- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: File Writer Operation Creates unwanted rows.
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I have an issue in the File Writer operation in my SAS Job; I am trying to write the data from a table to a file with pipe delimited. Total number of records are 1.7M;
There are few empty rows created after every row and in some cases values from a row is copied to a second row with randomly populated values on the columns.
Don’t understand what is wrong in the file writer operation.
Tried below alternatives but found that File Operation step is giving the issues.
- Removed the carriages return by using the compress expression COMPRESS(ECATS_CNTRCT_ID ,'0D'x) on the Extract Step.
- Output splitted into 2 files with less columns and read from 2 files and combined to a single file. But still same issues.
Please help.
Attached
- Screen shot of the job
- SAS Job Script
- File table rows errors highlighted for ref.
Regards
Arun


Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I did not see the code before.
Two big problems with the code.
1) Use of ATTRIB statements and their location. The SET statement should be after the ATTRIB statement, otherwise they will not have have any effect. SAS will have already defined the variables lengths when it reads the metadata from the input data set. In fact since you have no code that requires changing the length of any of these variables you do not need any of them. I would just delete them as they are not needed.
2) There is no LRECL specified in the FILE statement. So SAS could be inserting extra line breaks because the line has gotten longer than the default of 256. If you variables are all really 128 characters long then your probability of exceeding 256 is very high.
options missing='';
data _null_;
set &SYSLAST;
file '/staging/econ/PD817_Project/Dev/OutputFiles/CDR_Files_06042013/LE/LE_FINAL_OP_07102013.dat'
dlm='|' DSD lrecl=32500
;
put
DMT_RECORD_NUM
ECATS_CNTRCT_ID
ECATS_LEGAL_ENTITY_CODE
ECATS_LEGAL_ENTITY_DESCR
AD_ID
AD_NAME
AD_REP_NAME
DM_NAME
STATUS_NAME
OTHER_COMMITMENT
CUST_LISTED_NAME
CPE_DELIVERY_DT
CPE_INSTALLATION_DT
CPE_MAINT_END_DT
CPE_MAINT_START_DT
ECRM_CONTRACT_TYPE
ECRM_CONTRACT_SUB_TYPE
;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
One cause, especially with "random values" repeating in wrong columns could well be either linefeed or carriage return characters or both in one or more of the data fields. This is a very likely condition if you have people typing into a data entry program that allows those characters, usually from pressing an Enter key.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I also think so, but why is that not showing in table; total number of rows are correct on table, row is complete; nothing is rolling over to the next row in table.
but when write to a file, it all messes up.
Is there any property I have to look at it on the file level.
See the attached property of file.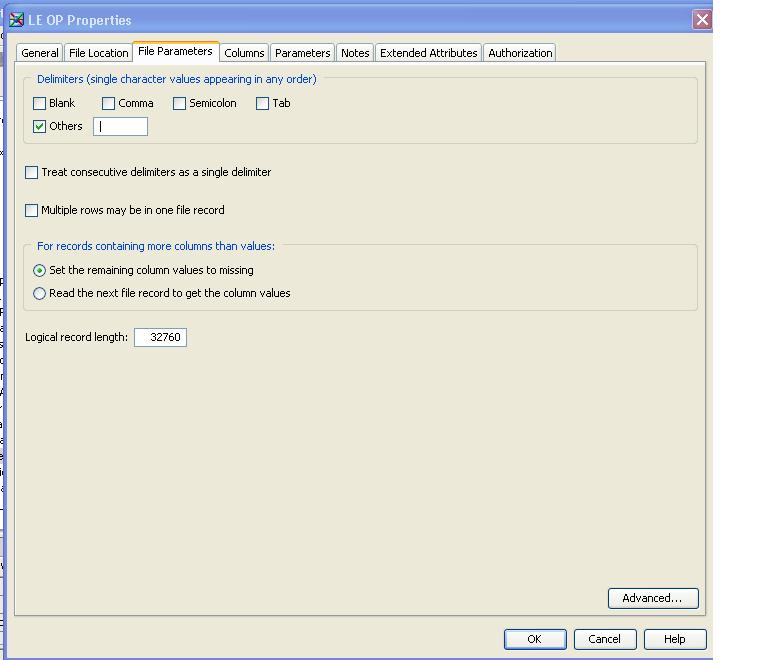
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Did the File Writer step generate a SAS log? If so then look at the log and/or the SAS code that it generated.
What type of file did you write? The screen shot is of what looks like Excel or some other spreadsheet program.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Its a pipe delimited flat file with .dat extension; we are loading this file to our Siebel database.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
1) Try clicking that "Treat consecutive delimiter...." box and see if it generates the DSD option in the SAS code it generates.
2) Check your character variables for "pipe" characters in addition to carriage returns.
3) Look at the file with a text editor to see if the file is actually messed up or if it is just Siebel that is messed up.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The OP posted the full code as zip file. The zipped file simply misses the .sas extension.
