Background
In this article, we will discover how we could load a Data Vault using Data Vault 2.0 Principles.
In the previous article I described how you could use standard SAS DI Studio transformations to load a Data Vault. We found that hubs and links could use the SCD Type 1 Loader or the Surrogate Key Generator transformations, and that satellites can be loaded with the SCD Type 2 loader transformation. The lookup transformation is used by link and satellite load jobs to pick the surrogate key in the parent table (hub or link). For more details, and a brief introduction to Data Vault, read the article Using SAS DI Studio to Load a Data Vault (part I).
Data Vault 2.0
So what is Data Vault 2.0? It’s an update to the original Data Vault concept promoted by Dan Linstedt. A few of the main development areas are:
- Adoption to NoSQL databases
- Data Vault methodology
- Data Vault and data warehouse architecture
But beside these larger areas of interest, there is one concept which is quite concrete – the use of hash PK in hubs and links. This in contrast to the old school way of using surrogate keys using sequence numbers, and also what we wish to discover in this article, and how that will affect our DI Studio jobs.
So What Is a Hash key?
A hash function is (quote from the omniscient Wikipedia) “…used to map digital data of arbitrary size to digital data of a fixed size”. The result is in binary form, and could be used as a cryptogram – it’s very hard to reverse a hash to its original value. So you could evaluate a supplied password with a stored one, and just in its hashed form. One other core feature of hash function results – which is essential when it comes to use them for PK:s – is that the output is unique given any unique input. Two different inputs does always gives different hash keys. Always? Ok, theoretically it could repeat. However, for a 128 bit hash key this risk could be described as ½^128 which is quite a small risk…
One convenient (and crucial) thing about hash functions is that the result is always the same, given the same input, independent of platform.
Since bit stream data is inconvenient for humans to relate to, it’s common to use hexadecimal formatting.
The most common function is MD5, which results in 128 bit key, which in turn requires 16 bytes of storage. For user with extremely high requirements for uniqueness there are functions that can store larger keys. As of SAS 9.4 M2, the SHA256() function is available which creates a 256 bit hash, which in turn requires a 32 byte character variable.
How Do We Use Hash Keys in Our Data Warehouse?
Change Detection Comparisons
One already established use, is for comparison, like the password example above. The comparison is used to detect changes in SCD Type 2 dimensions, and other tables using versioning. Typically in SAS, it’s the part of the SCD Type 2 Loader functionality. Instead of doing column by column comparisons, it concatenates all transaction columns into one string and applies a hash function. The result is then compared with a corresponding concatenated string of the current row in the target dimension/versioned table. To speed this process up, you could store the current rows hash value in a separate cross reference table. These are some of the features of the SCD Type 2 Loader transformation.
As an Alternative for Sequence No Surrogate Keys
Now, we extend the use. We replace sequence number style surrogate keys with a hash key instead. The hash key is calculated based on the business key. So what can we benefit from using hash keys? Here are two (not limited to) examples:
No More Look-ups
In your satellite or link load job, you got a business key, single or composite. In a job using a traditional technique, you would use that in a look-up operation to a hub or a link table. But since a given argument to a hash function always returns the same result, we don’t need to look-up the key somewhere else. By using a hash function locally in our job, we can be confident that it will match the corresponding key in the hub/link table. This also leads to that we remove the few remaining load order constraints between jobs.
Easier Suspense Management
One common issue in data warehousing, especially in rapid changing environments, is that some records are delivered out of sync with the process that should deliver business keys. One example is that events connected to a subscription is delivered prior to the customer table is updated, which is common in Telco when CDR’s and order records can arrive before the customer master record does.
That means, at least in a Core Data Vault, we could store all our data, even if the corresponding business key is not loaded in the hub. A best practice would be to generate exception reports, and when loading a business layer (Business Data Vault or Data Mart) you need to apply rules how load and report and take these possible exceptions into account. So in this stage, look-ups are probably needed after all…
How Does This Affect Our DI Studio jobs?
Example Model and Recap to Traditional Load
First, let us return to our example model from the previous article.
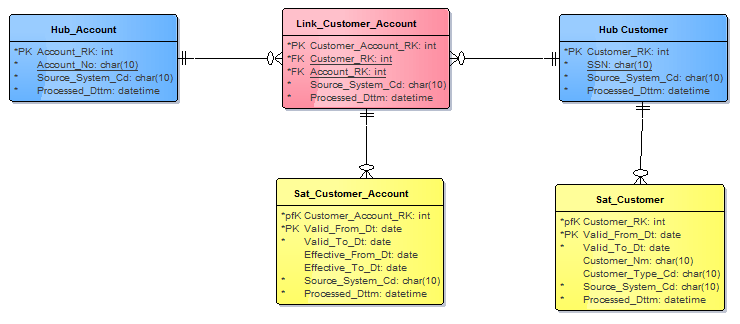
In this model, we use four different load job styles, when using traditional surrogate keys. Quick recap:
- Hubs (blue):
- SCD Type 1 Loader to create hub surrogate key
- Links (red):
- Look-up to get hub surrogate keys, 2-n
- SCD Type 1 Loader to create link surrogate key
- Hub Satellite (yellow):
- Look-up to get its hub surrogate key
- SCD Type 2 Loader to handle versioning
- Link Satellite (yellow):
- Look-up to get the hub surrogate keys, 2-n
- Look-up to get the link surrogate key
- SCD Type 2 Loader to handle versioning
The only change we need to do in the model when going to hash keys, is to change all physical PK/FK from integer to the Char(16) data type.
Load a Hub
As we have discussed above, we can realise that the complexity of the jobs will be even simpler than before, meaning less dependencies and less number of transformations. Let’s see:

