- Home
- /
- Programming
- /
- Programming
- /
- Re: iterations and unique Id's
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
acct_nbr custid
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
a1 changed custid 2 times and has two unique custid's
a2 changed custid 3 times but has 3 unique custid's
a3 changed custid 4 times but has 2 unique custid's

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I suppose you can do it in one data step, however it would be easier if break down to several:
data have;
input acct_nbr $ custid $;
cards;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;
/*unique id*/
proc sql;
create table id as
select acct_nbr, count (distinct custid) as ct_id from have group by acct_nbr;
quit;
/*switching counts*/
data switch;
set have;
by acct_nbr notsorted;
ct_switch + (custid ne lag(custid));
if first.acct_nbr then
ct_switch=0;
if last.acct_nbr then
output;
run;
proc sql;
create table want as
select a.*, b.ct_switch from id a, switch b where a.acct_nbr=b.acct_nbr;
quit;
Haikuo

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I think it is easier if you BY ID CUST NOTSORTED.
input id :$2. cust:$3.;
cards;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;;;;
run;
data change;
set cust;
by id cust notsorted;
if first.id then change = -1;
if first.cust then change + 1;
if last.id then output;
drop cust;
run;
id=a1 change=2
id=a2 change=3
id=a3 change=4

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Combine data view and SQL :
data have;
input acct_nbr $ custid $;
datalines;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;
data testv(sortedby=acct_nbr) / view=testv;
set have;
dif_cust = acct_nbr = lag(acct_nbr) and custid ne lag(custid);
run;
proc sql;
select
acct_nbr,
sum(dif_cust) as nbChange,
count(distinct custId) as nbUnique
from testv
group by acct_nbr;
quit;
PG

