- Home
- /
- Programming
- /
- SAS Procedures
- /
- How to group this kind of data
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I have a dataset which is like this
| ID | Previous | Current |
|---|---|---|
| 1 | 6 | |
| 1 | 6 | 7 |
| 1 | 7 | 8 |
| 1 | 21 | |
| 1 | 21 | 25 |
| 1 | 30 | 26 |
| 1 | 35 | 30 |
| 1 | 33 | |
| 1 | 33 | 35 |
it is sorted by "Current". As you can see, "Previous" is a record of the "Current" of the former observation. Now, I need to group them base on the first number of each link and have a output like this:
| ID | Previous | Current | Group |
| 1 | 6 | 6 | |
| 1 | 6 | 7 | 6 |
| 1 | 7 | 8 | 6 |
| 1 | 21 | 21 | |
| 1 | 21 | 25 | 21 |
| 1 | 30 | 26 | 33 |
| 1 | 35 | 30 | 33 |
| 1 | 33 | 33 | |
| 1 | 33 | 35 | 33 |
Is there a way to to come up the output I want?
Thank you

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
What's the logic behind group?
Ie how does 33 come in for id=1, previous=30 and current=26.
If you're looking at id's that have changed over time there's an old post on here that has some good code on how to solve that issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It is a data of which records adverse events of a medical study. Basically, the medical investigator recorded every reported events and give them a event number, which is the "Current" in my data above. They also use another variable "Previous" to record if a event is actually a subsequent one from the another event, as you can see a chain of events like 6->7->8. The chains, I must say, have no apparant set pattern as the investigator sometimes enter events afterward even they are the earlier one, so I have some chains of events like 33->35->30->26. Event 26 is actually the beginning of that chain of events. Now, I need to group each chain of events by its first event. So, 6->7->8 all in group 6, 21->25 in group 21, 33->35->30->26 in group 33.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If you read through Patrick thread, you maybe able to come up a solution, but it wouldn't be easy. Your question, IMHO, has presented an unique situation that is designed for Hash() to solve. Here is my try:
/*One condition: current being unique within the same ID*/
data have;
input ID Previous Current;
cards;
1 . 6
1 6 7
1 7 8
1 . 21
1 21 25
1 30 26
1 35 30
1 . 33
1 33 35
;
data want;
if _n_=1 then do;
if 0 then set have (rename=(id=_id previous=_pre current=_curr)) have;
declare hash h(dataset:'have', ordered:'a');
h.definekey('id','current');
h.definedata(all:'y');
h.definedone();
declare hash hp(dataset:'have (rename=(id=_id previous=_pre current=_curr))');
hp.definekey('_id','_pre');
hp.definedata('_curr');
hp.definedone();
declare hiter hi('h');
_rc=hi.first();
end;
set have (rename=(id=_id previous=_pre current=_curr) where=(missing(_pre)));
group=_curr;_start=_curr;_end=_curr;
_rc=hp.find(key:_id, key:group);
do _rc=0 by 0 while (_rc=0);
_start=min(_start,_curr);
_end=max(_end, _curr);
_rc=hp.find(key:_id, key:_curr);
end;
_rc=0;
do while (_start<=current<=_end and _rc=0);
output;
_rc=hi.next();
end;
drop _:;
run;
proc print;run;
Good Luck!
Haikuo

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I found an interesting thing , if previous is missing, current will be the head of this chain. Is that true ?
Also assuming there are unique value of current for each id.
/*One condition: current being unique within the same ID*/
data have;
input ID Previous Current;
cards;
1 . 6
1 6 7
1 7 8
1 . 21
1 21 25
1 30 26
1 35 30
1 . 33
1 33 35
2 . 32
2 32 35
;
run;
data want;
if _n_ eq 1 then do;
if 0 then set have;
declare hash ha1(dataset: 'have(where=(missing(Previous) ))');
declare hiter hi1('ha1');
ha1.definekey('id','Current');
ha1.definedata('id','Current');
ha1.definedone();
declare hash ha2(dataset: 'have(where=(not missing(Previous) ))');
ha2.definekey('id','Previous');
ha2.definedata('Current');
ha2.definedone();
declare hash h();
h.definekey('id','Current');
h.definedata('group');
h.definedone();
do while(hi1.next()=0);
group=Current;h.add();
Previous=Current;
do while(ha2.find()=0);
h.add();
Previous=Current;
end;
end;
end;
set have;
h.find();
run;
Ksharp

