- Home
- /
- CoDe SAS German
- /
- Forum
- /
- Betreff: XML Struktur in SAs einlesen
- RSS-Feed abonnieren
- Thema als neu kennzeichnen
- Thema als gelesen kennzeichnen
- Diesen Thema für aktuellen Benutzer floaten
- Lesezeichen
- Abonnieren
- Stummschalten
- Drucker-Anzeigeseite

- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Ich habe in einer Spalte folgende XML Struktur hinterlegt...
<LOG><UPD><O><C>Account</C><V>4711</V></O><U><C>Description</C><P>TBD</P><V>P06B0000_Other Trust Liabilities</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>NONE</V></O><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/10/2018 7:31:00 AM</P><V>4/10/2018 1:29:33 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>Sven4IBM</V></U></UPD></LOG>UPD = Update
O = original
V = value
U = update
...
Momentan wird dieses XML als html mit folgendem VB Script aufbereitet. Ich bin kein VB Experte und hoffe, vielleicht hier jemanden zu treffen, der diese Struktur lesen und in ein SAS Statement umwandeln kann, damit ich die Einzelnen Werte als Spalten ausgeben kann.
If InStr(o, "<LOG><UPD>") Then updtype = "U"
If InStr(o, "<LOG><NEW>") Then updtype = "A"
If InStr(o, "<LOG><DEL>") Then updtype = "D"
If updtype = "A" Then
logHTMLtype = True
s = Replace(s, "<O><C>", "<TR><TD>")
s = Replace(s, "</C><V>", "</TD><TD>")
s = Replace(s, "</V></O>", "</TD></TR>")
s = Replace(s, "<LOG><NEW>", "NEW<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=GRE><B>CURRENT</B></TH></TR>")
s = Replace(s, "</NEW></LOG>", "</TABLE>")
End If
If updtype = "D" Then
logHTMLtype = True
s = Replace(s, "<O><C>", "<TR><TD>")
s = Replace(s, "</C><P>", "</TD><TD>")
s = Replace(s, "</P></O>", "</TD></TR>")
s = Replace(s, "<LOG><DEL>", "DELETED<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=ORA><B>PREVIOUS</B></TH></TR>")
s = Replace(s, "</DEL></LOG>", "</TABLE>")
End If
If updtype = "U" Then
logHTMLtype = True
s = Replace(s, "<O><C>", "<TR><TD>")
s = Replace(s, "<U><C>", "<TR><TD>")
s = Replace(s, "</C><V>", "</TD><TD colspan=2>")
s = Replace(s, "</C><P>", "</TD><TD CLASS=ORA>")
s = Replace(s, "</V></O>", "</TD></TR>")
s = Replace(s, "</P><V>", "</TD><TD CLASS=GRE>")
s = Replace(s, "</V></U>", "</TD></TR>")
s = Replace(s, "<LOG><UPD>", "UPDATED<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=ORA><B>PREVIOUS</B></TH><TH CLASS=GRE><B>CURRENT</B></TH></TR>")
s = Replace(s, "</UPD></LOG>", "</TABLE>")
End If

- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Es sieht aus das die XML met vbs im html umgesetzt wird,
XML aufbereiten ist am einfachsten mit die mapper.
https://documentation.sas.com/?docsetId=engxml&docsetTarget=p1cji2td43rru1n1wi0c3a6n0q9f.htm&docsetV...
Mit die mapper bekommen sie auch die LIbname xml code und mapfile.
14/3 Die link Functioniert bei mir.
SAS® 9.4 XMLV2 and XML LIBNAME Engines: User’s Guide
- s Guide
What Is SAS XML Mapper?
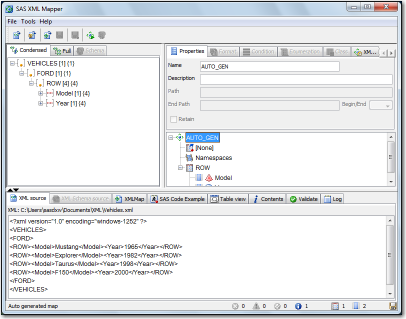
Importing an XML Document with Numeric Values
libname default xml 'C:\Output\precision.xml';
Ein blog: https://blogs.sas.com/content/sgf/2016/06/24/tips-for-reading-xml-files-into-sas-software/
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
https://support.sas.com/downloads/package.htm?pid=713#
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Meine Entschuldigung mit die link, wird nachschauen.
