- Home
- /
- Analytics
- /
- SAS Data Science
- /
- Re: Saving Predicted Training and Validation Values Within Enterprise ...
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
My dependent variable, or target variable, within my Enterprise Miner Decision Tree run is continuous. I am interested in saving the predicted values to my dataset for both the training and the validation.
May I ask for a little help or guidance in how to do this most effectively? I plan on using them in a post-hoc regression run.
Thank you very much in advance - and thank you for all of the help earlier with my other Enterprise Miner question.
Zach Feinstein, Statistical Data Modeler
P (952) 838-4289 C (612) 590-4813 F (952) 838-2010
SFM Mutual Insurance Company
3500 American Blvd. W,
Suite 700, Bloomington, MN 55431
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You can keep em_import_data because that is the data set that comes into the SAS Code node. (the decision tree exports it and the SAS code node imports it if that makes sense).
- Add a SAS Code node to your diagram
- Connect your decision tree node to the sas code node.
- Open the SAS code editor of the SAS code node
- Paste the below (change the C:\temp to specify a directory and id for the actual name of your variable id).
%let EXPORT_DIR_NAME= C:\temp; /* An existing directory that you have access to */
%let EXPORT_TABLE_NAME=zach_exported_table; /* Whatever name you want */
libname export "&EXPORT_DIR_NAME";
data export.&EXPORT_TABLE_NAME.;
set &EM_IMPORT_DATA;
keep id p_: v_: ;
run;
5. Run it, and you will have a data set saved with the ID, predicted, and validated columns.
How did that go?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
All Model nodes automatically score your observations with their predicted values.
After you run your Decision Tree, go to the properties panel and click on the ellipsis of Exported Data. Select either the training or validation sets and click on Explore. Go all the way to the right and you will notice that you have new columns with the prefix "p_". These correspond to the predicted probabilities or predicted levels for your target.
These columns are what you are looking for correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Miguel. Three questions: (1) It looks like whether I select the training or validation sets I get the same columns at the end. (2) It limits the results to only 10,000 records - I have over 50,000 records. (3) The variables do not begin with a p_. Should I be concerned about that.
Again, thank you very much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
1) that's correct. why would you get different columns?