DI Studio allows you to define job flows on metadata level. But to actually execute it you need to generate SAS code. Sometimes it's necessary to modify DI transformation generated SAS code. The nodes give you an option to switch over to "user written" mode. You then can modify the generated code as you wish. DI Studio will then use the user written code as part of code generation but marks it in the code as comment /*---- Start of User Written Code ----*/
That's what you can see in the code the OP posted.
As the relevant part of the code where the issue needs resolution is "user written" we can provide advise and code as if this were any code written outside of DI studio. Once user written any changes on metadata level for this node (eg. checking "Treat consecutive delimiter...") has no more an effect on what code gets generated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
In your initial post you're showing us a SAS table but the problem you flag is with a text file. I believe Tom's suggestion that you actually look directly at the text file produced using a text editor like Notepad++ is a good one. Notepad++ allows you also to visualise "whitespace" characters like CR and LF.
In the code you've posted you're only compressing hex 'OD'. May be you need also to include hex 'OA' (a line feed).
Monotonic() is an unsupported function. You shouldn't use it for production worthy code.
I've realised that in the code you've posted you changed over to "user written" in the "file writer" node. If so then you could streamline your program a bit by removing unnecessary passes through data. Simply extract your data and then give below code a try (user written as part of your file writer node).
data _null_;
set &SYSLAST;
attrib DMT_RECORD_NUM length = 8 ;
attrib ECATS_CNTRCT_ID length = $128;
attrib ECATS_LEGAL_ENTITY_CODE length = $128;
attrib ECATS_LEGAL_ENTITY_DESCR length = $128;
attrib AD_ID length = $128;
attrib AD_NAME length = $128;
attrib AD_REP_NAME length = $128;
attrib DM_NAME length = $128;
attrib STATUS_NAME length = $128;
attrib OTHER_COMMITMENT length = $128;
attrib CUST_LISTED_NAME length = $100;
attrib CPE_DELIVERY_DT length = $128;
attrib CPE_INSTALLATION_DT length = $128;
attrib CPE_MAINT_END_DT length = $128;
attrib CPE_MAINT_START_DT length = $128;
attrib ECRM_CONTRACT_TYPE length = $128;
attrib ECRM_CONTRACT_SUB_TYPE length = $128;
file '/staging/econ/PD817_Project/Dev/OutputFiles/CDR_Files_06042013/LE/LE_FINAL_OP_07102013.dat' dlm='|' DSD;
DMT_RECORD_NUM=_n_;
array charvars _character_;
do over charvars;
charvars=compress(charvars,,'c');
end;
CUST_LISTED_NAME=SUBSTRN(CUST_LISTED_NAME ,1,100);
put
DMT_RECORD_NUM
ECATS_CNTRCT_ID
ECATS_LEGAL_ENTITY_CODE
ECATS_LEGAL_ENTITY_DESCR
AD_ID
AD_NAME
AD_REP_NAME
DM_NAME
STATUS_NAME
OTHER_COMMITMENT
CUST_LISTED_NAME
CPE_DELIVERY_DT
CPE_INSTALLATION_DT
CPE_MAINT_END_DT
CPE_MAINT_START_DT
ECRM_CONTRACT_TYPE
ECRM_CONTRACT_SUB_TYPE
;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I did not see the code before.
Two big problems with the code.
1) Use of ATTRIB statements and their location. The SET statement should be after the ATTRIB statement, otherwise they will not have have any effect. SAS will have already defined the variables lengths when it reads the metadata from the input data set. In fact since you have no code that requires changing the length of any of these variables you do not need any of them. I would just delete them as they are not needed.
2) There is no LRECL specified in the FILE statement. So SAS could be inserting extra line breaks because the line has gotten longer than the default of 256. If you variables are all really 128 characters long then your probability of exceeding 256 is very high.
options missing='';
data _null_;
set &SYSLAST;
file '/staging/econ/PD817_Project/Dev/OutputFiles/CDR_Files_06042013/LE/LE_FINAL_OP_07102013.dat'
dlm='|' DSD lrecl=32500
;
put
DMT_RECORD_NUM
ECATS_CNTRCT_ID
ECATS_LEGAL_ENTITY_CODE
ECATS_LEGAL_ENTITY_DESCR
AD_ID
AD_NAME
AD_REP_NAME
DM_NAME
STATUS_NAME
OTHER_COMMITMENT
CUST_LISTED_NAME
CPE_DELIVERY_DT
CPE_INSTALLATION_DT
CPE_MAINT_END_DT
CPE_MAINT_START_DT
ECRM_CONTRACT_TYPE
ECRM_CONTRACT_SUB_TYPE
;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yep - you're of course right. Missed that the lrecl had only been defined as metadata but not actually in the code - so it appears the OP set this only after changing to "user written".
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sorry for the late reply;
Thanks Tom, it worked for me.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
10 replies
-
07-10-2013 02:06 PM
-
4912 views
-
0 likes
-
4 in conversation
-
