Data in which most of the values are missing or zero are typically referred to as “sparse.” Tasks such as recommendation and text mining often require the storage and analysis of sparse data. This tip summarizes some SAS approaches for working with sparse data. Two recent SAS Global Forum papers detail storage, feature extraction and classification of sparse data in SAS Enterprise Miner and SAS Text Miner. Both papers also include SAS code examples for handling sparse data.
To avoid wastefully storing a large table consisting of mostly zeros or missing values, many storage formats have been devised to efficiently store only the non-zero or non-missing values in a data set. Some of the most popular formats include:
- List of Lists (LIL)
- Coordinate List (COO)
- Compressed Sparse Row (CSR)
- Compressed Sparse Column (CSC)
Each of these formats presents challenges and advantages, but COO format is probably the best for SAS. There will be one record in a COO format SAS table for each non-zero or non-missing value in the original sparse data set. Each non-zero or non-missing value is represented as a tuple: {row index, column index, value}. The simple diagram below demonstrates mapping a sparse data set to a COO format data set.
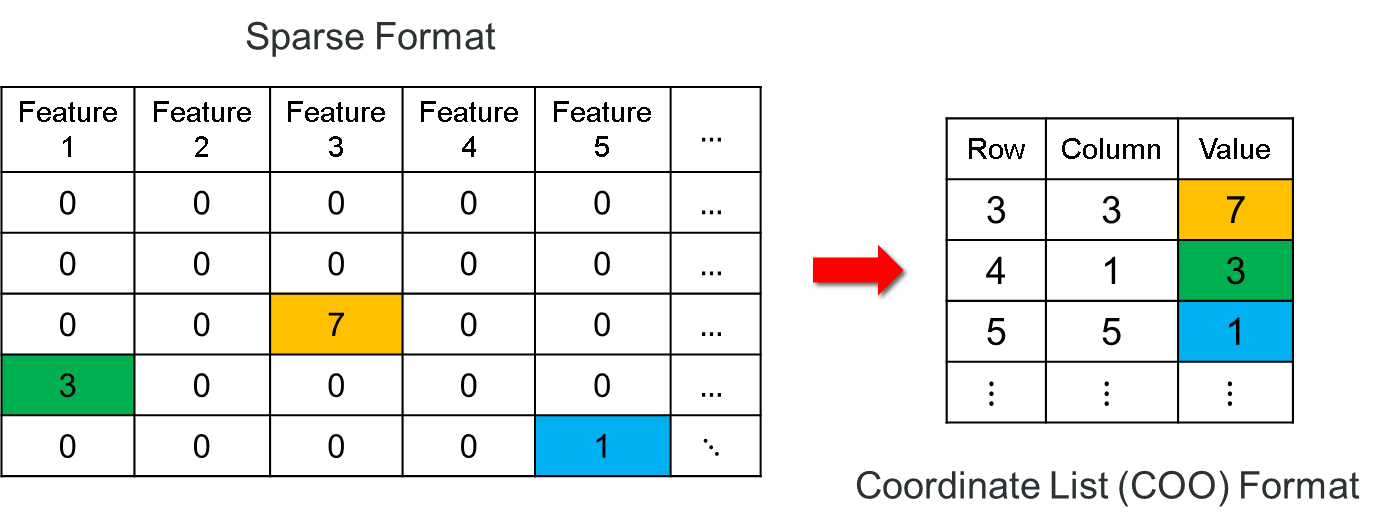
The following SAS procedures can produce or consume a SAS data set in COO format:
- ASSOC (SAS Enterprise Miner)
- HPTMINE (SAS High Performance Text Miner)
- HPTMSCORE (SAS High Performance Text Miner)
- NETFLOW (SAS/OR)
- OPTGRAPH (SAS Social Network Analysis)
- RECOMMEND (SAS In-Memory Statistics for Hadoop)
- RULEGEN (SAS Enterprise Miner)
- SEQUENCE (SAS Enterprise Miner)
- SPSVD (SAS Text Miner)
- TGPARSE (SAS Text Miner)
- TMUTIL (SAS Text Miner)
You can also select representative features directly from the COO format data set. Both papers mentioned above include SAS code examples for selecting important sparse features from COO format data and storing them as a conventional SAS data set. Although the set of selected features will probably be sparse itself, the selected sparse features can often be modeled or preprocessed successfully with an appropriate learning algorithm.
To model the set of selected sparse features directly, try a supervised learning algorithm like a neural network or random forest in SAS Enterprise Miner. Neural networks are available through the HPNEURAL and NEURAL procedures and the AutoNeural, High Performance Neural Network and Neural Network nodes. Random forests are available through the HPFOREST procedure and the High Performance Forest node.
To preprocess the set of selected sparse features, try an unsupervised learning algorithm like Principal Components Analysis (PCA). Preprocessed features can be used with numerous supervised and unsupervised modeling procedures in SAS. Many variants of PCA are available in SAS:
- Traditional PCA - The HPPRINCOMP and PRINCOMP procedures in SAS/STAT and the High Performance Principal Components and Principal Components nodes in SAS Enterprise Miner.
- Singular Value Decomposition - The IML procedure in SAS/IML, the SPSVD procedure and the Text Cluster node in SAS Text Miner, and the HPTMINE procedure and the High Performance Text Mining node in SAS High Performance Text Miner.
- Kernel PCA - Custom solution through Base SAS and SAS/STAT with the CORR, PRINCOMP, and SCORE procedures as documented at http://www.sas-programming.com/search/label/kernel.