Die Mapper kommt normalweise mit SAS Depot mit. Ein lokale Installation macht es möglich alles darauf zu setzen.
Die Verarbeitung mit XML ist offen nicht bekannt und dann passiert es das es nicht dabei installiert ist.
Die SAS deployment manager ist dat Installation Programm das alle teilen die Software Installation organisiert.
Ihren link ist ein anderen Möglichkeit. Ich sehe Linux und Windows Versionen.
Ohne etwas vom SAS auf eine Rechner zu haben soll es damit auch gelingen ein map file zu generieren. (SAS UE).
Das Profess ist ziemlich einfach wenn die XML Datei einfache Strukturen hat.
1/ XSD (ein Metadaten Beschreibung des XML im XML Struktur) oder
XML , die Datei benutzen als Beispiel. Special Aufmerksamkeit für Ausnahmen benötigt
2/ Mit die MAP-file das XML File verarbeiten mit Resultat ein SAS dataset.
Angesehen das das Resultat ein SAS-dataset möglich ein Teil des originalen XML ist, ist zurückschreiben nicht möglich

- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Hallo Sven4ibm,
in dem Fall sind die Syntaxen zwischen SAS und VB recht ähnlich.
Data test;
length s $32767;
infile cards length=laenge;
input s $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>4711</V></O><U><C>Description</C><P>TBD</P><V>P06B0000_Other Trust Liabilities</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>NONE</V></O><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/10/2018 7:31:00 AM</P><V>4/10/2018 1:29:33 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>Sven4IBM</V></U></UPD></LOG>
run;
%let TRUE = 1;
data result;
set test;
if index(s, "<LOG><UPD>") Then updtype = "U";
If index(s, "<LOG><NEW>") Then updtype = "A";
If index(s, "<LOG><DEL>") Then updtype = "D";
If updtype = "A" Then do;
logHTMLtype = &TRUE.;
s = tranwrd(s, "<O><C>", "<TR><TD>");
s = tranwrd(s, "</C><V>", "</TD><TD>");
s = tranwrd(s, "</V></O>", "</TD></TR>");
s = tranwrd(s, "<LOG><NEW>", "NEW<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=GRE><B>CURRENT</B></TH></TR>");
s = tranwrd(s, "</NEW></LOG>", "</TABLE>");
End;
If updtype = "D" Then do;
logHTMLtype = &TRUE.;
s = tranwrd(s, "<O><C>", "<TR><TD>");
s = tranwrd(s, "</C><P>", "</TD><TD>");
s = tranwrd(s, "</P></O>", "</TD></TR>");
s = tranwrd(s, "<LOG><DEL>", "DELETED<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=ORA><B>PREVIOUS</B></TH></TR>");
s = tranwrd(s, "</DEL></LOG>", "</TABLE>");
End;
If updtype = "U" Then do;
logHTMLtype = &TRUE.;
s = tranwrd(s, "<O><C>", "<TR><TD>");
s = tranwrd(s, "<U><C>", "<TR><TD>");
s = tranwrd(s, "</C><V>", "</TD><TD colspan=2>");
s = tranwrd(s, "</C><P>", "</TD><TD CLASS=ORA>");
s = tranwrd(s, "</V></O>", "</TD></TR>");
s = tranwrd(s, "</P><V>", "</TD><TD CLASS=GRE>");
s = tranwrd(s, "</V></U>", "</TD></TR>");
s = tranwrd(s, "<LOG><UPD>", "UPDATED<BR><TABLE cellpadding=2 cellspacing=1 border=0 bgcolor=gainsboro ><TR><TH>COLUMN</TH><TH CLASS=ORA><B>PREVIOUS</B></TH><TH CLASS=GRE><B>CURRENT</B></TH></TR>");
s = tranwrd(s, "</UPD></LOG>", "</TABLE>");
End ;
run;
VG Jan- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Danke für die Tipps und die Programmierung. Die Programmierung vom Jan bereitet mir das XML das html auf. Ist aber nicht ganz dass, was ich gern möchte. Ich würde gerne die Infos zwischen diesen Tags als Spalten ausgeben wollen und diese dann dem jeweiligen updtype zuordnen. Wenn das überhaupt geht...

- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
hallo Sven,
TranslationAccount, TranslationContra und FundingType müssen entsprechend ihres Datentyps in die Arrays noch eingefügt werden:
Data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>4711</V></O><U><C>Description</C><P>TBD</P><V>P06B0000_Other Trust Liabilities</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>NONE</V></O><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/10/2018 7:31:00 AM</P><V>4/10/2018 1:29:33 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>Sven4IBM</V></U></UPD></LOG>
run;
data daten(drop=string i pos beginn ende);
set testdaten;
array nums (4) $20 _temporary_ ("Account","MAP_A","MAP_B","MAP_C"); * numerische Variablen;
array numv (4) 8 account map_a map_b map_c;
array numvm (4) $1 m_account m_map_a m_map_b m_map_c; * Merkmal O/U;
array chars (2) $20 _temporary_ ("Description","DUserStamp"); * character Variablen;
array charv (2) $200 description duserstamp;
array charvm (2) $1 m_description m_duserstamp; * Merkmal O/U;
* numerische Werte;
do i=1 to dim(numv);
pos = index(string,strip(nums(i)));
numvm(i) = substr(string,pos-5,1);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
numv(i) = input(substrn(string,beginn,ende),?? best.);
end;
* character Werte;
do i=1 to dim(charv);
pos = index(string,strip(chars(i)));
charvm(i) = substr(string,pos-5,1);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
charv(i) = substrn(string,beginn,ende);
end;
* Timestamp;
pos = index(string,"LastChange");
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
lastchange = input(substrn(string,beginn,ende),MDYAMPM.);
format lastchange datetime.;
run;
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Das funktioniert noch nicht so wirklich. In den m_xxxx steht immer nur O. In account, map_a, description und duserstamp steht das richtige. In map_b/c und lastchange nur ein Missing value.
Ich habe den XML Eintrag ... mal aufgeteilt, was in der Html Ansicht zu sehen ist bzw. was in die Spalten der neuen Tabelle eingefügt werden soll.
<LOG><UPD><O><C>Account</C><V>4711</V></O><O><C>Description</C><V>Test account</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/14/2014</P><V>4/15/2014</V></U><O><C>DUserStamp</C><V>Sven4IBM</V></O></UPD></LOG>
UPD = Update
O = original
V = value
U = update
COLUMN PREVIOUS CURRENT
Account 4711 <O><C>Account</C><V>4711</V></O>
Description Test account <O><C>Description</C><V>Test account</V></O>
TranslationAccount NONE <O><C>TranslationAccount</C><V>NONE</V></O>
TranslationContra NONE <O><C>TranslationContra</C><V>NONE</V></O>
FundingType NONE Other Funding <U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U>
MAP_A 50250000 <O><C>MAP_A</C><V>50250000</V></O>
MAP_B NONE <O><C>MAP_B</C><V>NONE</V></O>
MAP_C N/A <O><C>MAP_C</C><V>N/A</V></O>
LastChange 4/14/2018 4/15/2018 <U><C>LastChange</C><P>4/14/2014</P><V>4/15/2014</V></U>
DUserStamp Sven4IBM <O><C>DUserStamp</C><V>Sven4IBM</V></O>
Geht das ?
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
hallo Sven,
das geht schon - natürlich - im SAS geht alles ![]() - aber ich frage mich, worauf das hinauslaufen soll....?
- aber ich frage mich, worauf das hinauslaufen soll....?
