- Home
- /
- Programming
- /
- Programming
- /
- Re: Search Information in Strings
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I need a way to identify specific information. The data looks like the following.
publisher_name publisher_id book_id book_name word_count
The book_name contains either the subject itself or a phrase that promotes the book.
e.g. ABC Corp 1234 A888888 College Math 2
ABC Corp 1234 A666666 Math for Beginners 3
ABC Corp 1234 A555555 Business Math for Starters 4
ABC Corp 1234 A333333 Math4Thinkers 1
ABC Corp 1234 A222222 Math 1
ABC Corp 1234 A000000 GoMath 1
ABC Corp 1234 A999999 Math Learning 2
ABC Corp 1234 B888888 Art 1
ABC Corp 1234 A888888 Multi Cultural Art 3
I need a way to identify subject keyword (e.g. Math, Art are the keywords)
So for 1-word book_name, two possibilities: subject itself (Math) or word containing the subject (Math4Thinkers, GoMath).
2-word book_names, two possibilities: 2-word subjects (Natural Science, Political Science) or phrase containing 1-word subject (Math Learning, College Math, Environmental Law).
3-word book_names, three possibilities: 3-word subjects (Early Childhood Education, Criminal Justice System), phrase containing 1-word subject (Multi Cultural Art), or phrase containing 2-word subject (Natural Science Guide).
and so on....The longest string contains n words.
The search is done at the publisher level.
Also, most subjects are short, the longer strings are usually phrase promoting the book. Phrase could contain the subject (NYT best selling book XYZ Art) or not related to the subject (NYT best selling XYZ Romance book but does not contain the word Romance). Those phrases not containing the subject can be treated as a separate subject.
I need a way to search for subject keywords using the algorithm, so that the output will be something like
publisher_name publisher_id book_id book_name keyword
ABC Corp 1234 A888888 College Math Math
ABC Corp 1234 A666666 Math for Beginners Math
ABC Corp 1234 A555555 Business Math for Starters Math
ABC Corp 1234 A333333 Math4Thinkers Math
ABC Corp 1234 A222222 Math Math
ABC Corp 1234 A000000 GoMath Math
ABC Corp 1234 A999999 Math Learning Math
ABC Corp 1234 B888888 Art Art
ABC Corp 1234 A888888 Multi Cultural Art Art
I thought of a way although I am not sure if it is the only way or the correct way.
For subject titles get a subset of the data containing only 1-word, then either the title is a subject (Math), or a title containing the subject (Math4Thinkers). Sort 1-word title based on string length, checking from the shortest string (a subject), then check the next obs. and see if it the same as the last obs. If the next obs. is the same as the last, then it is also a subject, if it is the same length but different, then mark it as a new subject. When moving to the next length (e.g. 4-letter), check against every 3-letter word to see if it contains 3-letter subject. If not, mark it as 4-letter subject, and so forth. For n-letter 1-word subject, check against 1, 2, ..., n-1 letter subjects in the 1-word subset.
Use 2-word only title to check against 1-word title to see if any word in 2-word title matches keywords generated from the 1-word title. Those do not match will probably be 2-word title. Then use 3-word title to check against 1-word title and against 2-word title in the same way, and so on....For n-word brands, check against 1, 2, ..., n-1 brand.
Do NOT worry about two subjects appearing in the same title (the data does not include such circumstance).
I think the problem can be applied in other cases, so I am really interested to know what is the most efficient code to carry out the procedure. Does SAS have some short-cut to get it done in a few steps (like proc expand does for moving avg.)?
Thanks in advance!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It would be helpful if you could reference your very similar previous posts when asking a new question.
I believe your approach is too simplistic and it would help if you could tell us what you really have as starting point and what you really need to achieve in the end.
Just a few titles found on Amazon:
- The Art of Mathematics in Business
- Secrets of Mental Math: Master the Art of Mental Math
- The Art of Mathematics
- Math and the Mona Lisa: The Art and Science of Leonardo da Vinci
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the message. I actually want to remove the last post since I didn't find the correct answer under a different section. But I am not sure how to do it as I am new.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I wouldn't remove posts for which you've got already people answering you. Just write some explanation why you're closing it, reference to the follow up post if applicable and then mark the question as "answered". Then start your new post with a follow-up question and reference the old post.
This way people can follow you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
What is the sophisticated method in you opinion to approach this problem? Your thoughts greatly appreciated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I believe it really depends on what you have as data source and what you actually are trying to achieve here.
Librarians are since a long time registering and classifying books and my current thinking is that you shouldn't try to re-invent the wheel but to figure out how to access this information. I would assume that there are multiple database with such information where you could retrieve such information via a look-up over the book titles you're having. So it's more about researching what exists, where it's free-of-charge or at least "low cost" and what's required technically (the api).
My starting points would be the Library of Congress and Amazon.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the suggestions. I think another member also mentioned this point in a previous post. I appreciate your thoughts on the matter. However, I am very interested in a solution that has application to other similar scenario. Suppose we change a setting, instead of books, we are looking at grocery items. And if there is no list of grocery items, then what in your opinion is a sophisticated way to approach the problem? I think the issue is interesting, and I am curious to know if there is some proc or function SAS offer (other than SAS data mining) that can accomplish the objective.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well, also for grocery items there are data bases (eg. from Nielsen). I don't think there is (and can't be) a single ready made SAS procedure for such tasks - but you can of course always implement your own logic. For the forum here: You will have to give it a try first and then eventually ask specific questions for specific problems where you get stuck. To give you a start below some code which "cleans up" your book titles in a way that it's may be easier to work out the key words you're after.
data sample;
infile datalines truncover dsd dlm=',';
input (publisher_name publisher_id book_id) ($) book_name :$30. keyword_test :$20.;
length book_words $30.;
book_words=prxchange('s/([[:upper:]][[:lower:]]*)|([^[[:upper:]]]*)/\1 /o',-1,book_name);
book_words=compbl(book_words);
datalines;
ABC Corp,1234,A888888,College Math,Math
ABC Corp,1234,A666666,Math for Beginners,Math
ABC Corp,1234,A555555,Business Math for Starters,Math
ABC Corp,1234,A333333,Math4Thinkers,Math
ABC Corp,1234,A222222,Math,Math
ABC Corp,1234,A000000,GoMath,Math
ABC Corp,1234,A999999,Math Learning,Math
ABC Corp,1234,B888888,Art,Art
ABC Corp,1234,A888888,Multi Cultural Art,Art
;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the update. I think the code performs upcase, compress function in one line.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Execute it and you will see what it does with stuff like "GoMath".
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for replying. I tried the code, and GoMath remained to be GoMath. It made the string all uppercase and removed punctuations and numbers.
Was it supposed to be a different output?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If I run the code exactly as posted then GoMath gets split into 2 words separated by a blank "Go Math" which then should be much easier to analyse (eg. a record by word and then a simple frequency count to retrieve key word candidates).
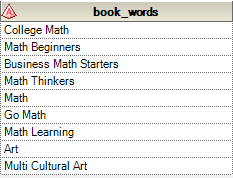
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
11 replies
-
03-14-2015 09:38 PM
-
3750 views
-
0 likes
-
2 in conversation
-
