- Home
- /
- SAS Communities Library
- /
- 6 hidden SAS Data Management Platform features you may not know about
- RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
6 hidden SAS Data Management Platform features you may not know about
- Article History
- RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
As long time users of the Data Management Platform have discovered, the environment has many features that are handy for routine use but are barely mentioned in the documentation. Here a few of my favorites.
1. Copy and paste properties in SAS Data Management Studio
It will come as no surprise that you can copy and paste property values between different nodes by opening up the node Advanced Properties editor, selecting the advanced property value you are interested in, double-clicking the default value field and right-clicking to copy or paste the value.
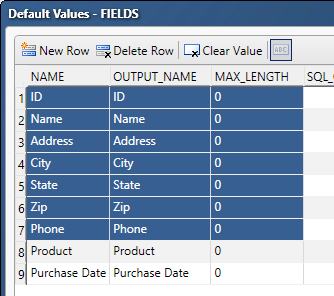
Though it’s not obvious, you can copy entire data grid values sets too. For advanced properties that present a data grid for their properties, simply open the default value and point, click and drag the cursor across all the data grid cells you are interested in. Then use the CTRL+C key combination to copy the values. Navigate to another advanced property data grid in the same node or in a different node, select the top left grid cell and use the CTRL+V key combination to paste the values into the table. The same technique works for advanced properties that use a data grid but do not yet have rows available. Use the “New Row” action first to add the number of rows you need, and then paste the values into the empty table.
This technique is very useful when creating a Job Specific Data node for use in testing your real-time data services. Copy the data row values out of the External Data Provider and paste them into the Job Specific Data node to ensure that the fields expected for the data flow normally provided by the External Data Provider node are also provided by the Job Specific Data node.
2. Serial Target Processing
Let’s say you have a process where you update rows in a database table in one branch of your job and then you need to read the updated rows from that same table in another branch for further processing. Because data management jobs have data streaming through them (data is not completely landed in between discreet nodes in most cases), how can you be sure that your second job branch will be reading all of the updated rows from the first branch? This is where Serial Target Processing comes in.
If you open any data management node in the Advanced Properties node, you will see an “Enable serial target processing” option. If you select that on just one node in your job, it will enable this feature for all nodes. Once selected, small yellow boxes appear on the corner of each node. This is where you set the serial processing order (it can also be done through the Advanced Properties editor). In our example above, you would set the Data Target Update node to 1 and the Data Source input node to 2. The updating of table data in the first node will finish completely before the table data is read out of the Data Source node.
If by the way, this process is meant to be used as a real-time data service, don’t forget to set one of your target nodes (a node with no “child” nodes) as the default target. This lets the Data Management Server know which node data rows will be read as output of the process. The option is “Set as default target node” and can be found using the Advanced Property editor of any node.
3. Programmatic Global Values
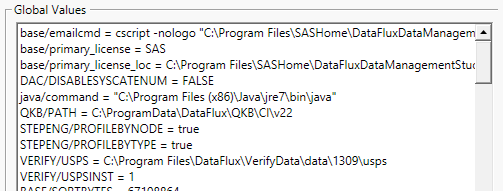
If you open the Tools > Data Management Studio Options > Job > Advanced dialog, you’ll see a large list of Global Values. These provide all kinds of information about the configuration of your Data Management Studio or Data Management Server instance and about the host computer as well. In the course of designing data management jobs you may find it necessary to develop your job logic based on one of these settings. For example, you may write one section of code for when the job is executed on a Windows computer and a different section for when the job is run on a Linux computer.
No problem—you can refer to these global system values in your code by using the getvar() function in an Expression node. For example, the following code would provide information on the operating system on which this job will be run:
string MyMacro //define the variable
MyMacro = getvar("OS") //read the global value into the variable
seteof() //exit the node
If running on a Windows computer, you may see the value “Windows_NT” returned when you run or preview this expression engine code. Remember if you are attempting to do this in a solitary Expression node (one with no parent node providing data rows), set the “Generate rows when no parent is specified” option to see the results of this example code.
If the global value dependent logic is encapsulated in the Expression node with the getvar() function itself, then simply use the output value as a way to execute different parts of your expression code. If you have whole branches on your data job that are dependent on the global value, set a flag in your Expression node logic, place a Branch node after the Expression node and place as many Data Validation nodes as you have branches after the Branch node. Each Data Validation node can then key off the flag value to permit or block data rows from going down each path as the logic of your job dictates.
In addition to “OS” as used in the example above, some of the more useful Global Values are as follows: BASE/TEMP, ProgramData, HOMEPATH, java/command, BASE/EXE_PATH, USERDOMAIN, USERNAME, and SystemDrive.
4. Limiting data source rows
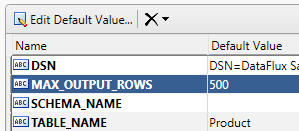
In many of the data input nodes in your data management job, there is an advanced property called MAX_OUTPUT_ROWS. With this property you can instruct the node to only pass the designated number of rows as output to other nodes. This is useful when you are building jobs against large data sets and want to preview the data in Data Management Studio but don’t want to wait for the process to be executed against the entire data set.
