- Home
- /
- Programming
- /
- SAS Procedures
- /
- Re: How to match 2 datasets when 1 of the datasets could be matched on...
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have wrested getting this to work in SAS for many days now. I am about to give up and write this in a language that can handle looping a through multiple arrays at a time, but I love SAS and would much prefer to find something that works, so I am hoping someone will know how to do this in SAS...
I have 2 datasets,
----File 1 has a unique customer identifier (let's call it "account number") and an amount in each record.
----File 2 has 2 unique customer identifiers (let's call it "policy number" and "customer number") and an amount in each record.
The twist? Account number, policy number, and customer number can all be the same number. All 3 are always 8 characters long.
file 1 file 2
-------------------------- ------------------------------------------
12345678 4.50 12345678 98765432 4.50
My goal is to know:
1) what records are: a) on both files where the account number on file 1 equals either the policy number or the customer number on file 2. and b) the amounts are equal.
2) what records are: a) on both files where the account number on file 1 equals either the policy number or the customer number on file 2. and b) the amounts do not equal.
3) what records are only on file 1, meaning that the account number doesn't equal either the policy number or the customer number.
4) what records are only on file 2, meaning that neither the policy number or the customer number match the account number on file 1.
This makes match-merge and proc sql a nightmare of spaghetti code to filter out duplicates. My brain hurts. Can anyone see a way to do this in SAS? Thank you in advance....

