- Home
- /
- Programming
- /
- SAS Procedures
- /
- Applying group to variables
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
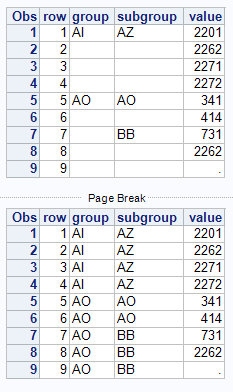
Hi everyone! I've been given a dataset where the first 3 columns are: Group, Subgroup, Code. As you can see, the way this person formatted it is that the first observation of a Code within a Group and Subgroup gives values for the Group and Subgroup. Then the following observations in the Group and Subgroup have these fields left blank. I have put an example of what the dataset looks like below.
How can I tell SAS to apply the correct names of the Group and Subgroup to each observation? So that, for example, if I make a new dataset and include a statement that says IF GROUP="AI"; statement, will the Codes 2262, 2271, and 2272 be included?
The first column is the name of the Group, the second column is the name of the Subgroup
| 1 | AI | AZ | 2201 |
|---|---|---|---|
| 2 | 2262 | ||
| 3 | 2271 | ||
| 4 | 2272 | ||
| 5 | AO | AO | 341 |
| 6 | 414 | ||
| 7 | BB | 731 | |
| 8 | 2262 |
Thank you for your help!
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Often when data is imported from excel with merged-cells this type of missing data pattern will created. You can use the features of the UPDATE statement to fill of LOCF the missing values. You just need to identify the variables to be operated on and create dummy BY variable a "necessary evil". I added that variable with a data step view.
infile cards dsd;
input row group $ subgroup $ value;
cards;
1,AI,AZ,2201
2,,,2262
3,,,2271
4,,,2272
5,AO,AO,341
6,,,414
7,,BB,731
8,,,2262
9,,,
;;;;
run;
proc print;
run;
data v / view=v;
set mergedcell;
retain dummy 1;
run;
%let by = dummy;
%let fill = group subgroup;
data filled;
if 0 then set mergedcell;
update v(obs=0 keep=&by) v(keep=&by &fill);
by &by;
set mergedcell(drop=&fill);
output;
drop dummy;
run;
proc print;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well, as long as they are in the order required, then retain should work. (note, for future if you could put data in a datastep to reduce the amount of typing).
data have;
group="AI";
subgroup="AZ";
val=2201; output;
group=""; subgroup="";
val=2262; output;
val=2271; output;
val=2272; output;
group="AO";
subgroup="AO";
val=341; output;
group=""; subgroup="";
val=414; output;
subgroup="BB";
val=731; output;
subgroup="";
val=2262; output;
run;
data want (drop=lstgroup lstsubgroup);
set have;
retain lstgroup lstsubgroup;
if group ne "" then lstgroup=group;
else group=lstgroup;
if subgroup ne "" then lstsubgroup=subgroup;
else subgroup=lstsubgroup;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
There is always the auto-update trick (learned from Tom) :
data have;
infile datalines truncover;
length group subgroup $4;
input obs 1-4 group 5-8 subgroup 9-12 x 13-16;
dum = 1;
datalines;
1 AI AZ 2201
2 2262
3 2271
4 2272
5 AO AO 341
6 414
7 BB 731
8 2262
;
data want;
update have(obs=0) have;
by dum;
output;
drop dum;
run;
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Often when data is imported from excel with merged-cells this type of missing data pattern will created. You can use the features of the UPDATE statement to fill of LOCF the missing values. You just need to identify the variables to be operated on and create dummy BY variable a "necessary evil". I added that variable with a data step view.
infile cards dsd;
input row group $ subgroup $ value;
cards;
1,AI,AZ,2201
2,,,2262
3,,,2271
4,,,2272
5,AO,AO,341
6,,,414
7,,BB,731
8,,,2262
9,,,
;;;;
run;
proc print;
run;
data v / view=v;
set mergedcell;
retain dummy 1;
run;
%let by = dummy;
%let fill = group subgroup;
data filled;
if 0 then set mergedcell;
update v(obs=0 keep=&by) v(keep=&by &fill);
by &by;
set mergedcell(drop=&fill);
output;
drop dummy;
run;
proc print;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
3 replies
-
06-10-2015 10:40 AM
-
2669 views
-
8 likes
-
4 in conversation
-