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
When i run your last year code, i see some error. ERROR: The value HAVE(WHERE=(MISSING(PREVIOUS) )) is not a valid SAS name. ERROR: Hash data set load failed at line 5083 column 4. ERROR: DATA STEP Component Object failure. Aborted during the EXECUTION phase. NOTE: The SAS System stopped processing this step because of errors. WARNING: The data set WORK.WANT may be incomplete. When this step was stopped there were 0 observations and 4 variables. How can it be resolved? zana

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
To me, it looks like a simplified Bill of Materials problem. Personally, I always like to tag it by the head, because there's guaranteed to be only one. Here's the code:
proc bom data=work.have out=work.want(keep=ID _Part_ _Parent_ _Prod_);
structure / parent=Current component=Previous id=(ID);
run;
If you want to switch from head to tail, it's a pretty easy SQL program.
Tom
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That's a neat little proc! Unfortunately you need the OR license for it ![]() .
.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Wow, did NOT know SAS has something like this. Wish I had it on my PC!
Haikuo
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
But When I run with my data .the result is totally different.
TOM
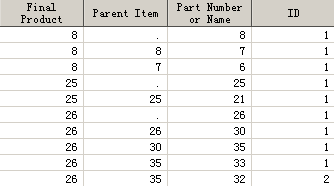
Mine
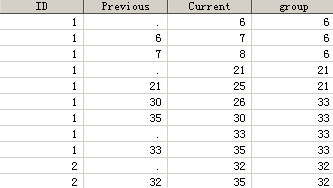
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
, mine will be still working on your data after a teeny tweak:
data have;
input ID Previous Current;
cards;
1 . 6
1 6 7
1 7 8
1 . 21
1 21 25
1 30 26
1 35 30
1 . 33
1 33 35
2 . 32
2 32 35
;
run;
data want;
if _n_=1 then do;
if 0 then set have (rename=(id=_id previous=_pre current=_curr)) have;
declare hash h(dataset:'have', ordered:'a');
h.definekey('id','current');
h.definedata(all:'y');
h.definedone();
declare hash hp(dataset:'have (rename=(id=_id previous=_pre current=_curr))');
hp.definekey('_id','_pre');
hp.definedata('_curr');
hp.definedone();
declare hiter hi('h');
_rc=hi.first();
end;
set have (rename=(id=_id previous=_pre current=_curr) where=(missing(_pre)));
group=_curr;_start=_curr;_end=_curr;
_rc=hp.find(key:_id, key:group);
do _rc=0 by 0 while (_rc=0);
_start=min(_start,_curr);
_end=max(_end, _curr);
_rc=hp.find(key:_id, key:_curr);
end;
_rc=0;
do while (_start<=current<=_end and _rc=0 and _id=id);
output;
_rc=hi.next();
end;
drop _:;
run;
proc print;run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
1. For the first two groups, the group will be different because it's based on the head of the tree, not the tail, but the information is identical, and could be switched with a SQL transformation.
2. For the last two groups, I was only working with the OP's original post, and hadn't made it far enough to see the discussion about identical parts with different IDs. As far as I can see, PROC BOM doesn't support compound keys, so I did a quick SQL transform before and after to blend ID and Previous/Current.
I believe the results are now equivalent.
Tom
proc sql;
create table _have as
select ID, Current, Previous,
((ID * 1000) + Current) as _Current,
((ID * 1000) + Previous) as _Previous
from work.have;
quit;
proc bom data=work._have out=work._want(keep=ID Current Previous _Part_ _Parent_ _Prod_);
structure / parent=_Current component=_Previous ID=(ID Current Previous);
run;
proc sql;
create table want as
select ID, Current, Previous,
_Prod_ - (int(_Prod_ / 1000)*1000) as Group
from work._want;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content


- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
zana: I don't have time to read this entire thread, but try the following:
data have;
infile cards delimiter='09'x;
input ID Previous Current;
cards;
1 . 6
1 6 7
1 7 8
1 . 21
1 21 25
1 30 26
1 35 30
1 . 33
1 33 35
;
data start;
set have (drop=id);
run;
proc sql;
select current
into :groups separated by ' '
from start
where missing(previous);
;
quit;
%let ngroups=&sqlobs.;
proc sql noprint;
select quote(strip(name)), name, count(name)
into :list1 separated by ',',
:list2 separated by ' '
:n
from dictionary.columns
where libname='WORK' and
memname='START'
;
quit;
*options compress=yes;
data need(keep=&list2 household);
declare hash ha(hashexp : 20,ordered : 'a');
declare hiter hi('ha');
ha.definekey('count');
ha.definedata('count',&list1 );
ha.definedone();
declare hash _ha(hashexp: 20,ordered : 'a');
_ha.definekey('key');
_ha.definedone();
do until(last);
set start end=last;
/*Remove obs which variable's are all missing firstly*/
if /*c*/nmiss(of &list2) lt &n then do;
count+1;
ha.add();
end;
end;
length key $ 40;
array h{*} $ 40 &list2 ;
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
do while(_rc eq 0); *until the end of Hash Table HA;
/*assign a unique cluster flag(i.e. household)*/
household+1;
do i=1 to &n;
/*push not missing value of current obs into another Hash Table _HA*/
if not missing(h{i}) then do;
key=h{i};
_ha.replace();
end;
end;
/*start to run over Hash Table HA ,until can not find any more
observation which is the same cluster with current observation*/
do until(x=1);
x=1;
/*copy the first obs from Hash Table HA into PDV*/
rc=hi.first();
do while(rc=0);
found=0;
do j=1 to &n;
/*find whether any one of value is included in the current obs*/
key=h{j};
rcc=_ha.check();
if rcc =0 then found=1;
end;
if found then do;
/*if any one of value is included,then push the obs which is copied from
Hash Table HA into Hash Tables _HA,flag it the same cluster with the
current obs and output it into dataset*/
do k=1 to &n;
if not missing(h{k}) then do;
key=h{k};
_ha.replace();
end;
end;
output;
x=0;
_count=count;*keep this found obs's index;
end;
rc=hi.next();
/*remove the found obs from Hash Table HA,since it has been seared*/
if found then rx=ha.remove(key : _count);
end;
end;
/*clear up all the index which is the same cluster with the current obs*/
_ha.clear();
/*copy the first obs from Hash Table HA into PDV*/
_rc=hi.first();
end;
run;
data need2;
set need;
by household;
length m $ 400;
retain m group;
array x{*} $ &list2;
do i=1 to &n ;
if not find(m,strip(x{i})) and not missing(x{i}) then do;
m=catx(',',m,x{i});
do j=1 to &ngroups.;
if scan("&groups.",j) eq x{i} then group=scan("&groups.",j);
end;
end;
end;
if last.household then do;
output;
call missing(m);
end;
keep household group m;
run;
proc sql;
select m, group
into :grouplist separated by ' ',
:groupnum separated by ' '
from need2
;
quit;
data want (drop=i j);
set have;
do i=1 to &ngroups.;
j=1;
do until(scan(scan("&grouplist.",i,' '),j) eq '');
if previous eq scan(scan("&grouplist.",i,' '),j) or
current eq scan(scan("&grouplist.",i,' '),j) then
group=scan("&groupnum.",i);
j+1;
end;
end;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
27 replies
-
11-13-2012 10:31 AM
-
6103 views
-
2 likes
-
7 in conversation
-