This option is visible on the Standard Properties editor for text-based input nodes but is only available on the Advanced Properties editor for SQL-based input nodes like the Data Source node or the SQL Query node.
To enhance the usage of this feature, create a new macro value in Data Management Studio and in Data Management Server with the same name and set the value in each environment to the number of rows with which you want to work. In Data Management Studio you may choose to set the MAX_OUTPUT_ROWS value to 500, for example, which might be a reasonable number of rows to evaluate in the data preview window. On Data Management Server, you might set the same macro value to 0, which would indicate that all rows should be processed. Using this technique, you won’t have to edit the job itself to change the number of rows you want it to process in each environment. In addition, at the time of execution you can provide a maximum output row value to your macro as an input parameter to change the number of rows processed on the fly.
5. Hide Expression node variables
You probably already know that you can create variables in your expression code (sometimes referred to as “symbols” in the documentation) that become new fields available to subsequent nodes of your data flow. This can be very useful when you want to create fields that carry aggregated values, concatenated values or any other calculated data based on data values found in existing fields.
However, sometimes you may want to create a variable that acts simply as a variable in your expression code and you don’t want to make the data it contains available to downstream nodes. A Field Layout node could be used after the Expression node to limit the field list – but instead, it’s better to create the new variable using the “hidden” keyword upon declaration like so:
hidden integer MyInteger
Using this keyword hides the variable from the world outside the Expression node but it is still accessible to other parts of the node itself like the Pre- and Post-Processing areas. Note that this differs from the use of public and private variable declaration keywords. Private variables are not visible outside of the Expression node either, but more specifically they are not visible outside the expression block where they are defined. Hidden variables are visible outside the expression block but are not sent as output of the Expression node to downstream nodes.
6. Connection pooling – the best feature that virtually no one knows about
Connection pooling refers to a condition where multiple SQL-based nodes share the same open connection to the underlying database. One advantage of using this feature is that your jobs may run faster because the Data Management engine doesn’t have to spend time opening up multiple database connections when just one will do.
It’s also less work for the database server. For long-running batch processes, the difference between running with connection pooling on or off is likely to be negligible. But for real-time services where it’s important to save every microsecond to minimize response times, connection pooling can shave a costly second or two off the total. Multiply that across the number of real-time requests your server is processing and you can see what a difference it could make.
Another benefit you get by using connection pooling is that you can enforce a single commit or roll-back for the entire job. Without going into the details, trust me that this is a great thing for database-based processes where you don’t want to leave a transaction in a half-committed state – particularly if something goes wrong in the job and it’s not working correctly.
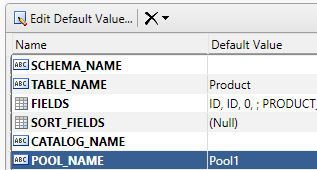
If you are designing a process that necessitates accessing several database tables or views at the same time, you might consider enabling the connection pooling options on various SQL-related nodes in your job. To do this, open up the node in question using the Advanced Properties editor and find the POOL_NAME property. Enter a name for the pool and close the property editor, which will confirm your change. Now on any other SQL-related node that you want to use the same connection, repeat these steps and use the same pool name as you set for the first node. You can have more than one pool in use in a job, just use different names for the additional pools. Keep in mind that except in the case of the SQL Execution node, when a pool name is specified for a node, its commit interval settings will be ignored.
Here are a few things to consider as you incorporate connection pooling into your jobs. See the product documentation for more detailed instructions.
- You must use the SQL execution node to specify how transaction commits and rollbacks are handled for shared connections.
- Some databases will only allow a single result set to be read at a time, so this feature may not work with all database systems.
- When POOL_NAME is set, the DSN information for that node is ignored unless it is the first node encountered for that shared connection.
- You can use connection pooling in Expression node logic by adding the value used for POOL_NAME as a second parameter in the dbconnect function like this: MyConnection=dbconnect(“dsn=DataFlux Sample”,”MyPoolName”)
Now it’s your turn, Data Management Platform maestros! What are your favorite “hidden” features?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Fantastic post!
Thank you for sharing your extensive knowledge of the Data Management Platform with us! These tips will be very useful to all of us in the future.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Can you confirm that Data Management Studio used a 'real' ETL pipeline engine as opposed to DI Studio which basically just creates base code that is handled sequentially?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Data Management Studio and Data Management Server do "stream" data through your data flow rather than landing it in between sequential steps.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →SAS AI and Machine Learning Courses
The rapid growth of AI technologies is driving an AI skills gap and demand for AI talent. Ready to grow your AI literacy? SAS offers free ways to get started for beginners, business leaders, and analytics professionals of all skill levels. Your future self will thank you.