Data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>4711</V></O><O><C>Description</C><V>Test account</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/14/2014</P><V>4/15/2014</V></U><O><C>DUserStamp</C><V>Sven4IBM</V></O></UPD></LOG>
run;
data daten(keep=column previous current);
length column $25 previous current $200;
set testdaten;
array name (10) $20 _temporary_ ("Account","Description","TranslationAccount","TranslationContra","FundingType","MAP_A","MAP_B","MAP_C","LastChange","DUserStamp"); * columns;
do i=1 to dim(name);
previous = ""; * initialisieren;
pos = index(string,strip(name(i)));
column = name(i);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
current = substrn(string,beginn,ende);
prev = sum(pos,index(substr(string,pos),"<P>"),2);
if prev < beginn then do;
ende = sum(index(substr(string,prev),"/P"),-2);
previous = substrn(string,prev,ende);
end;
output;
end;
run;
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Danke Heike.
Das sieht schon gut aus. Habe das Ganze noch transponiert, um die Differenzen besser in der Tabelle darzustellen.
proc transpose data=work.daten out=work.Transposed name=Source label=Label;
id column;
var previous current;
run;
Im Previous steht jetzt natürlich nur etwas, wenn auch was geändert wurde. Ist es möglich die Werte aus Current auch nach previous pro Satz zu übertragen, wenn sich nicht verändert (previous leer ist) hat ?
Hintergrund ist eigentlich nur der, dass ich die Daten pro Satz aus der XML Struktur in eine Tabellen Struktur bringen muss, um diese dann auswerten zu können.
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
hallo Sven,
u.U. müssen wir noch mal ganz von vorn anfangen: was soll eigentlich das Ergebnis sein? Vor allem: bei mehreren Datensätzen?
Mann kann natürlich previous mit current belegen, wenn es kein previous gibt:
Data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>4711</V></O><U><C>Description</C><P>TBD</P><V>P06B0000_Other Trust Liabilities</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>NONE</V></O><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/10/2018 7:31:00 AM</P><V>4/10/2018 1:29:33 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>Sven4IBM</V></U></UPD></LOG>
run;
data daten(keep=column previous current);
length column $25 previous current $200;
set testdaten;
array name (10) $20 _temporary_ ("Account","Description","TranslationAccount","TranslationContra","FundingType","MAP_A","MAP_B","MAP_C","LastChange","DUserStamp"); * columns;
do i=1 to dim(name);
previous = ""; * initialisieren;
pos = index(string,strip(name(i)));
column = name(i);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
current = substrn(string,beginn,ende);
prev = sum(pos,index(substr(string,pos),"<P>"),2);
if prev < beginn then do;
ende = sum(index(substr(string,prev),"/P"),-2);
previous = substrn(string,prev,ende);
end;
else previous = current;
output;
end;
run;
proc transpose data=daten out=work.Transposed name=Source label=Label;
id column;
var previous current;
run;
aber ist das wirklich die Lösung, die Du brauchst?
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Also ich möchte eine Tabelle, wo eine Spalte diese XML Struktur als Text für x Datensätze in eine Tabelle formatieren, die dann pro Datensatz einen vorher (previous) bzw. nachher (current) Satz enthält.
Data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>9490815</V></O><O><C>Description</C><V>Text A other</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/14/2014 9:55:00 AM</P><V>4/14/2014 11:47:03 AM</V></U><O><C>DUserStamp</C><V>SAS4IBM</V></O></UPD></LOG>
<LOG><UPD><O><C>Account</C><V>9490816</V></O><O><C>Description</C><V>Text B other</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/14/2014 10:06:00 AM</P><V>4/14/2014 11:47:14 AM</V></U><O><C>DUserStamp</C><V>SAS4IBM</V></O></UPD></LOG>
run;Bei bereits 2 Datensätze meckert SAs aber schon. Ich vermute bei Transpose.
ERROR: The ID value "Account" occurs twice in the input data set.
NOTE: The SAS System stopped processing this step because of errors.
NOTE: There were 11 observations read from the data set WORK.DATEN.
