- Home
- /
- Programming
- /
- Enterprise Guide
- /
- Re: Drop variables that have only missing or null values
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have this kind of table and I would like to delete Header4 and Header6 which are containing only missing / null values.
| Header 1 | Header 2 | Header 3 | Header 4 | Header 5 | Header 6 | Header 7 |
|---|---|---|---|---|---|---|
| 1 | 3 | 1 | 5 | 3 | ||
| 2 | 4 | 6 | 6 | 4 | ||
| 3 | 5 | 7 | 3 | 6 |
And I have few other tables to similar of this table, but not sure which columns are missing values. Can I use macro language to run this process?
Thanks.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
OK. Actually I have already posted such code for many posts .
OR if you like IML , you also could get it ,and IML is very fast . But IML only can deal with the variables which are all NUM or CHAR .
data have;
infile datalines dlm="," dsd missover;
input (Header1 Header2 Header3 Header4 Header5 Header6 Header7) ($);
datalines;
1,3,1,,5,,3
2,4,6,,6,,4
3,5,7,,3,,6
;
run;
proc transpose data=have(obs=0) out=vname ;
var _all_;
run;
proc sql;
select catx(' ','n(',_name_,') as ',_name_) into : list separated by ',' from vname;
create table temp as
select &list from have;
quit;
proc transpose data=temp out=drop ;
var _all_;
run;
proc sql;
select _name_ into : drop separated by ' ' from drop where col1=0;
quit;
data want;
set have(drop=&drop);
run;
Xia Keshan

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I made this code some time ago. The macro takes a library in library=parameter and all the datasets inside. Checks for columns with all variables missing and does a copy of the table which is written to library in outlib=parameter. It also adds 'nomiss' string at the end of each table name.
As the macro generates a lot of code, it is written to temporary external file
%macro new(library=,outlib=);
%local i j k;
proc sql noprint;
select memname into :tables separated by " "
from dictionary.tables where libname="%upcase(&library.)";
quit;
%do i = 1 %to %util_countwords(&tables.);
proc sql noprint;
create table my_dictionary_columns as
select name, monotonic() as N from dictionary.columns
where memname="%scan(&tables,&i.)" and libname="%upcase(&library.)";
quit;
data _null_;
file 'temp.txt';
set my_dictionary_columns end=the_end;
put "retain miss" _N_" 0; miss" _N_"=missing";
put "(" name ")";
put "+miss" _N_";keep miss" _N_";";
if the_end then call symputx('N_columns',_N_);
run;
/* option symbolgen;*/
data miss%scan(&tables,&i.);
set %upcase(&library.).%scan(&tables,&i.) end=the_end;
%include 'temp.txt';
nasumeno+1;
keep nasumeno;
if the_end then output;
run;
data concated;
set miss%scan(&tables,&i.);
array misses
keep i ;
do i = 1 to dim(misses);
if misses/nasumeno=1 then do;
check+1;
output;
end;
end;
call symputx('check',check);
run;
proc sql noprint;
create table to_delete as
select a.name
from my_dictionary_columns as a inner join concated as b on(a.N=b.i)
;
quit;
data _null_;
file 'drop_temp.txt';
set to_delete;
put "drop " name ";";
run;
/****************************************************************************************************/
data &outlib..%substr(%scan(&tables,&i.),1,%sysfunc(min(27,%length(%scan(&tables,&i.)))))nomis;
set %upcase(&library.).%scan(&tables,&i.);
;
%if &check.>0 %then %do;
%include 'drop_temp.txt';
%put &check. variables removed due to missing values from %upcase(&library.).%scan(&tables,&i.);
%end;
%else %do;
%put no missing data discovered in table %upcase(&library.).%scan(&tables,&i.);
%end;
run;
%end;
%mend new;
%new(outlib=&outlib.,library=&library.);
Jakub

