs/Last Obs. I wondered if there is some sort of "pre-processing" that happens in a proc compare if no ID variables are specified?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
This example models your situation.
set sashelp.class;
run;
data class1;
modify class1 end=eof;
remove;
if eof then do;
do until(eof2);
set sashelp.class end=eof2;
output;
end;
stop;
end;
run;
data class2;
modify class2 end=eof;
remove;
if eof then do;
do until(eof2);
set sashelp.class end=eof2;
output;
end;
stop;
end;
run;
proc compare data=class1 compare=class2;
run;
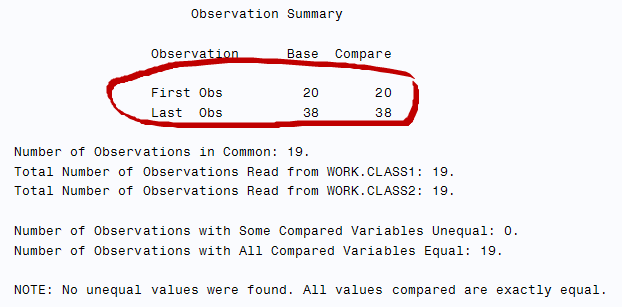
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you! I suppose this is just default how proc compare handles the processing when no IDs are specified?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
No your data has "removed" observations just like the example I created!
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
5 replies
-
04-24-2015 08:30 AM
-
3521 views
-
0 likes
-
3 in conversation
-
