- Home
- /
- Solutions
- /
- Data Management
- /
- Extracting string part - Capital letters criteria
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
suppose I have a table containing company descriptions:
| comp_desc |
|---|
| ABC Lmtd. text 12 td 9595 |
| 1st U.S. Comp, something something |
| United 12 Inc. fhfhfh 55858 k. DDD F |
From this table I would like to extract the company names. The company names always appear in the beginning of the cell ,and each word of the company name starts with a capital letter.
By intuition, I thought that to extract the company names I need to extract all the words form the beginning of the cell that start with a capital letter until the next word starts with a small (and not including it).
But in some cases the first "word" can be something like "1st", so then I guess that the logic is to extract everything until the first word that starts with a capital letter and everything until the next word starts with a small letter, but I don't know how to implement this logic or if it is even correct.
I would like the new table to include this new column:
| comp_name |
|---|
| ABC Lmtd. |
| 1st U.S. Comp |
| United 12 Inc. |
Thank you!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi
Below Regular Expression will remove everything from the source string as stored in variable "have" beginning with the first lower case letter after a blank.
I doubt that this will return "clean" strings for all the cases in your real data and I suppose you will need to run this in a first go and then specify additional "removal logic" for the "left overs".
data sample;
infile datalines truncover;
input have $60.;
length want $40;
want=prxchange('s/ [a-z].*//o',1,strip(have));
datalines;
ABC Lmtd. text 12 td 9595
1st U.S. Comp, something something
United 12 Inc. fhfhfh 55858 k. DDD F
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Patrick,
thanks for the code, I ran it and it worked fine. But when I proc import my data, where the description is pretty long and run the code, I get something like half of the description that remains, which is much more than what I need.
maybe my code has some problem, here it is:
data sample2;
set a;
want=prxchange('s/ [a-z].*//o',1,strip(business_description_1));
run;
and here is a small sample of my actual result:
| 1 | 1st Centennial Bancorp operates as the bank holding company for 1st Centennial Bank, which offers various commercial and consumer banking products and services in southern California. Its deposit products include checking accounts, savings accounts, money market accounts, time certificates of deposit, and personal accounts. The company’s loan portfolio comprises real estate loans, such as construction loans, lot loans, residential real estate, mini-perm commercial real estate loans, and home mortgages; commercial loans, which include lines of credit, letters of credit, term loans and equipment loans, commercial real estate loans, SBA loans, equipment leasing, and other working capital financing; and auto, home equity, home improvement lines of credit, and personal lines of credit. | 1st Centennial Bancorp Bank, which offers various commercial and consumer banking products and services in southern California. Its deposit products include checking accounts, savings accounts, money |
|---|
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Not sure that I understand what's not working for you. The RegEx I've posted should only return "1st Centennial Bancorp". That's also the result when running below code.
data sample;
infile datalines truncover;
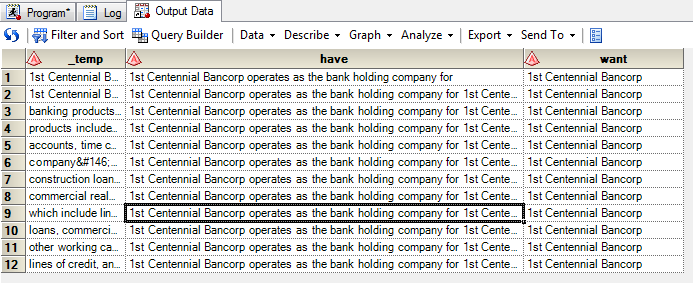
input _temp $256.;
length have $32767;
retain have;
have=catx(' ',have,_temp);
length want $40;
want=prxchange('s/ [a-z].*//o',1,strip(have));
datalines4;
1st Centennial Bancorp operates as the bank holding company for
1st Centennial Bank, which offers various commercial and consumer
banking products and services in southern California. Its deposit
products include checking accounts, savings accounts, money market
accounts, time certificates of deposit, and personal accounts. The
company’s loan portfolio comprises real estate loans, such as
construction loans, lot loans, residential real estate, mini-perm
commercial real estate loans, and home mortgages; commercial loans,
which include lines of credit, letters of credit, term loans and equipment
loans, commercial real estate loans, SBA loans, equipment leasing, and
other working capital financing; and auto, home equity, home improvement
lines of credit, and personal lines of credit.
;;;;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
the example results make it look more like a LOWCASE rule than an UPCASE rule, as 12 is permitted within the company name
Perhaps the rule can be interpreted as the name ends before the first word starting with a lower case letter.
I don't know it that makes any difference, and being no exponent of (perl or SAS) regular expressions, I offer a data step without these.
data sample ;
infile datalines truncover;
input have $60.;
length want $40 ;
*want=prxchange('s/ [a-z].*//o',1,strip(have));
do w=2 by 1 while( scan( have, w ) ne ' ' );
call scan( have, w, pos,len, ' ,' );
if 'a' <= substr( have,pos, 1 ) <= 'z'
then leave;
end;
want = substr( have, 1, pos -1 ) ;
if substr( want, length(want) ) = ',' then
substr( want, length(want) ) = ' ' ;
datalines;
ABC Lmtd. text 12 td 9595
1st U.S. Comp, something something
United 12 Inc. fhfhfh 55858 k. DDD F
;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It is really not easy to get it . You need to know where to stop searching.
data sample;
infile datalines truncover;
input have $60.;
datalines;
ABC Lmtd. text 12 td 9595
1st U.S. Comp, something something
United 12 Inc. fhfhfh 55858 k. DDD F
1st Centennial Bancorp operates as the bank holding company
;
run;
data want;
set sample;
length want temp $ 100;
do i=1 to countw(have,' ');
temp=scan(have,i,' ');
if prxmatch('/\b[a-z]\w*\b/',temp) then leave;
else want=catx(' ',want,temp);
end;
drop i temp;
run;
Xia Keshan
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Need to connect to databases in SAS Viya? SAS’ David Ghan shows you two methods – via SAS/ACCESS LIBNAME and SAS Data Connector SASLIBS – in this video.

Find more tutorials on the SAS Users YouTube channel.
-
5 replies
-
01-24-2015 05:59 PM
-
4674 views
-
0 likes
-
4 in conversation
-