2) when you are exploring your exported data sets, you are looking at a sample by default. See those Sample Property options? Set Fetch Size to Max.
3) the predicted probabilites start with p_<target>. For example if my interval target was age, the added column for the predicted probability would be p_age. That-s not what you are seeing?
no prob Zach, anytime. It seems you are up to good results. keep us posted!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Good point on the different columns. Yes, the Fetch Size is set to Max. You can see it in the upper left of the first inserted picture.
You can also see the the "p_" variables are not included over the right side of the window when I Explore the data. Instead I think it says "Predicted..." or "Validated..."
Also, if I look at the Properties (another image included) 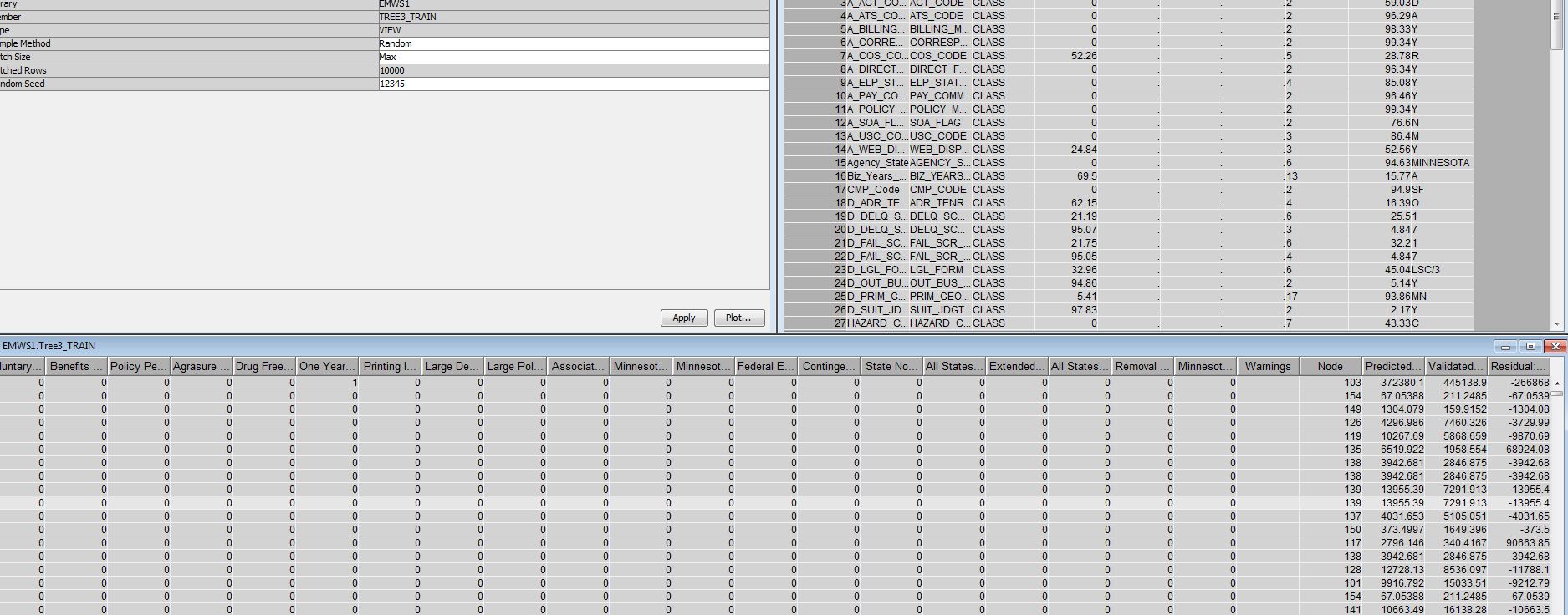
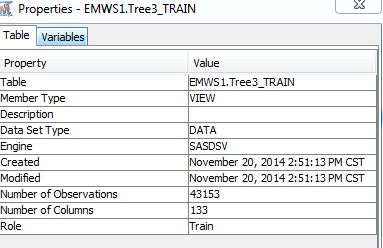
we then see it correctly has my correct number of observations (not 10,000, but 43,153). So the question then arises - where is it placing this EMWS1.Tree3_Train file?
I apologize for the formatting of this message in advance.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
maybe 10,000 is the maximum for this Explore option. What happens when instead of Explore you use Browse?
To locate your EMWS1 (workspace) like this:
Go to View menu->Explorer. Turn on the check mark for Show Project Data. You will see three columns:name, engine, path.
Path is where it is stored.
If you want to use base SAS to see this table, you will need to create a library with the same name because that table tree3_train is a view.
For the workspace in your example you would do
libname EMWS1 "<your path>";
Can you see all your observations now?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I am sorry for being a pest here. But it does not seem to be worrking. I do the following steps:
First, below is a picture of my very basic tree. You can see that I have my data, a data partition, then the tree.
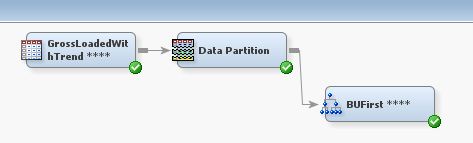
I then click on the ellipsis next to Exported data. And it looks like the following:
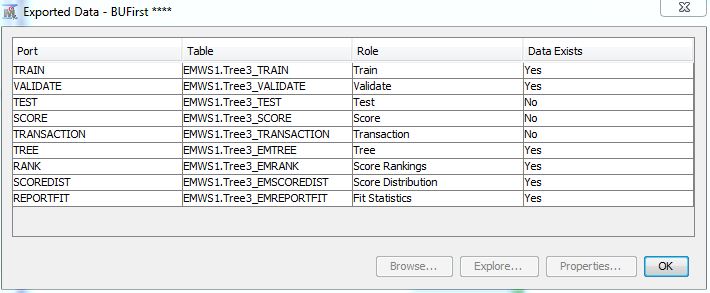
I then click on the first row for TRAIN. I am not going to click on Explore because we already know it samples 10,000 here and I really do not want that. Instead I make note of the Table. It is EMWS1.Tree3_TRAIN. I just need to find where this is.
So I click out of the Window and go to to View/Explorer. As suggested I click on the box to show the project data. And there is the EMWS1 library:
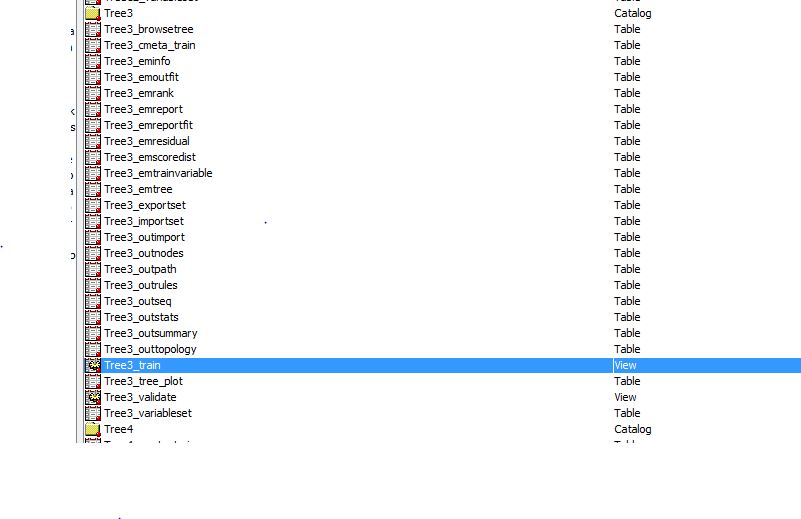
But the problem is there does not seem to be a Tree3 dataset with the predicted and validated columns in it.