NOTE: MVA_DSIO.OPEN_CLOSE| _DISARM| STOP| _DISARM| 2019-03-20T10:34:55,754+01:00| _DISARM| WorkspaceServer| _DISARM| SAS| _DISARM| | _DISARM| 20| _DISARM| 159801344| _DISARM| 11| _DISARM| 19| _DISARM| 0| _DISARM| 20832| _DISARM| 0.010000| _DISARM|
0.003333| _DISARM| 1868693695.751078| _DISARM| 1868693695.754411| _DISARM| 0.010000| _DISARM| | _ENDDISARM
WARNING: The data set WORK.TRANSPOSED may be incomplete. When this step was stopped there were 0 observations and 0 variables.
NOTE: MVA_DSIO.OPEN_CLOSE| _DISARM| STOP| _DISARM| 2019-03-20T10:34:55,755+01:00| _DISARM| WorkspaceServer| _DISARM| SAS| _DISARM| | _DISARM| -1| _DISARM| 159801344| _DISARM| 11| _DISARM| 19| _DISARM| 8| _DISARM| 20840| _DISARM| 0.010000| _DISARM|
0.004049| _DISARM| 1868693695.751829| _DISARM| 1868693695.755878| _DISARM| 0.010000| _DISARM| | _ENDDISARM
WARNING: Data set WORK.TRANSPOSED was not replaced because this step was stopped.
NOTE: PROCEDURE| _DISARM| STOP| _DISARM| 2019-03-20T10:34:55,756+01:00| _DISARM| WorkspaceServer| _DISARM| SAS| _DISARM| | _DISARM| 162426880| _DISARM| 159801344| _DISARM| 11| _DISARM| 19| _DISARM| 8| _DISARM| 20840| _DISARM| 0.010000| _DISARM|
0.006516| _DISARM| 1868693695.750271| _DISARM| 1868693695.756787| _DISARM| 0.010000| _DISARM| | _ENDDISARM
NOTE: PROCEDURE TRANSPOSE used (Total process time):
real time 0.00 seconds
cpu time 0.01 seconds- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
hallo Sven,
die Fehlermeldung kommt von proc transpose. Es fehlt die by-Variable.
Kannst Du (konkret) aufschreiben, wie das Ergebnis zu den beiden Datensätzen aussehen soll?
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
hallo Sven,
Du könntest zur eindeutigen Kennzeichnung des Datensatzes seine Nummer verwenden:
data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><UPD><O><C>Account</C><V>4711</V></O><U><C>Description</C><P>TBD</P><V>P06B0000_Other Trust Liabilities</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>NONE</V></O><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/10/2018 7:31:00 AM</P><V>4/10/2018 1:29:33 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>Sven4IBM</V></U></UPD></LOG>
<LOG><UPD><O><C>Account</C><V>4711</V></O><O><C>Description</C><V>Test account</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><U><C>FundingType</C><P>NONE</P><V>Other Funding</V></U><O><C>MAP_A</C><V>50250000</V></O><O><C>MAP_B</C><V>NONE</V></O><O><C>MAP_C</C><V>N/A</V></O><U><C>LastChange</C><P>4/14/2014</P><V>4/15/2014</V></U><O><C>DUserStamp</C><V>Sven4IBM</V></O></UPD></LOG>
run;
data daten(keep=datensatz column previous current);
length column $25 previous current $200;
set testdaten;
array name (10) $20 _temporary_ ("Account","Description","TranslationAccount","TranslationContra","FundingType","MAP_A","MAP_B","MAP_C","LastChange","DUserStamp"); * columns;
datensatz = _n_;
do i=1 to dim(name);
previous = ""; * initialisieren;
pos = index(string,strip(name(i)));
column = name(i);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
current = substrn(string,beginn,ende);
prev = sum(pos,index(substr(string,pos),"<P>"),2);
if prev < beginn then do;
ende = sum(index(substr(string,prev),"/P"),-2);
previous = substrn(string,prev,ende);
end;
else previous = current;
output;
end;
run;
proc transpose data=daten out=work.Transposed name=Source label=Label;
by datensatz;
id column;
var previous current;
run;
- Als neu kennzeichnen
- Lesezeichen
- Abonnieren
- Stummschalten
- RSS-Feed abonnieren
- Kennzeichnen
- Anstößigen Inhalt melden
Ich möchte die Infos aus der XML Struktur jeweils in Spalten transferieren. Allerdings klappt das mit dem hier gezeigten letzten Beispiel von Heide nur, wenn es sich um Account handelt und um UPD.
