- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: Count number of distinct cases meeting different criteria
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I would like to count numbers of distinct cases that meet different criteria in my large dataset. The example data looks like below:
| obsid | var |
| 1 | a |
| 1 | b |
| 1 | b |
| 2 | b |
| 2 | b |
| 2 | c |
| 2 | c |
| 3 | a |
| 3 | a |
| 4 | c |
I need to see how many distinct obsids that contain "a", "b" or "c" in var.
I could do for different criteria one after another like this:
proc sql; select count(distinct obsid) as N_a from project.dswi_nodebride where var="a"; run;
proc sql; select count(distinct obsid) as N_b from project.dswi_nodebride where var="b"; run;
proc sql; select count(distinct obsid) as N_c from project.dswi_nodebride where var="c"; run;
I have many criteria, so is there a simpler way to do for all different but similar criteria?
Thanks a lot!
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SQL is ideal for this:
data have;
input obsid var$;
datalines;
1 a
1 b
1 b
2 b
2 b
2 c
2 c
3 a
3 a
4 c
;
proc sql;
create table want as
select var, count(distinct obsid) as n
from have
group by var;
select * from want;
quit;
PG

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
proc sql;
select var,count(distinct obsid) as N from have
group by var;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SQL is ideal for this:
data have;
input obsid var$;
datalines;
1 a
1 b
1 b
2 b
2 b
2 c
2 c
3 a
3 a
4 c
;
proc sql;
create table want as
select var, count(distinct obsid) as n
from have
group by var;
select * from want;
quit;
PG

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
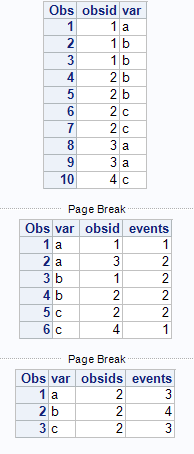
This is somewhat like counting subjects with adverse events. This counts events and obsids for each level of var.
infile cards expandtabs;
input obsid var :$1.;
cards;
1 a
1 b
1 b
2 b
2 b
2 c
2 c
3 a
3 a
4 c
;;;;
run;
proc print;
run;
proc summary data=ae nway;
class var obsid;
output out=events(drop=_type_ rename=(_freq_=events));
run;
proc print;
run;
proc summary data=events nway;
class var;
output out=obsids(drop=_type_ rename=(_freq_=obsids)) sum(events)=;
run;
proc print;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks so much to you all!
Lizi
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
4 replies
-
10-31-2014 12:54 PM
-
3984 views
-
6 likes
-
4 in conversation
-
