- Home
- /
- Analytics
- /
- Stat Procs
- /
- NEGBIN Regression in COUNTREG and GENMOD
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I am wondering if guidance/suggestions can be offered about the comparability of results for negative binomial regression from GENMOD and COUNTREG in SAS 9.3.
I am using a Statistics Canada public use microdata file with non-integer weights.
I know that GENMOD uses GLM-style coding for classification variables but is this also true for COUNTREG? (It appears to be so but I have seen no documentation to that effect though an example strongly hints that this is so.)
Resulting parameter estimates look different (signs are same but magnitudes different in the 1st or 2nd decimal place). I am using defaults in both procedures (Newton-Raphson in COUNTREG and I assume a maximum likelihood in GENMOD); both procedures converge. Though I am quite content to accommodate such differences, is there a general preference of one procedure over the other based on the default algorithms and types of data?
More interestingly, COUNTEG has a ‘probcount’ keyword in its output statement of the "probability of the response variable taking particular values." But no such facility appears in GENMOD. GENMOD can provide the mean of "the predicted probability that the response variable is less than or equal to the value of _LEVEL_ if the multinomial model for ordinal data is used (in other words, Pr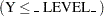 , where Y is the response variable)," which is manifestly not the same as the output from COUNTREG. If I wanted to get the equivalent of PROBCOUNT from GENMOD is there a macro that would enable me to do so?
, where Y is the response variable)," which is manifestly not the same as the output from COUNTREG. If I wanted to get the equivalent of PROBCOUNT from GENMOD is there a macro that would enable me to do so?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It is likely that the two procedures are reporting different parameterizations of the distribution. In terms of SAS definition of the distribution found here :
the expected count is mu=n*p/(1-p) and the variance of the counts is sigma2 = n*p/(1-p)**2 .
When you fit a NEGBIN(P=2) in COUNTREG, the relationship between the counts and their variances is modelled as Sigma2 = mu + Alpha*mu**2. Thus, for an estimated count (mu = exp(X'*Beta)) and value of Alpha, the parameters of the distribution are: n = 1/Alpha, p = 1/(1+Alpha*mu).
But, when you fit a NEGBIN(P=1), the relationship between the counts and their variances is modelled as Sigma2 = mu + Alpha'*mu (that's Alpha prime). Thus, for an estimated count (mu) and value of Alpha', the parameters of the distribution are: n = mu/Alpha', p = 1/(1+Alpha'). (Note: the simple fact that there are two ways to fit a negative binomial in COUNTREG already warns us that we should be more cautious when fitting that distribution.)
I haven't checked the parameterization fitted by proc GENMOD. It uses the same default link (log) as COUNTREG, but I wouldn't expect its parameter k to be the same as COUNTREG's Alpha described above.
I hope this helps more than it confuses...
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks PG - the recent SAS book on overdispersion, which had not arrived when I posted this question, also proved quite useful in this regard.
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →ANOVA, or Analysis Of Variance, is used to compare the averages or means of two or more populations to better understand how they differ. Watch this tutorial for more.

Find more tutorials on the SAS Users YouTube channel.
-
2 replies
-
05-07-2012 02:22 PM
-
3239 views
-
3 likes
-
2 in conversation
-