So, we got a standard Table Loader. The hash is here defined in a separate Extract step, but could defined in the Table Loader (and thus making the Extract unnecessary).

This shows how the MD5() function is applied in the Extract Mapping tab. As you can see we use the $hex32. format which will make the key slightly more readable.
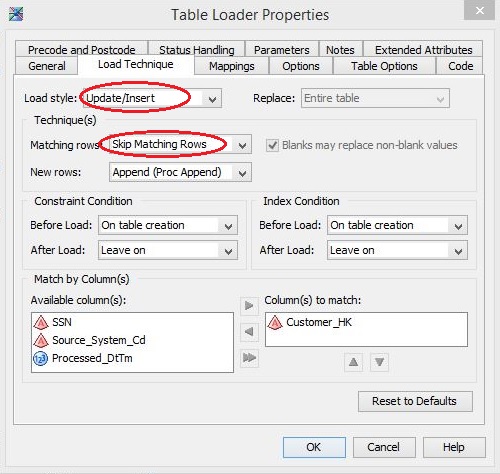
Since we are only interested in new business/hash key pairs, we select “Update/insert” as update method in the Table Loader. Also be sure to select the “Skip matching rows” option to avoid reload of existing business keys. Since hubs are quite easy to load even with the traditional method, we didn’t see much gain there. But the beauty of this concept is the less need for look-ups, which will be clear in the following examples.
Load a Satellite

In this job, we can see that the Look-up has been removed and in its place, we just need to define the hash key. Again, this could be done in the SCD Type 2 Loader instead, but we keep it separately for pedagogical reasons.
The result is that we most probably saved some I/O and CPU cycles by avoiding look-ups.
Load a Link

As we can see in this job, we have two Extract transformations, which reflects the two step hash key generation.
- Create hash key that correspond to the hub hash keys that the link are connected two
- Combine the hub hash keys into a satellite hash key

We just concatenate the hub hash key, and apply MD5() function to it. Since the hash has a fixed length, there is no need to trim or to use any separator.
Do we need to go via the hub hash keys (instead of using the business keys directly)? You could skip that, but I like to have the business key logic separated from the actual creation of link keys. This will leave you with the possibility to have that logic somewhere else in the job flow.
Remember, link surrogate/hash keys are optional. If you don’t (ever) expect a satellite to be connected to the link, it has no use.
Load a Link Satellite

Does this job look similar to the link job? Yes, it does. The only difference is that we exchange the table loader, with an SCD Type 2 to take care of versioning. Loading a link satellite is probably the case that most graphically shows the difference and benefits of using hash keys. We omitted Look-up to at least three hub/link tables.
Conclusions
There are several benefits of using hash keys instead of classical sequence numbers. One is have that we don’t have any dependencies between load jobs any more, at least not in a Core DV. This mean that we potentially can load the whole warehouse in one wave!
From what we can see from the examples given here, it’s very easy to address the hash logic in a SAS DI Studio environment.
Aren’t there any cons? The most obvious is the penalty of column length. This could have some impact in environments where there are many narrow and long tables. And ironically, if you have a large DW with very high number of BK’s, you get punished even more if you feel forced to use SHA256, which would mean a 32 byte key (instead of the classic 8 byte numerical). But for most sites, this shouldn’t be an issue.
Acknowledgements
Saiam Mufti and Siavoush Mohammadi that helped out with creation of the examples and challenging this text.