Bei NEW und DEL wird erst gar nichts gefüllt und wenn es sich nicht um Account sondern um eine andere Rubrik (PRTF) handelt, schreibt SAS das XML in jede Spalte.
HIer mal Beispielsätze...
data testdaten;
length string $32767;
infile cards length=laenge;
input string $varying. laenge;
cards;
<LOG><DEL><O><C>Account</C><P>1014701</P></O><O><C>Description</C><P>Due to/from PFS DUSS</P></O><O><C>TranslationAccount</C><P>NONE</P></O><O><C>TranslationContra</C><P>NONE</P></O><O><C>FundingType</C><P>Other Funding</P></O><O><C>MAP_A</C><P>11050010</P></O><O><C>MAP_C</C><P>N/A</P></O><O><C>LastChange</C><P>7/10/2014 11:07:00 AM</P></O><O><C>DUserStamp</C><P>yum</P></O></DEL></LOG>
<LOG><NEW><O><C>Account</C><V>9300529</V></O><O><C>Description</C><V>Asset/Liab Interim acc. GDGC</V></O><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>Other Funding</V></O><O><C>MAP_A</C><V>10950001</V></O><O><C>MAP_B</C><V>OTHASSE/_______</V></O><O><C>MAP_C</C><V>N/A</V></O><O><C>LastChange</C><V>4/22/2014 2:56:59 PM</V></O><O><C>DUserStamp</C><V>TreacyR</V></O></NEW></LOG>
<LOG><UPD><O><C>Account</C><V>3009123</V></O><U><C>Description</C><P>TBD</P><V>Non-Recurr Exp-wages</V></U><O><C>TranslationAccount</C><V>NONE</V></O><O><C>TranslationContra</C><V>NONE</V></O><O><C>FundingType</C><V>Other Funding</V></O><O><C>MAP_A</C><V>40150001</V></O><U><C>LastChange</C><P>7/1/2015 7:30:00 AM</P><V>7/7/2015 4:22:16 PM</V></U><U><C>DUserStamp</C><P>BUILD</P><V>yum</V></U></UPD></LOG>
<LOG><DEL><O><C>PRTF</C><P>02270</P></O><O><C>PRTFTYPE</C><P>HE</P></O><O><C>DESCR</C><P>GEM Forfaiting Neutral</P></O><O><C>ProfitCenter</C><P>GEM Forfaiting Neutral</P></O><O><C>FXTranslation</C><P>True</P></O><O><C>AddBalanceYN</C><P>True</P></O><O><C>COFCalc</C><P>True</P></O><O><C>COFSweep</C><P>False</P></O><O><C>LoanFundingOverWrite</C><P>NONE</P></O><O><C>DUserStamp</C><P>CHO</P></O><O><C>LastChange</C><P>10/31/2002 2:11:00 PM</P></O><O><C>MoveRetainedEarnings</C><P>True</P></O><O><C>BusPrtf</C><P>Neutral</P></O></DEL></LOG>
<LOG><NEW><O><C>PRTF</C><V>43200</V></O><O><C>DESCR</C><V>Finance Services NY</V></O><O><C>ProfitCenter</C><V>PFS Finance Services NY</V></O><O><C>FXTranslation</C><V>True</V></O><O><C>AddBalanceYN</C><V>True</V></O><O><C>COFCalc</C><V>True</V></O><O><C>COFSweep</C><V>True</V></O><O><C>LoanFundingOverWrite</C><V>NONE</V></O><O><C>DUserStamp</C><V>BUILD</V></O></NEW></LOG>
<LOG><UPD><O><C>PRTF</C><V>13169</V></O><U><C>DESCR</C><P>TBD</P><V>Personal NY</V></U><U><C>ProfitCenter</C><P>TBD</P><V>PFS Neutral</V></U><O><C>FXTranslation</C><V>True</V></O><O><C>AddBalanceYN</C><V>True</V></O><O><C>COFCalc</C><V>True</V></O><O><C>COFSweep</C><V>True</V></O><O><C>LoanFundingOverWrite</C><V>NONE</V></O><O><C>DUserStamp</C><V>BUILD</V></O><O><C>LastChange</C><V>2/28/2015 7:31:00 AM</V></O><O><C>MoveRetainedEarnings</C><V>True</V></O><O><C>BusPrtf</C><V>TBD</V></O></UPD></LOG>
run;Ich habe dann mal versucht, die Modi in eine Tabelle jeweils pro gefundener Rubrik zu schreiben und die dann mittels Code zu verarbeiten. Klappt aber nicht.
