- Home
- /
- Analytics
- /
- Stat Procs
- /
- Re: Collapsing data using (arrays)
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi all
Could anyone please help me with this:
I have a data set that looks like this:
| Person | Earning | Date |
|---|---|---|
| 1 | 12 | 2001-01-23 |
| 1 | 34 | 2001-02-03 |
| 1 | 23 | 2001-02-25 |
| 2 | 45 | 2001-03-04 |
| 2 | 32 | 2001-03-27 |
| 3 | 7 | 2001-04-04 |
| 3 | 34 | 2001-05-05 |
| 3 | 65 | 2001-05-26 |
| 3 | 33 | 2001-06-06 |
| 3 | 23 | 2001-07-02 |
| 4 | 33 | 2001-02-03 |
| 4 | 12 | 2001-03-05 |
What I am trying to do is the following
| Person | Sum Earning | Earning Period |
|---|---|---|
| 1 | total sum for person 1 | Last earning date - First earning day person 1 |
| 2 | total sum for person 2 | Last earning date - First earning day person 2 |
| 3 | total sum for person 3 | Last earning date - First earning day person 3 |
| 4 | total sum for person 4 | Last earning date - First earning day person 4 |
I a guess this would be done through arrays but I am really clueless....
Could anyone please help me with the code??
Kind regards
ammarhm
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I hope this is what you need as the output.
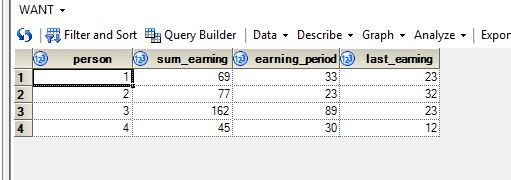
data have;
input person earning Date;
format Date yymmdd10.;
informat Date yymmdd10.;
datalines;
1 12 2001-01-23
1 34 2001-02-03
1 23 2001-02-25
2 45 2001-03-04
2 32 2001-03-27
3 7 2001-04-04
3 34 2001-05-05
3 65 2001-05-26
3 33 2001-06-06
3 23 2001-07-02
4 33 2001-02-03
4 12 2001-03-05
;
run;
proc sql;
create table want1 as
select distinct person, sum(earning) as sum_earning,max(date)-min(date) as earning_period
from have
group by person;
quit;
proc sql;
create table want2 as
select distinct person, earning as last_earning
from have
group by person
having date=max(date);
quit;
data want;
merge want1(in=a) want2(in=b);
by person;
if a=b;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You don't need arrays.
infile cards4 dsd firstobs=2;
input person earning date :mmddyy.;
format date mmddyy.;
cards;
Person,Earning,Date
1,12,1/23/2001
1,34,2/3/2001
1,23,2/25/2001
2,45,3/4/2001
2,32,3/27/2001
3,7,4/4/2001
3,34,5/5/2001
3,65,5/26/2001
3,33,6/6/2001
3,23,7/2/2001
4,33,2/3/2001
4,12,3/5/2001
;;;;
run;
proc print;
run;
proc summary data=person nway;
class person;
output out=summary sum(earning)=earning min(date)=min max(date)=max;
run;
data summary;
set summary;
period = max-min;
run;
proc print;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Great one data_null
Much appreciated
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Just another question
Would you be so kind and tell me how to add another column to the output dataset showing the last earning per person?
Kind regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
To add the last earning date column
data have;
input person earning Date;
format Date yymmdd10.;
informat Date yymmdd10.;
datalines;
1 12 2001-01-23
1 34 2001-02-03
1 23 2001-02-25
2 45 2001-03-04
2 32 2001-03-27
3 7 2001-04-04
3 34 2001-05-05
3 65 2001-05-26
3 33 2001-06-06
3 23 2001-07-02
4 33 2001-02-03
4 12 2001-03-05
;
run;
Edited:
proc sql;
create table want1 as
select distinct person, sum(earning) as sum_earning,max(date)-min(date) as earning_period,
max(date) as max_date format yymmdd10.
from have
group by person;
quit;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Hima
I was looking into having the last earning (not the last earning date)
Any suggestions? The proc sql is a great option
Kind regards
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You mean the last earning for person 1 is 23 person 2 is 32 etc...
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes exactly, thanks in advance
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The real reason is that I want to modify the table so I would get the sum of all earnings per person excluding the last one, so I thought I might do a sum(earning)-last earning
you get the point, i am sure
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I hope this is what you need as the output.
data have;
input person earning Date;
format Date yymmdd10.;
informat Date yymmdd10.;
datalines;
1 12 2001-01-23
1 34 2001-02-03
1 23 2001-02-25
2 45 2001-03-04
2 32 2001-03-27
3 7 2001-04-04
3 34 2001-05-05
3 65 2001-05-26
3 33 2001-06-06
3 23 2001-07-02
4 33 2001-02-03
4 12 2001-03-05
;
run;
proc sql;
create table want1 as
select distinct person, sum(earning) as sum_earning,max(date)-min(date) as earning_period
from have
group by person;
quit;
proc sql;
create table want2 as
select distinct person, earning as last_earning
from have
group by person
having date=max(date);
quit;
data want;
merge want1(in=a) want2(in=b);
by person;
if a=b;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes that can be done with PROC SUMMARY IDGROUP.
infile cards4 dsd firstobs=2;
input person earning date :mmddyy.;
format date mmddyy.;
cards;
Person,Earning,Date
1,12,1/23/2001
1,34,2/3/2001
1,23,2/25/2001
2,45,3/4/2001
2,32,3/27/2001
3,7,4/4/2001
3,34,5/5/2001
3,65,5/26/2001
3,33,6/6/2001
3,23,7/2/2001
4,33,2/3/2001
4,12,3/5/2001
;;;;
run;
proc print;
run;
proc summary data=person nway;
class person;
output out=summary(drop=_:) sum(earning)=earning min(date)=min
idgroup(max(date) out(date earning)=max lastearning);
run;
data summary;
set summary;
period = max-min;
run;
proc print;
run;
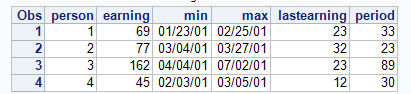

