- Home
- /
- Analytics
- /
- SAS Data Science
- /
- Final Bagged Decision Tree from group processing?
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
I'm a little green when it comes to eminer (and data mining in general). I'm playing around with eminer in an attempt to teach myself how yo use it effectively. I've managed to create a bagged decision tree model using the group processing nodes. How do I see what my final bagged decision tree is? How do I get the decision tree rules of the finale bagged model out of eminer?
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jon,
Maybe I am overthinking what you mean by "rules for the final model by majority vote". Where did you get that idea or definition? As far as I understand there is no voting of the rules on a bagging model, but on the predicted probabilities of each of those models. In your specific example, every observation in your data set will be scored with each of one of the trees in your bagged model. The predicted probabilities of these models are then averaged.
Below a diagram to illustrate what happens behind the scenes (I grabbed it from the paper I mentioned). The actual code in the Start Groups and End Groups nodes is quite more efficient.
Using this alternative diagram you could switch the option in the Ensemble node from averaging to vote. But again, you are voting on the predicted probabilities of each of the models for an observation, not voting on the rules of the models. Whether you combine the predicted probabilities of the models by averaging or by voting, it is the predicted (posterior) probabilities, not the rules.
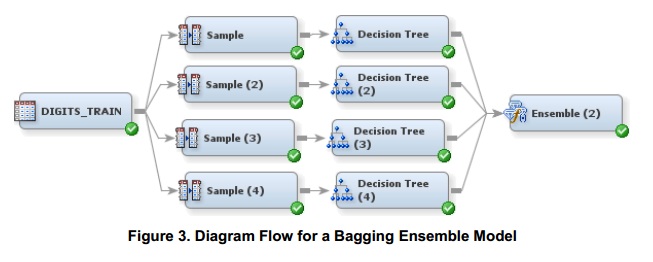
When you have data partition, your models are assessed using a statistic of your validation set. For the specific case of trees, the pruning of the tree model will be based on the validation set.
Are you sure it is not the rules of each model that you want to see? For example, in the figure I pasted you have 4 Decision Trees. You could learn more details of your model by looking at the rules of each tree if you think that adds value, but you cannot combine them into "rules of the final model".
Does this help at all?
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jon,
Smart choice! Ensemble models like bagging and boosting are a great way to start teaching yourself data mining because these models handle well missing values, are more robust than a single decision tree, and do not require preprocessing your variables.
Good news: Add a Score Node after your End Groups node. Run it and go to the results to the optimized sas code output. You will find the scoring code for each decision tree in your bagging model in sections with a header "Decision Tree Scoring Code" and a footnote "End of Decision Tree Scoring Code". You will be able to read the rules from there.
Bad news: These rules may not be in the pretty format that a single decision tree node would give you. You cannot browse through the results and go to Model->Rules because these files got overwritten to make things more efficient.
Need more? Enterprise Miner is really flexible. Give it a try with reading your rules from the score code, and please share how useful/painful you find it. In the meantime I'll think about a workaround for you to make Enterprise Miner save these rules before they get overwritten and how to surface them in a useful way. Depending on your findings we decide how to work this around.
More resources:
| What | Link |
|---|---|
| Good paper for Ensemble Models | Leveraging Ensemble Models in SAS Enterprise Miner |
| Fantastic book for decision trees, it also introduces ensembles | Decision Trees for Analytics Using SAS® Enterprise Miner™ |
| Big data book that is an essential read for data miners, explained in simple terms that make it really useful at introductory level | Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners |
| Course that took me from zero to hero in data mining | Applied Analytics Using SAS Enterprise Miner |
Good luck!
Keep me posted on your findings,
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply!
That is unfortunate. I suppose one approach is to take one of the scored data sets and reverse enginer the groupings based on the node number and the features not found in each node. This works for class variables, but gets a little hazzy for continous variables.
Thanks for all the resources, also! look slike I've got plenty of reading ahead of me.
Thanks!
Jon
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Jon,
You don't need to reverse engineer. While the most common use of the Score node is to score new data, in this example you are using it just to get the score code wrapped up together in a single place.
Just add a Score code to your flow as below, and you will see in the results the rules of each of your trees in very clear sections as I mentioned.

Is this a good solution for what you need?
Thanks,
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Miguel,
I've set up my flow in the same way you've got above (except I partition my data before the start group node) and ran the score node. As expected, I get the rules used for every tree. What I'd like are the rules for the final bagged model. IE the rules selected for the final model by majority vote.
When you run the score node, EM scores your validation and training datasets (if you use a partition node before the start groups node. not sure what it does without one), including adding a node ID. if this is the node ID from the final bagged model, than one could search for the features found in in the full dataset, note which levels are missing within each node ID, and reverse engineer the bagged rules. Am I thinking about this correctlly? Basically I'm looking to get the rules picked via majority vote.
Thanks,
Jon

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
There is no voting on a model when using the Bagging mode of group processing. The final predicted probabilities are obtained by averaging together the predicted probabilities from each loop, so there is no final tree model that goes with those final predictions. There is the concept of "voting" when using the Ensemble node, but that is not voting on a particular model but using a voting method to combine the predicted probabilities from the models together into a single predicted probability per observation when scoring. Hope that helps!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jon,
Maybe I am overthinking what you mean by "rules for the final model by majority vote". Where did you get that idea or definition? As far as I understand there is no voting of the rules on a bagging model, but on the predicted probabilities of each of those models. In your specific example, every observation in your data set will be scored with each of one of the trees in your bagged model. The predicted probabilities of these models are then averaged.
Below a diagram to illustrate what happens behind the scenes (I grabbed it from the paper I mentioned). The actual code in the Start Groups and End Groups nodes is quite more efficient.
Using this alternative diagram you could switch the option in the Ensemble node from averaging to vote. But again, you are voting on the predicted probabilities of each of the models for an observation, not voting on the rules of the models. Whether you combine the predicted probabilities of the models by averaging or by voting, it is the predicted (posterior) probabilities, not the rules.
When you have data partition, your models are assessed using a statistic of your validation set. For the specific case of trees, the pruning of the tree model will be based on the validation set.
Are you sure it is not the rules of each model that you want to see? For example, in the figure I pasted you have 4 Decision Trees. You could learn more details of your model by looking at the rules of each tree if you think that adds value, but you cannot combine them into "rules of the final model".
Does this help at all?
Miguel
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Use this tutorial as a handy guide to weigh the pros and cons of these commonly used machine learning algorithms.

Find more tutorials on the SAS Users YouTube channel.
-
6 replies
-
09-23-2014 10:39 AM
-
5344 views
-
8 likes
-
3 in conversation
-