proc sql;
create table Testfile as select * FROM DWIMPORT.DNMCLOG
where KVAL in ('FUNCSAVERECORD', 'FUNCSAVERECORDLIST')
and DFIELDLIST not like 'DURATION:%'
order by DFIELDLIST, LOGTIME;
quit;
/* -> 2.816 rows and 14 columns */
data NEW DEL UPD Rest;
set Testfile;
if substr(DFIELDLIST,1,10) = '<LOG><NEW>' then output NEW;
else if substr(DFIELDLIST,1,10) = '<LOG><DEL>' then output DEL;
else if substr(DFIELDLIST,1,10) = '<LOG><UPD>' then output UPD;
else output Rest;
run;
%macro Aufteilung(Modus);
data Account_&Modus. BranchID_&Modus. BusinessGroupType_&Modus. FXTranslation_&Modus. ID_&Modus. Locale_&Modus. PRTF_&Modus. RefreshUntill_&Modus. Rest_&Modus.;
set &Modus.;
if substr(DFIELDLIST,14,14) = '<C>Account</C>' then output Account_&Modus.;
else if substr(DFIELDLIST,14,15) = '<C>BranchID</C>' then output BranchID_&Modus.;
else if substr(DFIELDLIST,14,24) = '<C>BusinessGroupType</C>' then output BusinessGroupType_&Modus.;
else if substr(DFIELDLIST,14,13) = '<C>Locale</C>' then output Locale_&Modus.;
else if substr(DFIELDLIST,14,11) = '<C>PRTF</C>' then output PRTF_&Modus.;
else output Rest_&Modus.;
run;
%mend;
%Aufteilung(NEW);
%Aufteilung(DEL);
%Aufteilung(UPD);
data daten(keep=datensatz column previous current);
length column $25 previous current $200;
set testdaten;
array name (10) $20 _temporary_ ("Account","Description","TranslationAccount","TranslationContra","FundingType","MAP_A","MAP_B","MAP_C","LastChange","DUserStamp"); * columns;
datensatz = _n_;
do i=1 to dim(name);
previous = ""; * initialisieren;
pos = index(string,strip(name(i)));
column = name(i);
beginn = sum(pos,index(substr(string,pos),"<V>"),2);
ende = sum(index(substr(string,beginn),"/V"),-2);
current = substrn(string,beginn,ende);
prev = sum(pos,index(substr(string,pos),"<P>"),2);
if prev < beginn then do;
ende = sum(index(substr(string,prev),"/P"),-2);
previous = substrn(string,prev,ende);
end;
else previous = current;
output;
end;
run;
proc transpose data=daten out=work.Transposed name=Source label=Label;
by datensatz;
id column;
var previous current;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →- Ask the Expert: R and SAS Working Seamlessly Together: Unlocking PROC R in Viya for Life Sciences | 11-Jun-2026
- Ask the Expert: Can Agents Reduce Planning Friction in CPG Supply Chains? | 16-Jun-2026
- Ask the Expert: Get Meaningful Results With New Features in SAS Customer Intelligence 360 | 25-Jun-2026
-
15 Antworten
-
am 03-08-2019 07:11 AM
-
9161 Aufrufe
-
16 Kudos
-
4 in Unterhaltung
-