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Quite simple really, normalise your data, then take variables with missing sum, then drop that list:
data have;
infile datalines dlm="," dsd missover;
input Header1 Header2 Header3 Header4 Header5 Header6 Header7;
datalines;
1,3,1,,5,,3
2,4,6,,6,,4
3,5,7,,3,,6
;
run;
data inter (keep=head val_res);
set have;
array header{7};
do i=1 to 7;
head="HEADER"||strip(put(i,best.));
val_res=header{i};
output;
end;
run;
proc sql noprint;
select distinct HEAD
into :DROP_LIST separated by " "
from WORK.INTER
group by HEAD
having sum(VAL_RES)=.;
quit;
data want;
set have (drop=&DROP_LIST.);
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If all the variables are numeric why all the extra processing?. You can get Ns directly and done. The more difficult question is how do you do this efficiently for data with both character and numeric variables and a large number of obs. Once you find the first non-missing for a variable you can stop looking at that variable but variables with all missing values every observations must be tested.
proc means n stackods data=have;
ods output summary=summary(where=(n=0));
run;
ods select all;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
This topic has been heavily talked . If your data are all numeric type , this could easily been done by the following.
But I would like to use SQL which can also take care CHARACTER type variable and more control .
data have; infile datalines dlm="," dsd missover; input Header1 Header2 Header3 Header4 Header5 Header6 Header7; datalines; 1,3,1,,5,,3 2,4,6,,6,,4 3,5,7,,3,,6 ; run; ods select none; ods output nlevels=want(where=(NNonMissLevels=0)); proc freq data=have nlevels; tables _numeric_; run;
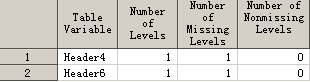
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
My dataset, it is all character type.. Sorry, I should have mentioned at the beginning.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well, with a minor change to my code it should handle character:
data inter (keep=head val_res);
set have;
array header{7};
do i=1 to 7;
head="HEADER"||strip(put(i,best.));
if strip(header{i})="" then val_res=0;
else val_res=1;
output;
end;
run;
proc sql noprint;
select distinct HEAD
into :DROP_LIST separated by " "
from WORK.INTER
group by HEAD
having sum(VAL_RES)=0;
quit;
data want;
set have (drop=&DROP_LIST.);
run;
Note I am not at work so can't test. A similar approach could do both char and numeric.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
OK. Actually I have already posted such code for many posts .
OR if you like IML , you also could get it ,and IML is very fast . But IML only can deal with the variables which are all NUM or CHAR .
data have;
infile datalines dlm="," dsd missover;
input (Header1 Header2 Header3 Header4 Header5 Header6 Header7) ($);
datalines;
1,3,1,,5,,3
2,4,6,,6,,4
3,5,7,,3,,6
;
run;
proc transpose data=have(obs=0) out=vname ;
var _all_;
run;
proc sql;
select catx(' ','n(',_name_,') as ',_name_) into : list separated by ',' from vname;
create table temp as
select &list from have;
quit;
proc transpose data=temp out=drop ;
var _all_;
run;
proc sql;
select _name_ into : drop separated by ' ' from drop where col1=0;
quit;
data want;
set have(drop=&drop);
run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
IML code for such question. Since you start such a topic, I just wrote some IML code for this . IML is very fast, Rick might want see this.
data have; infile datalines dlm="," dsd missover; input (Header1 Header2 Header3 Header4 Header5 Header6 Header7) ($); datalines; 1,3,1,,5,,3 2,4,6,,6,,4 3,5,7,,3,,6 ; run; proc iml; use have; read all var _char_ into x[c=vname]; drop= vname[loc(missing(x)[+,]=nrow(x))]; submit drop; data want; set have(drop=&drop); run; endsubmit; quit;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks so much!! That works perfect, but PROC IML can't be run in SAS enterprise guide?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yeah. But you can run it in SAS University Edition which is totally free , you can downlaod it from sas.com .
And one more thing , You could also try my PROC FREQ code Like :
tables _char_ ;
OR
tables _all_;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You can run IML code in EG as long as you have it .
Run
proc setinit;run;
Check if you have IML .
Xia Keshan

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you! This was just what I needed. I have been using a MUCH longer complex macro.
It's curious that SAS doesn't properly recognize the code for purposes of assigning correct colors to the various lines.
Nonetheless, your code works like a charm!
Gerry
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Check out this tutorial series to learn how to build your own steps in SAS Studio.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
12 replies
-
05-21-2015 06:25 PM
-
23110 views
-
8 likes
-
6 in conversation
-