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Here is one-step solution. It does have one assumption that you don't have more than 100 obs per acct_nbr, although it can easily modified, but only Hash can offer you a true robust solution in one step. However, this is already verbose enough ![]()
data have;
input acct_nbr $ custid $;
cards;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;
data want;
array cus(100) $ 3 _temporary_;
do _n_=1 by 1 until(last.acct_nbr);
set have;
by acct_nbr notsorted;
if custid not in cus then
do;
unique_id+1;
cus(_n_)=custid;
end;
ct_switch + (custid ne lag(custid));
if first.acct_nbr then
ct_switch=0;
if last.acct_nbr then
do;
output;
call missing(unique_id,of cus(*));
end;
end;
drop custid;
run;
Haikuo
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Nice and compact. However, I think you meant cus(unique_id)=custid; instead of cus(_n_)=custid;
PG
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data have;
input acct_nbr $ custid $;
_custid=input(compress(custid,,'kd'),best.);
cards;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;
data want (keep=acct_nbr change);
set have;
by acct_nbr _custid notsorted;
if first.acct_nbr then change=0;
if not first.acct_nbr and _custid-lag(_custid) ne 0 then change+1;
if last.acct_nbr then output;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data want(drop=temp custid);
set have;
by acct_nbr notsorted;
length temp $50;
retain temp;
if first.acct_nbr then do;
change=0;
temp=catx(' ',temp,custid);
end;
if not first.acct_nbr and custid^=lag(custid) then do;
change+1;
if indexw(temp,custid)=0 then temp=catx(' ',temp,custid);
end;
if last.acct_nbr then do;
count=countw(temp);
output;
call missing(temp);
end;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
one data step if you were care about speed.
data have;
input acct_nbr $ custid $;
datalines;
a1 c11
a1 c11
a1 c12
a1 c11
a2 c21
a2 c23
a2 c21
a2 c24
a3 c31
a3 c32
a3 c31
a3 c32
a3 c31
;
run;
data want(drop=custid);
if _n_ eq 1 then do;
if 0 then set have;
declare hash h();
h.definekey('custid');
h.definedone();
end;
set have;
by acct_nbr;
if custid ne lag(custid) then changed+1;
if first.acct_nbr then changed=0;
h.replace();
if last.acct_nbr then do;
unique=h.num_items;output; h.clear();
end;
run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ksharp.
If we add a date diemnsion on which the custid changed, how to get the result based on the month the cust id changed. for instance,
a1 c11 20Jun2013
a1 c11 15Jul2013
a1 c12 08Aug2013
a1 c11 25Aug2013
acct june2013 july2013 Aug2013 changed unique
a1 0 0 1 3 2
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I don't understand what you mean . need some more data and explanation .
and what these three variables(june2013 july2013 Aug2013) stand for ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
acctnbr custid date
a1 c11 20Jun2013
a1 c11 15Jul2013
a1 c12 08Aug2013
a1 c11 25Aug2013
the custid for acctnbr a1 and the date on which it is either updated or changed.
in june2013 there is no change in custid
in july2013 there is no change in custid
in aug2013 there is a change in custid
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
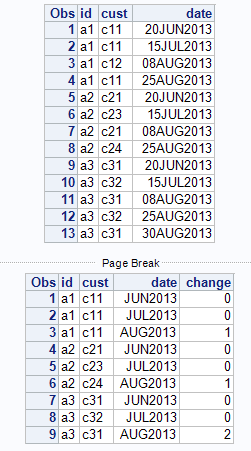
The by statement has a feature for that GROUPFORMAT. Note the FORMAT MONYY.
input id :$2. cust:$3. date:date9.;
format date date9.;
cards;
a1 c11 20Jun2013
a1 c11 15Jul2013
a1 c12 08Aug2013
a1 c11 25Aug2013
a2 c21 20Jun2013
a2 c23 15Jul2013
a2 c21 08Aug2013
a2 c24 25Aug2013
a3 c31 20Jun2013
a3 c32 15Jul2013
a3 c31 08Aug2013
a3 c32 25Aug2013
a3 c31 30Aug2013
;;;;
run;
proc sort data=cust;
by id date;
run;
proc print;
run;
data change;
set cust;
by id date cust notsorted groupformat;
format date monyy7.;
if first.date then change = -1;
if first.cust then change + 1;
if last.date then output;
run;
proc print;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sure . No problem . after it , merge WANT back .
data cust; input id :$2. cust:$3. date:date9.; format date date9.; cards; a1 c11 20Jun2013 a1 c11 15Jul2013 a1 c12 08Aug2013 a1 c11 25Aug2013 a2 c21 20Jun2013 a2 c23 15Jul2013 a2 c21 08Aug2013 a2 c24 25Aug2013 a3 c31 20Jun2013 a3 c32 15Jul2013 a3 c31 08Aug2013 a3 c32 25Aug2013 a3 c31 30Aug2013 ;;;; run; data temp; set cust; by id date notsorted groupformat; format date monyy7.; if cust ne lag(cust) then changed+1; if first.date then changed=0; if last.date; run; proc transpose data=temp out=want(drop=_:) ; by id; id date; var changed; run;
Xia Keshan
Message was edited by: xia keshan
Message was edited by: xia keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data cust;
input id :$2. cust:$3. date:date9.;
format date date9.;
cards;
a1 c11 20May2013
a1 c11 15Jul2013
a1 c12 08Jan2014
a1 c11 25Apr2014
a1 c11 25May2014
a1 c11 25Jun2014
a1 c11 25Jul2014
a2 c21 20Jun2013
a2 c23 15Jul2013
a2 c21 08Aug2013
a2 c24 25Apr2014
a3 c31 20Jun2013
a3 c32 15Jul2013
a3 c31 08Aug2013
a3 c32 25Feb2014
a3 c31 30Jul2014
;;;;
run;
The cut of dates are 01may2013 to 31Jul2014. Need to look at the pattern of custid change in rolling 12 months as shown below
id May-Apr Jun-May Jul-Jun Aug-jul
a1 1 1 1 1
a2 3 3 2 2
a3 3 3 2 2
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
16 replies
-
08-08-2014 04:39 PM
-
7489 views
-
2 likes
-
8 in conversation
-