If I double-click on Tree3_Train View it looks like the following:
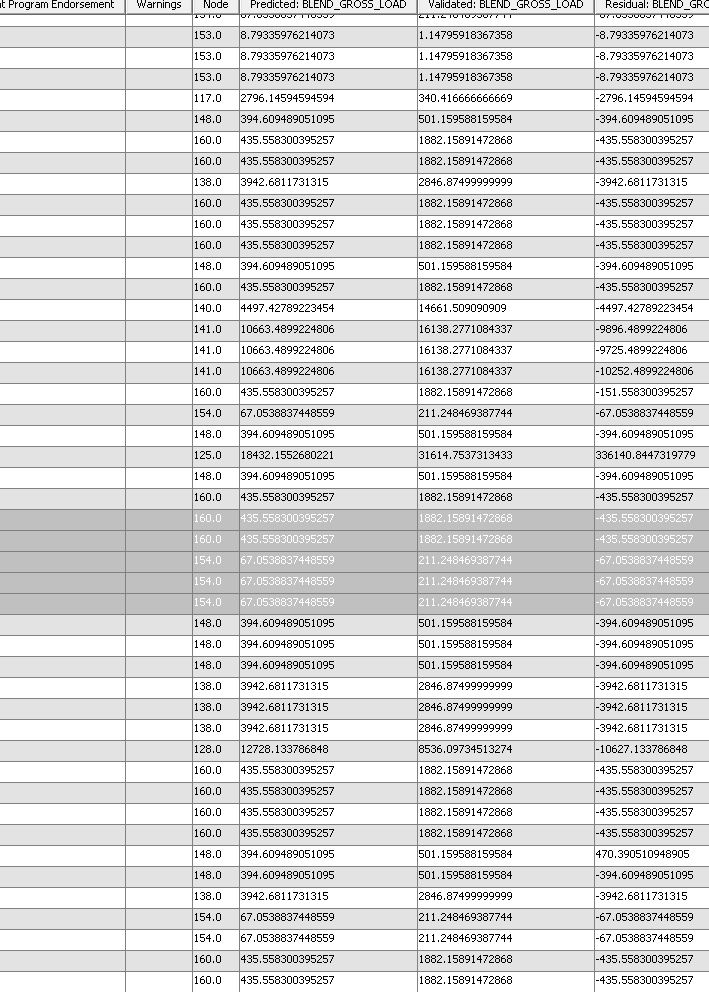
But that only has 2,000 rows, but it has the Predicted & Validated columns - just a View thought - not a SAS file to be used.
Thank you again. Lot of help needed. Please let me know if you need more info.
Ultimately I would like to save a data file with 3 columns - Predicted, Validated, and an ID that I could tie back to my original file.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks.
The example seems great. One question - what is the name of the Export from the Decision Tree?
For the example you provided it is EM_IMPORT_DATA but that is for a Cluster Analysis.
Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You can keep em_import_data because that is the data set that comes into the SAS Code node. (the decision tree exports it and the SAS code node imports it if that makes sense).
- Add a SAS Code node to your diagram
- Connect your decision tree node to the sas code node.
- Open the SAS code editor of the SAS code node
- Paste the below (change the C:\temp to specify a directory and id for the actual name of your variable id).
%let EXPORT_DIR_NAME= C:\temp; /* An existing directory that you have access to */
%let EXPORT_TABLE_NAME=zach_exported_table; /* Whatever name you want */
libname export "&EXPORT_DIR_NAME";
data export.&EXPORT_TABLE_NAME.;
set &EM_IMPORT_DATA;
keep id p_: v_: ;
run;
5. Run it, and you will have a data set saved with the ID, predicted, and validated columns.
How did that go?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Works perfectly! Thank you again to everyone for the very valuable help & insight!
![]()
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes, indeed... Thank you all!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Also, from that Properties window that you show above, if you click on the Variables tab, then check the box for Label, you will see that "Predicted: ..." is the label for the column P_target that Miguel mentioned. In that Explore view of the table, it is showing the label not the column name so that's why you weren't seeing it as the P_target name.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Use this tutorial as a handy guide to weigh the pros and cons of these commonly used machine learning algorithms.

Find more tutorials on the SAS Users YouTube channel.
-
13 replies
-
11-20-2014 01:45 PM
-
8650 views
-
16 likes
-
3 in conversation
-
