- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Count variable
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi
I have this dataset:
year firm industry value status
2000 a I 8 A
2000 b II 1 A
2001 a I 7 A
2001 a I 0 N
2001 b II 6 A
2002 a I 5 A
2003 b II 2 A
2003 c III 9 A
2003 d III 0 N
I need to do these steps:
1. create a variable status= A(for value greater than 0) and N otherwise. I have done that above
2. need to delete if a firm appears twice in any year, preferably retain the firm observation with the positive value.
3.For each industry each year, I need to count the number of firms that have a positive value(count=A) and the total number of firms.
I am getting stuck on the 2nd step.
For the 3rd step, this is the code I wrote:
data ratio1;
set ratio;
Acount+1;
Ncount+1;
If first.status='A' then Acount=1;
If first.status='N' then Ncount=1;
by year industry_new;
run;
But these codes are not working. The error message that comes is: ERROR: BY variables are not properly sorted on data set
Would appreciate help.
Namrata

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Try this ,
data test;
input year firm :$ industry :$ value;
if value>0 then Status='A' ;else Status='N';
cards;
2000 a I 8
2000 b II 1
2001 a I 7
2001 a I 0
2001 b II 6
2002 a I 5
2002 a I 0
2002 b II 5
2003 b II 2
2003 c III 9
2003 d III 0
;
proc sql;
/*query3:gives count of firms per year*/
select year,count(*) as count_firm
from (
/* query2:gives count of firms per year per industry wise having status ='A' */
select year,firm,industry,status,count(*) as A_firms
from
(
/* query1 start: gives solution to your point2*/
select distinct year,firm,industry,value,status
from test group by year,firm having value=max(value)
/*query1 ends*/
)
where status='A' group by year,industry
/*query2 ends*/
)
group by year;
/*query3 ends*/
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Namrata,
Please check the below code
proc sql;
/*need to delete if a firm appears twice in any year, preferably retain the firm observation with the positive value.*/
create table status as select distinct year,firm,industry, status, count(status) as count from test where status='A' and value > 0 group by year,firm,industry;
/*.For each industry each year, I need to count the number of firms that have a positive value(count=A) and the total number of firms.*/
create table count as select distinct status,year,industry,firm,count(status) as count_status,count(firm) as count_firm from status group by year,industry;
quit;
The dataset count has the desired output. if i understood your requirement correctly you are expecting the below output. could you please check and let me know if this is not the desired output.
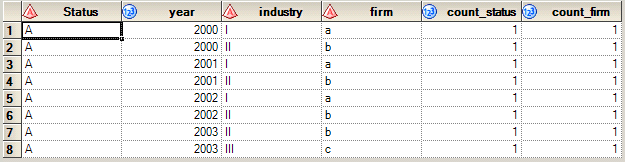
Thanks,
Jag
Jag
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Jag
Thank you for your suggestion.
I need the output slightly different. I need two count variables
- the first count variable contains the number of firms per industry. Each indsutry row will contain the total number of firms in that industry.
- the second count variable contains the number of firms with positive value per industry. Each industry row will contain the number of firms with positive values in that industry.
I need these two count variables so as to construct a ratio of # of positives divided by the total #.
Using Pradeep's code, I have been able to construct the first variable and now, am trying to do the second.
As far as retaining the firm with positive values each year, to avoid duplicate firms each year, I do not think that should be a problem, I had a look at the dataset.
Thanks
Namrata

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Namrata,
This should do what you want: For reference I nested the creation of the sum variables in the joins in testb, but this could just as easily be done in two separate tables and then joined in, in the same manner. I maxed the values in testa bc you only wanted the best value for duplicates. Hope this helps.
proc sql;
create table testa as
select distinct year, firm, industry, (max(value)) as value, (case when (max(value)) >0 then 'A' else 'N' end) as status
from test
group by year, firm, industry;
create table testb as
select distinct a.*, b.acount, c.numfirm
from testa a left join (select distinct year, firm, industry, (sum(case when status = 'A' then 1 else 0 end)) as acount
from testa group by year, firm, industry) b on (a.year=b.year and a.firm=b.firm and a.industry=b.industry)
left join (select distinct year, count(firm) as numfirm, industry
from testa group by year, industry) c on (a.year=c.year and a.industry=c.industry);
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you, overmar.
I was still working on earlier codes and I think I got the desired output.
I had to use the sum() statement. That worked!
Thank you, everyone.
As always, this forum is a blessing for SAS newbies ![]()
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
5 replies
-
01-11-2014 04:24 PM
-
4045 views
-
0 likes
-
4 in conversation
-