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
NULL ,
You can use RANGE as well.No need to overwrite the table .
proc summary data=person nway; class person; output out=summary sum(earning)= range(date)= /autoname; run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Good point. I have modified.
infile cards4 dsd firstobs=2;
input person earning date :mmddyy.;
format date mmddyy.;
cards;
Person,Earning,Date
1,12,1/23/2001
1,34,2/3/2001
1,23,2/25/2001
2,45,3/4/2001
2,32,3/27/2001
3,7,4/4/2001
3,34,5/5/2001
3,65,5/26/2001
3,33,6/6/2001
3,23,7/2/2001
4,33,2/3/2001
4,12,3/5/2001
;;;;
run;
proc print;
run;
proc summary data=person nway;
class person;
output out=summary(drop=_:) sum(earning)=earning min(date)=min range(date)=period
idgroup(max(date) out(date earning)=max lastearning);
format period: ;
run;
proc print;
run;
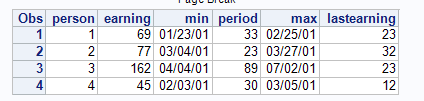

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
proc sort data=have;
by person date;
run;
data want(drop=date earning);
set have;
by person date;
retain first_earning_date;
format first_earning_date last_earning_date ddmmyy10.;
if first.person then do;
sum_earning=0;
first_earning_date=date;
end;
sum_earning+earning;
if last.person then do;
last_earning_date=date;
output;
end;
run;
proc print data=want;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data have;
input person earning Date;
format Date yymmdd10.;
informat Date yymmdd10.;
datalines;
1 12 2001-01-23
1 34 2001-02-03
1 23 2001-02-25
2 45 2001-03-04
2 32 2001-03-27
3 7 2001-04-04
3 34 2001-05-05
3 65 2001-05-26
3 33 2001-06-06
3 23 2001-07-02
4 33 2001-02-03
4 12 2001-03-05
;
run;
proc sql;
create table want as
select distinct person, sum(earning) as sum_earning,max(date)-min(date) as earning_period
from have
group by person;
quit;
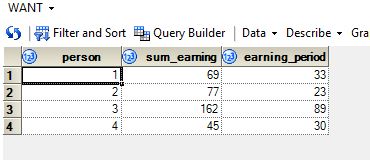
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →ANOVA, or Analysis Of Variance, is used to compare the averages or means of two or more populations to better understand how they differ. Watch this tutorial for more.

Find more tutorials on the SAS Users YouTube channel.
-
15 replies
-
09-08-2014 03:25 PM
-
7153 views
-
7 likes
-
5 in conversation
-
