- Home
- /
- Analytics
- /
- SAS Data Science
- /
- Re: SAS DataMiner- Ensemble node
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Greetings everybody,
I'm working on small academic project with Sas DataMiner and I noticed that while I use Ensemble Node to merge results of 4 different classifiers I get "weaker" results than separate classifiers.
My diagram looks like this:
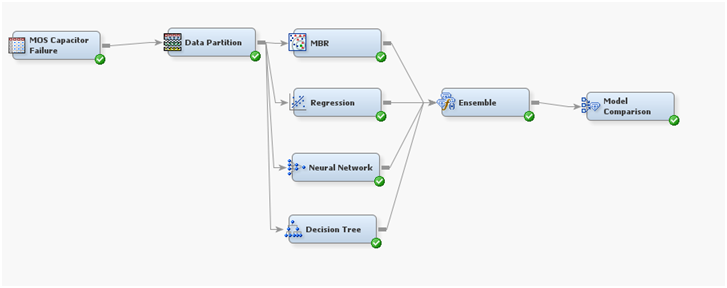
The problem is visible on ROC diagram:
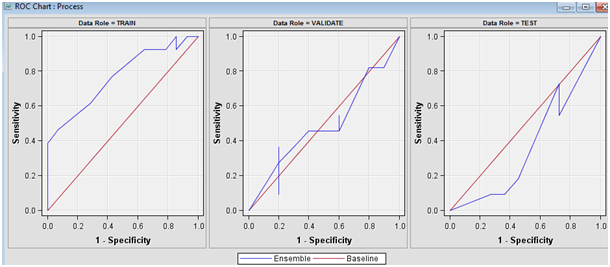
Any ideas? I read that
"It is important to note that the ensemble model that is created from either approach can be more accurate than the individual models only if the individual models differ."
Is it connected with my problem? And why?
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
By default the Ensemble node averages the predicted probabilities of your models.
If you have a class target, you can specify Posterior Probability as Voting. Voting can be done in two ways:
-average. The posterior probabilities of an event are averaged, and the event with higher average predicted probabilities is selected.
-proportion. The proportion of predicted events is selected. Priority is given to the descending level.
To answer your specific question, consider this example. For a given observation these are the posterior probabilities of four models for the levels Yes and No:
| Model | Prob of Yes | Prob of No |
|---|---|---|
| Model 1 | 0.6 | 0.4 |
| Model 2 | 0.7 | 0.3 |
| Model 3 | 0.1 | 0.9 |
| Model 4 | 0.15 | 0.85 |
Ensemble Voting by Average
The average posterior probabilities are 0.3875 for Yes and 0.6125 for No. For this example, the predicted level would be No.
Ensemble Voting by Proportion
This ensemble assigns a predicted probability of 0.5 since two out of four models predict each level. In this tie case, the event Yes is given priority because targets are formatted with descending order by default in Enterprise Miner.
I hope this helps!
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vardens,
Unfortunately you can't know if your Ensemble is going to be better than your models until you try it.
From your plot, it looks like your Ensemble is overfitted. A quick suggestion, connect all the models and the ensemble to the model comparison. Try to identify if there is a model that could be throwing off the Ensemble, and re-run the ensemble node without that model.
Another alternative, do ensembles of 4, 3, and 2 models. I would not try every single combination, but models that have good fit statistics and might be discordant. Not sure if there is a statistical way to test discordance, I usually do try and error.
Let us know how it went!
Thanks,
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Is Ensemble also learning?
I thought it just count the votes:
Let's say I have 4 models: three votes 'yes',, last one 'no'. Shouldn't it answet 'yes'?
And what happends if I have 2x 'yes' and twice 'no'?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
By default the Ensemble node averages the predicted probabilities of your models.
If you have a class target, you can specify Posterior Probability as Voting. Voting can be done in two ways:
-average. The posterior probabilities of an event are averaged, and the event with higher average predicted probabilities is selected.
-proportion. The proportion of predicted events is selected. Priority is given to the descending level.
To answer your specific question, consider this example. For a given observation these are the posterior probabilities of four models for the levels Yes and No:
| Model | Prob of Yes | Prob of No |
|---|---|---|
| Model 1 | 0.6 | 0.4 |
| Model 2 | 0.7 | 0.3 |
| Model 3 | 0.1 | 0.9 |
| Model 4 | 0.15 | 0.85 |
Ensemble Voting by Average
The average posterior probabilities are 0.3875 for Yes and 0.6125 for No. For this example, the predicted level would be No.
Ensemble Voting by Proportion
This ensemble assigns a predicted probability of 0.5 since two out of four models predict each level. In this tie case, the event Yes is given priority because targets are formatted with descending order by default in Enterprise Miner.
I hope this helps!
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you. It helped me a lot

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
For that specific example, 2 out of 4 models select yes, and the other 2 out of 4 select no. For this tie case, where both have 50 % voted probability, Yes is selected because descending levels (alphabetically descending) are given priority by default. You can change this order in the metadata definition.
Thanks,
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Use this tutorial as a handy guide to weigh the pros and cons of these commonly used machine learning algorithms.

Find more tutorials on the SAS Users YouTube channel.
-
6 replies
-
06-15-2015 09:28 AM
-
6705 views
-
4 likes
-
3 in conversation
-
