The group processing nodes in SAS® Enterprise Miner™, Start Groups and End Groups, have been shown in previous tips and papers to have many useful applications such as conducting stratified analyses, performing Monte Carlo simulations, and creating ensembles (Maldonado et al. 2014) to enhance your data mining model. You might be surprised to know that most of the High-Performance Data Mining (HPDM) nodes can be included in group processing flows. While there are some limitations to be aware of, incorporating these nodes into your flows can improve performance when dealing with grouped or segmented data, multiple targets, bagging and boosting models, or index looping.
The following options for the Mode property in the Start Groups node are supported:
- Mode = Index works with all HPDM nodes.
In the example group processing flow that was provided in another tip that was posted on using the Index mode to implement Monte Carlo simulations, you can substitute the HP Transform node for the Transform node and any HPDM modeling node for the Decision Tree node, as shown in the flow below, to take advantage of parallel processing on a single machine or across a distributed environment in your simulations.

- Mode = Stratification, Target, or Cross-Validation works with most HPDM nodes.
Here is an example flow for performing a stratified analysis on data in a distributed grid environment using the Start Groups node with Mode = Stratification, the variable REASON assigned the Grouping Role of Stratification, and the HP SVM node with Optimization Method = Interior Point.

The Results window for the HP SVM node displays HPDM assessment statistics such as the ROC curves below that are calculated on the entire data, not just a local sample, across the different strata (DebtCon and HomeImp strata shown here):
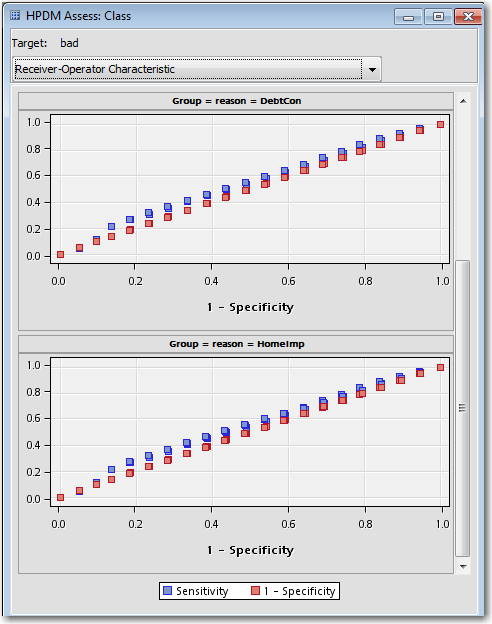
The HPDM nodes that cannot be used with these three looping modes are the HP Cluster node (in releases prior to 14.1), the HP Forest node, and the HP SVM node with the Optimization Method property set to Active Set, due to the format of their scoring code.
- Mode = Bagging or Boosting works with most HPDM modeling nodes in single-machine mode.
While data on a grid cannot be used in a bagging or boosting flow, HPDM nodes can still take advantage of multithreading on a single machine when running these two types of ensemble models. Here is an example flow using the HP Tree node for modeling with Mode=Bagging selected in the Start Groups node.

The improvement in average misclassification rate as the number of model iterations increases is shown below, displayed in the End Groups node Results window:
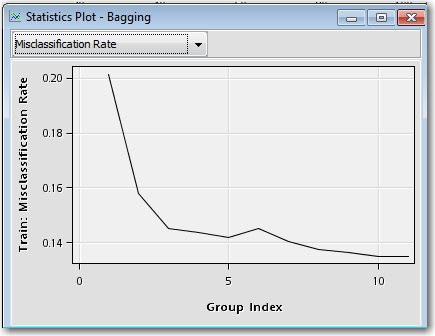
Note that the HP Forest and HP SVM nodes cannot be used with the bagging or boosting modes, on either a single machine or in a distributed environment.
And keep in mind, as with non-HPDM modeling nodes and for all the modes of group processing, assessment tables with the _loop suffix are created containing the model statistics for all loops. You can find these in the EMWS workspace folder by opening the Explorer window in SAS Enterprise Miner, checking the Show Project Data checkbox, and navigating to the EMWS folder for the diagram containing your group processing flow. For example, when an HP Regression node is used in a group processing flow with a binary target, you will see loop tables such as hpreg_emclassification_loop, hpreg_emreportfit_loop, and hpreg_emmisc_loop among others containing the model assessment statistics for a binary target. When running in a distributed environment, the HPDM assessment statistics for each loop are also aggregated in tables, such as hpreg_hpassess_loop and hpreg_hpbinstats_loop. There are some node-specific loop tables available as well; for example, the HP Data Partition node creates an hppart_summary_loop table in the workspace folder that provides the number of observations in the training and validation partitions for each loop, by stratum if stratified partitioning is performed, when included in a group processing flow.
Hope this information helps you with incorporating HPDM nodes into your group processing flow.