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
1) SQL join (accno = policy_no or acc_no = cust_no) and one.amt = two.amt
2) as above, but move the amt join criteria to a case expression in the select statement.
3) as above, but using a left join. Use case expression on a mandatory column in dataset 2 to see if there is a match or not.
4) as above, but using a right join, Or full join, in which you could fulfil all your requirements in one query.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Analyzing, thinking at a SAS datastep.
- You have 4 output files being defined .
- The join: There is a difficult join. accountnumber (a) is to be checked to policy number/customer number. This looks to be 3 file-join not a 2 file join. file1 - file2a - file2b
- 3 and 4 are the outer parts 3= file1 and not file2a and not file2b 4= not file 1 and ( file2a or file2b)
- 1,2 are of the inner part file1 and ( file2a or file 2b)
- The split up on the ammmount being different or equal at the inner part is more easy.
There is a twist possible "the twist": do you have duplicates? can both policy number and customer number being get matched?
Any sample data (faked?) for doing some code?
What is the sizing of the data (relative small or big to your sas environment)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you to everyone who has responded!
Yes, policy number and customer number can both get matched. There could be up to - but no more than - one entry each for both policy number and customer number in file 1, and similarly in file 2 there will be only 1 entry that has either a policy number and customer number that are the same or not the same. The trick is to produce a match only if the amounts match AND there is a match to either policy number or customer number.
The size of the data in comparison to data size I normally deal with is small - about 18,000 records on file 1 compared to about 2,000 records on file 2. I know already there will be a lot of non-matches coming out of file 1, and I expect this. From a business perspective, I am more concerned that each record in file 2 has a match, but I also need to know what didn't get matched from file 1.
I am attaching sample data - 2 csv files.
In this sample data, there should be shown in the output from SAS:
1) one record on file 2 (policy number field) that matches an account number on file 1, and the amounts on each file are equal, so this is a match. (amount of 21.17, 12345678 44445555).
2) one record on file 1 (account number 44445555) whose customer number happens to be the same as the first example, above, and matches to the customer number from file 2. This same customer number just got matched (above) for 21.17, but the amount in file 1 is 125.32, so file 1's record should get treated as a mismatch.
3) one record on file 1 that doesn't have a match in file 2 (amount of 54.67, 22223333). This is a mismatch.
4) one record on file 2 that doesn't have a match in file 1 (amount of 34.98, 11112222 99998888). This is a mismatch.
5) a case (66667777 for 98.77) where all 3 identifiers are the same and the amounts match. This is a match.
6) a case (77778888) where all 3 identifiers are the same, but the amounts don't match. This s a mismatch.
Note that on file 1 there will only ever be up to - but no more than - 1 entry that could correspond to the policy number on file 1, and likewise with regards to customer number from file 2.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Why don't you explore and try the suggestions first, and then get back to us if you need further assistance or for plain feed-back?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
INFILE CARDS DLM=' ';
ATTRIB
account LENGTH=$8
account_amount LENGTH=8
;
INPUT account account_amount;
DATALINES4;
12345678 4.50
88888888 5.50
;;;;
RUN;
DATA WORK.FILE2;
INFILE CARDS DLM=' ';
ATTRIB
policy LENGTH=$8
customer LENGTH=$8
amount LENGTH=8
;
INPUT policy customer amount;
DATALINES4;
12345678 98765432 4.50
98765432 12345678 4.30
99999999 11111111 4.50
;;;;
RUN;
DATA
WORK.RECORDS1(DROP=account_amount)
WORK.RECORDS2
WORK.RECORDS4(DROP=account_amount)
;
SET WORK.FILE2 END=_done;
RETAIN _one 1 _ks 0;
DROP _one _ks;
IF _N_=1 THEN DO;
IF 0 THEN SET WORK.FILE1;
DCL Hash _h(DATASET:'WORK.FILE1', KEYSUM: '_ks', SUMINC: '_one');
_h.defineKey('account');
_h.defineData('account', 'account_amount');
_h.defineDone();
DROP account;
END;
IF _h.Find(KEY:policy) = 0 THEN DO;
IF amount = account_amount THEN
OUTPUT WORK.RECORDS1;
ELSE
OUTPUT WORK.RECORDS2;
END; ELSE IF _h.Find(KEY:customer) = 0 THEN DO;
IF amount = account_amount THEN
OUTPUT WORK.RECORDS1;
ELSE
OUTPUT WORK.RECORDS2;
END; ELSE
OUTPUT WORK.RECORDS4;
IF _done THEN
_h.Output(DATASET: 'WORK.RECORDS3(WHERE=(_ks=0))');
RUN;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The data borrowed above.
DATA WORK.FILE1;
INFILE CARDS DLM=' ';
ATTRIB
account LENGTH=$8
account_amount LENGTH=8
;
INPUT account account_amount;
DATALINES4;
12345678 4.50
88888888 5.50
;;;;
RUN;
DATA WORK.FILE2;
INFILE CARDS DLM=' ';
ATTRIB
policy LENGTH=$8
customer LENGTH=$8
amount LENGTH=8
;
INPUT policy customer amount;
DATALINES4;
12345678 98765432 4.50
98765432 12345678 4.30
99999999 11111111 4.50
;;;;
RUN;
data file1;
set file1;
retain found 0;
run;
data one(drop=found four _account_amount) two(drop=found four _account_amount) three(keep=account account_amount) four(keep=policy customer amount);
if _n_ eq 1 then do;
if 0 then set file1;
declare hash ha1(dataset:'file1');
ha1.definekey('account', 'account_amount');
ha1.definedone();
declare hash ha2(dataset:'file1');
declare hiter hi2('ha2');
ha2.definekey('account');
ha2.definedata(all:'y');
ha2.definedone();
end;
set file2 end=last;
four=1;
account=policy; _account_amount=account_amount; account_amount=amount;
if ha2.check()=0 then do;
found=1;ha2.replace(); four=0;
if ha1.check()=0 then output one;
else do; account_amount=_account_amount;output two; end;
end;
account=customer;
if ha2.check()=0 then do;
found=1;ha2.replace(); four=0;
if ha1.check()=0 then output one;
else do; account_amount=_account_amount;output two; end;
end;
if four then output four;
if last then do;
do while(hi2.next()=0) ;
if not found then output three;
end;
end;
run;
Xia Keshan
Message was edited by: xia keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you everyone! Grateful. I am going to try these out when I get back to work Wednesday and will report back......

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Use this methodology:
data a;
input accnum amount;
datalines;
12345678 4.50
12345679 5.50
12345680 6.50
;
run;
data b;
input plcynum custn amount;
datalines;
12345678 98765432 4.50
12345679 98765431 5.50
12345681 98765432 9.50
;
run;
proc sql;
create table aa as select * from a,b where a.accnum=b.plcynum or a.accnum=b.custn and a.amount=b.amount;
quit;
proc print data=aa;
run;
Output:
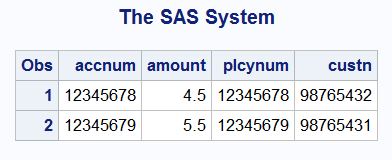
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →Learn the difference between classical and Bayesian statistical approaches and see a few PROC examples to perform Bayesian analysis in this video.

Find more tutorials on the SAS Users YouTube channel.
SAS Training: Just a Click Away
Ready to level-up your skills? Choose your own adventure.
-
8 replies
-
08-31-2014 09:10 PM
-
4098 views
-
0 likes
-
6 in conversation
-
