- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: PROC FREQ Query?
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have a dataset of dummy variables that look like this -
(Both tables the same - some problems viewing as image)
| Contact | Var1 | Var2 | Var3 | Var4 | Var5 | Var6 |
|---|---|---|---|---|---|---|
| A | 1 | 1 | 1 | 1 | 1 | 1 |
| B | 1 | 1 | ||||
| C | 1 | 1 | 1 | 1 | ||
| D | 1 | 1 | ||||
| E | 1 | 1 | ||||
| F | 1 | 1 |
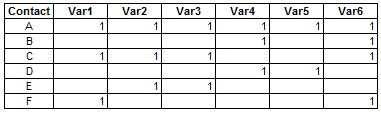
What I need is to do a frequency count of all the variable pairings so that I get a table that looks like this -
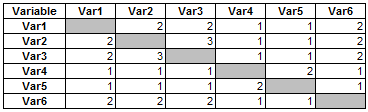
| Variable | Var1 | Var2 | Var3 | Var4 | Var5 | Var6 |
|---|---|---|---|---|---|---|
| Var1 | 2 | 2 | 1 | 1 | 2 | |
| Var2 | 2 | 3 | 1 | 1 | 2 | |
| Var3 | 2 | 3 | 1 | 1 | 2 | |
| Var4 | 1 | 1 | 1 | 2 | 1 | |
| Var5 | 1 | 1 | 1 | 2 | 1 | |
| Var6 | 2 | 2 | 2 | 1 | 1 |
Does anyone have any ideas how to achieve this?
Thanks.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It is really more difficult than i imaged.
data have;
input contact $ var1-var6;
cards;
a 1 1 1 1 1 1
b . . . 1 . 1
c 1 1 1 . . 1
d . . . 1 1 .
e . 1 1 . . .
f 1 . . . . 1
;
run;
data temp(keep= name1 name2);
set have;
length name1 name2 $20 ;
array v{*} var1-var6;
do i=1 to dim(v)-1;
do j=i+1 to dim(v);
if v{i}=1 and v{j}=1 then do;
name1=vname(v{i});
name2=vname(v{j});
output;
end;
end;
end;
run;
proc freq data=temp noprint;
tables name1*name2/out=x(drop=percent) nopercent nocum;
run;
proc sql noprint;
select quote(trim(name)) into : list separated by ','
from dictionary.columns
where libname='WORK' and memname='HAVE' and name like 'var%';
quit;
data xx(keep=name1 name2);
length name1 name2 $20 ;
do name1=&list ;
do name2=&list;
output;
end;
end;
run;
proc sort data=xx;by name1 name2;run;
data t;
merge xx x;
by name1 name2;
_name1=name1;_name2=name2;
run;
data t;
set t;
call sortc(_name1,_name2);
run;
data tt(drop=_:);
if _n_ eq 1 then do;
if 0 then set t;
declare hash ha(dataset:'t');
ha.definekey('_name1','_name2');
ha.definedata('count');
ha.definedone();
end;
set t;
count=.;
rc=ha.find();
run;
proc transpose data=tt out=want(drop=_:);
by name1;
id name2;
var count;
run;
Ksharp

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
No able to view your images.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
It is really more difficult than i imaged.
data have;
input contact $ var1-var6;
cards;
a 1 1 1 1 1 1
b . . . 1 . 1
c 1 1 1 . . 1
d . . . 1 1 .
e . 1 1 . . .
f 1 . . . . 1
;
run;
data temp(keep= name1 name2);
set have;
length name1 name2 $20 ;
array v{*} var1-var6;
do i=1 to dim(v)-1;
do j=i+1 to dim(v);
if v{i}=1 and v{j}=1 then do;
name1=vname(v{i});
name2=vname(v{j});
output;
end;
end;
end;
run;
proc freq data=temp noprint;
tables name1*name2/out=x(drop=percent) nopercent nocum;
run;
proc sql noprint;
select quote(trim(name)) into : list separated by ','
from dictionary.columns
where libname='WORK' and memname='HAVE' and name like 'var%';
quit;
data xx(keep=name1 name2);
length name1 name2 $20 ;
do name1=&list ;
do name2=&list;
output;
end;
end;
run;
proc sort data=xx;by name1 name2;run;
data t;
merge xx x;
by name1 name2;
_name1=name1;_name2=name2;
run;
data t;
set t;
call sortc(_name1,_name2);
run;
data tt(drop=_:);
if _n_ eq 1 then do;
if 0 then set t;
declare hash ha(dataset:'t');
ha.definekey('_name1','_name2');
ha.definedata('count');
ha.definedone();
end;
set t;
count=.;
rc=ha.find();
run;
proc transpose data=tt out=want(drop=_:);
by name1;
id name2;
var count;
run;
Ksharp
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Awesome!! And actually for what I need to do I can simply take the table X created at the top and project solved. Cheers!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Great ksharp....
amazing...
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
He is good!

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I borrowed your data step to create HAVE.
data have;
input contact $ var1-var6;
cards;
a 1 1 1 1 1 1
b . . . 1 . 1
c 1 1 1 . . 1
d . . . 1 1 .
e . 1 1 . . .
f 1 . . . . 1
;;;;
run;
ods listing close;
ods output list=list(keep=table frequency);
proc freq;
tables (var1-var6)*(var1-var6) / list;
run;
ods listing;
data list;
set list;
row=scan(table,2);
col=scan(table,-1);
if row eq col then frequency=.;
run;
proc sort data=list;
by row col;
run;
proc transpose out=square(drop=_name_);
by row;
id col;
var frequency;
run;
proc print;
run;
proc compare base=want compare=square;
run;
Obs row var1 var2 var3 var4 var5 var6
1 var1 . 2 2 1 1 3
2 var2 2 . 3 1 1 2
3 var3 2 3 . 1 1 2
4 var4 1 1 1 . 2 2
5 var5 1 1 1 2 . 1
6 var6 3 2 2 2 1 .
Message was edited by: data _null_
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Great NULL.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yet another way:
data have;
input contact $ var1-var6;
cards;
a 1 1 1 1 1 1
b . . . 1 . 1
c 1 1 1 . . 1
d . . . 1 1 .
e . 1 1 . . .
f 1 . . . . 1
;
proc transpose data=have out=havelist(where=(col1 is not missing));
by contact notsorted;
var var:;
run;
proc sql;
create table haveCounts as
select h1._name_ as variable, h2._name_ as col, count(*) as n
from haveList as h1 inner join haveList as h2
on h1.contact=h2.contact and h1._name_ ne h2._name_
group by h1._name_, h2._name_
order by variable;
drop table haveList;
quit;
proc transpose data=haveCounts out=want(drop=_NAME_);
by variable;
var n;
id col;
run;
/* At this point you have the counts table. Now for presentation : */
option missing="";
proc sql;
drop table haveCounts;
select variable label="Variable", var1, var2, var3, var4, var5, var6
from want;
quit;
PG
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
8 replies
-
03-29-2012 04:47 AM
-
5182 views
-
2 likes
-
6 in conversation
-
