- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I'm learning about combining datasets vertically using SQL. I'm trying to understand why the output includes a row where X=2 but no row where X=3. Anyone have any idea?
data one;
input X 1. A $1.;
datalines;
1a
1a
1b
2c
3v
4e
6g
;
data two;
input X 1. B $1.;
datalines;
1x
2y
3z
3v
5w
;
run;
proc sql;
select *
from one
except
select *
from two;
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SQL is a set operation language. In general a "SET" of values does not include duplicate values. So it makes no sense to have two exact duplicates be the result of such a set operation.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello @Batman
You are basically asking the SQL processor to exclude records that match two and only output the nonmatches from one
Also, since you didn't use ALL i.e except all, you are telling SQL to do a double pass to exclude duplicate records in the nonmatches from one.
HTH
In essence, this is what you are doing
Set Difference
Difference between sets is denoted by ‘A – B’, is the set containing elements of set A but not in B. i.e all elements of A except the element of B.
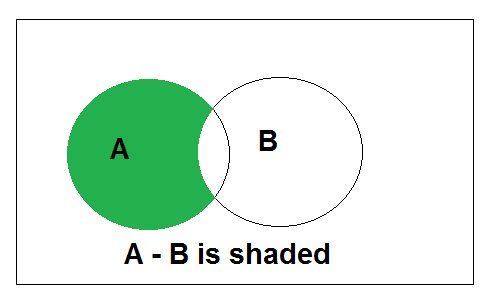
Above is the Venn Diagram of A-B.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Since your only common variable between the data sets is X that is the only variable considered for the comparison. The variable A will not be compared to B for determining inclusion/exclusion with the Except operation.
Name B to A in the set Two and see what happens.
BTW, it is not a good idea to start your datalines with a blank unless you really truly actually want to have a row of missing values.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Contrary to what is stated above (sorry @ballardw), SQL set operations without the CORR keyword operate on columns by positions, not by name. So the comparison involves column A against column B. The names are taken from the first table involved. So 2c is kept because it is different from 2y but 3v is removed because it is present in table two.
Try EXCEPT CORR and see what happens.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
@PGStats wrote:
Contrary to what is stated above (sorry @ballardw), SQL set operations without the CORR keyword operate on columns by positions, not by name. So the comparison involves column A against column B. The names are taken from the first table involved. So 2c is kept because it is different from 2y but 3v is removed because it is present in table two.
Try EXCEPT CORR and see what happens.
I sit corrected. Thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Because '2c' is in one and not in two, but the only value with X=3 in one is '3v' and that value is in two so it is deleted by EXCEPT.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Ok, that makes sense, why is the additional value of "1a" also dropped.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SQL is a set operation language. In general a "SET" of values does not include duplicate values. So it makes no sense to have two exact duplicates be the result of such a set operation.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →- Ask the Expert: Das geht nicht mit SAS! – Doch. Open Source & SAS vereint in Visual Studio Code. | 11-Jun-2026
- Ask the Expert: R and SAS Working Seamlessly Together: Unlocking PROC R in Viya for Life Sciences | 11-Jun-2026
- Ask the Expert: Can Agents Reduce Planning Friction in CPG Supply Chains? | 16-Jun-2026
- Ask the Expert: Mit KI zur Höchstleistung: SAS Studio Copilot in Aktion! | 25-Jun-2026
- Ask the Expert: Get Meaningful Results With New Features in SAS Customer Intelligence 360 | 25-Jun-2026
SAS' Charu Shankar shares her PROC SQL expertise by showing you how to master the WHERE clause using real winter weather data.

Find more tutorials on the SAS Users YouTube channel.
-
7 replies
-
08-12-2019 04:06 PM
-
3636 views
-
0 likes
-
5 in conversation
-
