- Home
- /
- Solutions
- /
- Data Management
- /
- How to create new values from both current dataset and the other datas...
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
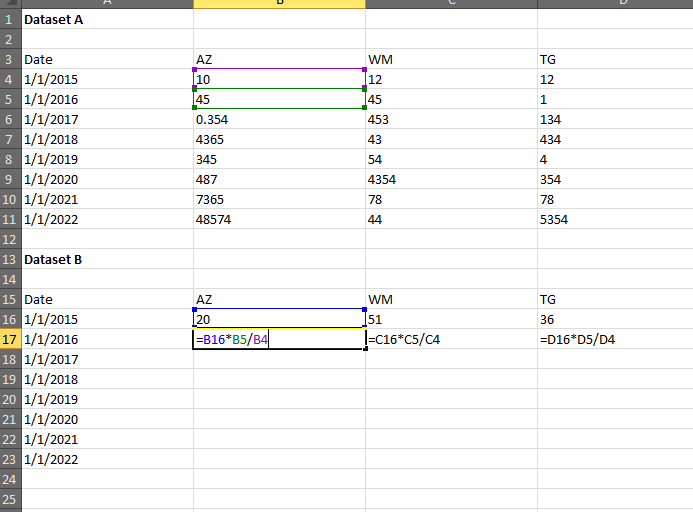
Hi everyone,
I have dataset A and dataset B (only first ob)
So how shall I roll out dataset B like this?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Do you actually have two SAS datasets yet?
Will the datasets have the same number of observations or are all of the records in the first dataset to have the calculation performed with the same in the other?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have dataset A (Full dataset) and dataset b, which only contains the first observation.
And I want my dataset b will rollout like excel does. Yes both datasets will have same numbers of observations at the end.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If both A and B datasets are SAS datasets, you could try to this code to calculate az, similar as wm and tg.
proc sql;
select b.date,b.az*c._az as az from b,(select a.*, a.az/_a.az as _az from a,a _a where a.date+1=_a.date)c
where b.date=c.date;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Looks like B is generated completely from A (other than that first observation in B) ?
Write a data step that sets from A and outputs to B. Use retain statements to hold onto the previous values and manage the a-1, a-2 and b-1 transitions for variables AZ, WM, TG values.
Not all that elegant, but it will work, and work fast 🙂
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes so how to create such a code?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Since the data presented cannot be copy-and-pasted (at least by me), I will make some data.
data t_have1 t_have2;
do row=1 to 10;
AZ = ceil(30*ranuni(3));
WM = ceil(30*ranuni(3));
TG = ceil(30*ranuni(3));
output t_have1;
end;
do row=1 to 1;
AZ = int(30*ranuni(3));
WM = int(30*ranuni(3));
TG = int(30*ranuni(3));
output t_have2;
end;
run;
A solution (amongst others) is the following:
data t_have2(keep=row2 AZ3 WM3 TG3 rename=(row2=row AZ3=AZ WM3=WM TG3=TG));
set t_have1 nobs=n_last;
x1 = lag(AZ); x2=lag2(AZ);
y1 = lag(WM); y2=lag2(WM);
z1 = lag(TG); z2=lag2(TG);
retain AZ3 WM3 TG3;
if _N_=2 then do;
set t_have2(rename=(AZ=AZ2 WM=WM2 TG=TG2));
row2=_N_-1;
AZ3=AZ2;
WM3=WM2;
TG3=TG2;
output;
end;
else if _N_> 2 then do;
row2=_N_-1;
AZ3=round((AZ3*x1/x2),0.1);
WM3=round((WM3*y1/y2),0.1);
TG3=round((TG3*z1/z2),0.1);
output;
if _N_=n_last then do;
row2=_N_;
AZ3=round((AZ3*AZ/x1),0.1);
WM3=round((WM3*WM/y1),0.1);
TG3=round((TG3*TG/z1),0.1);
output;
end;
end;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
So here is a version that sort of honors the spreadsheet like calculations you are doing.
data a;
input az wm tg ;
cards;
10 12 12
45 45 1
0.354 453 134
;;;;
data b ;
input Baz Bwm Btg ;
cards;
20 51 36
;;;;
data want ;
set a ;
lag_AZ=lag(AZ);
lag_WM=lag(WM);
lag_TG=lag(TG);
if _n_=1 then set b ;
else do ;
Baz = Baz*AZ/lag_AZ ;
Bwm = Bwm*WM/lag_WM ;
Btg = Btg*TG/lag_TG ;
end;
keep Baz Bwm Btg ;
run;
proc print; run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Totally agree with that you would need to put a bit more effort into formulating your question and provide us with a starting point for an answer so we don't have to make up everything on our own.
Below some code which might or might not be what you have and what you need. Ideally you would have provided some sample data (data steps creating such data) and then also post how the expected result should look like.
The "trick" in below code is to read the data from the sources in a way that everything required for the calculations ends up on a single row - after that it's simple.
/* create sample data */
data have_A(drop=_:);
format date ddmmyy10.;
do _i=1 to 10;
date=intnx('year','01jan2004'd,_i,'b');
az=_i;
wm=_i*10;
tg=_i*100;
output;
end;
stop;
run;
data have_b;
format date ddmmyy10.;
date='01jan2005'd;
az=20;
wm=51;
tg=36;
output;
stop;
run;
/* create table "want" */
data want(drop=_:);
if _n_=1 then
do;
set have_b;
output;
return;
end;
set have_A(firstobs=1 rename=(az=_az1 wm=_wm1 tg=_tg1));
set have_A(firstobs=2 keep=az wm tg rename=(az=_az2 wm=_wm2 tg=_tg2)) nobs=nobs;
az =az*_az1 /_az2;
wm =wm*_wm1 /_wm2;
tg =tg*_tg1 /_tg2;
output;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Need to connect to databases in SAS Viya? SAS’ David Ghan shows you two methods – via SAS/ACCESS LIBNAME and SAS Data Connector SASLIBS – in this video.

Find more tutorials on the SAS Users YouTube channel.
-
9 replies
-
01-23-2015 01:53 PM
-
5156 views
-
0 likes
-
8 in conversation
-
