Introduction
In most cases when you build predictive models in SAS® Enterprise Miner™, you build them using the entire training sample (of course checking whether the model generalizes to an independent validation sample). But there may be times when you need to perform separate analyses for different subgroups, or strata. Typically, we stratify an analysis because we want to understand the unique attributes of each stratum. But did you know stratification might help you build a better predictive model? The Enterprise Miner group processing nodes make it easy to build and deploy stratified models.
Your First Stratified Model
Stratification
To stratify your analysis, use the Start Groups and End Groups nodes, which you can find in the Utilities tab. These nodes always work in a pair.
Start with a simple flow like this:

- The input datasource is Home Equity (available via Help >Generate Sample Datasources). The target is Bad, a binary variable that indicates whether a home equity loan was paid off on time. The other columns represent characteristics of loan customers such as reason for the loan and debt-to-income ratio.
- The Data Partition node defines training and validation samples. I set the size of the Test partition to zero.
- The Start Groups and End Groups nodes define the "group processing" portion of a process flow. These nodes actually have several different modes of operation, but the default mode is to stratify the analysis. So if you were to run this flow using the default mode, a separate logistic regression model would be built for each stratum.
But before we can run the flow, we need to define the strata. Right-click on the Start Groups node and choose Edit Variables. This displays a list of categorical variables:

Now, change the Grouping Role for Reason from Default to Stratification.

This defines Reason as the strata variable.
Now run the flow to get a separate regression model for each Reason category.
(Visual feedback provided when the group processing nodes are running reflects cycling through strata. First the Start Groups node runs, then the Regression node, then End Groups. This repeats until each stratum has been processed.)
When processing finishes, examine the results. The End Groups node shows you that three Reason strata have been processed: unspecified (blank), debt consolidation, and home improvement.

Now view results for the Regression node.
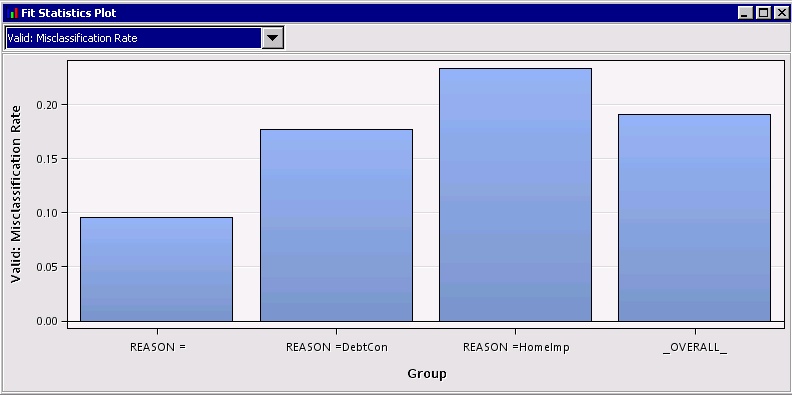
Here, the Fit Statistics Plot graph shows the misclassification rate for the validation sample. There is considerable variation in the misclassification rate among the models for the different the strata, ranging from .095 for the "unspecified" stratum to .233 for the home improvement stratum.
Scoring
When you build separate models for each strata, each of the models contributes strata-specific score code. Thus, if you examine the score code for the Regression node (choose View>Scoring>SAS Code in Results view), you will notice that there are different scoring rules for each Reason category. Here’s an excerpt (just enough to give you an idea):

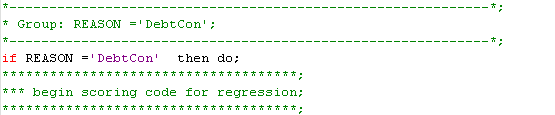

If you were to put the stratified model into production, observations would be scored conditionally based on their Reason value. That makes sense, right? After all, we have built separate models for each Reason category.
Things to Remember
Before we move on to more advanced uses of stratification, here are a few useful things to know when working with the group processing nodes:
- You are not limited to a single strata variable. If you defined both Reason and Job as stratification variables, you would get a separate model for each combination of the categories of Reason and Job.
- When stratifying smaller datasets or using multiple stratification variables to define your strata, the strata can get pretty small—sometimes too small for model building. You can use the Start Group node's Minimum Group Size setting (default=10) to set a minimum count. Strata with counts below the threshold are not processed.
- You can turn off group processing altogether without adjusting your process flow. Just change the Mode setting from Stratify to No Grouping for the Start Groups node. This can be useful when initially setting up or debugging your flows because processing of a large number of groups does take extra time to run. Once you flow is working as expected, set the mode back to Stratify and re-run it.
Comparing the Stratified Model to a Simpler Model
We’ve built separate models that take into account the unique attributes of each Reason stratum. But was this approach worth the added complexity?
Let’s extend our flow to compare the stratified model to a simpler, unstratified Regression model. Here, I’ve added Regression node and a Model Comparison node:

Because the Regression node is placed outside the group processing portion of the flow, it will generate an unstratified model of Bad. The Model Comparison node will compare our stratified and unstratified models. (By the way, I overrode the default Model Selection criteria for the Model Comparison node so it would use Lift in the validation sample at 20% depth.)
Note that the Regression node we just added does not ignore the Reason variable. Since Reason has a default role of Input, the variable will be used as a predictor in the unstratified model.
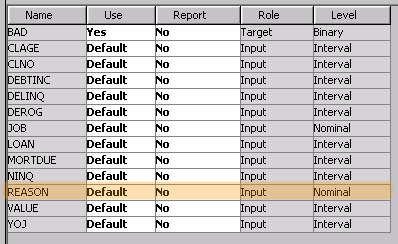
So we will actually be comparing our stratified model to a single model in which Reason is a nominal main effect.
Run the flow and examine the Model Comparison results.

Was it worth stratifying? Actually, we see much better lift for the simpler, unstratified Regression model.
Finding Best Modeling Algorithm for Each Stratum
Let’s not give up just yet.
One of the really neat features of the group processing nodes is that if you build a stratified model using multiple modeling algorithms (Regression, Decision Trees, Neural Networks, etc.) Enterprise Miner will automatically select the best algorithm for each strata.
I’ve extended our flow, adding Decision Tree nodes within and outside of the group processing portion of the flow. I’ve also added a Model Comparison node within the group processing portion to allow us to compare models within strata.
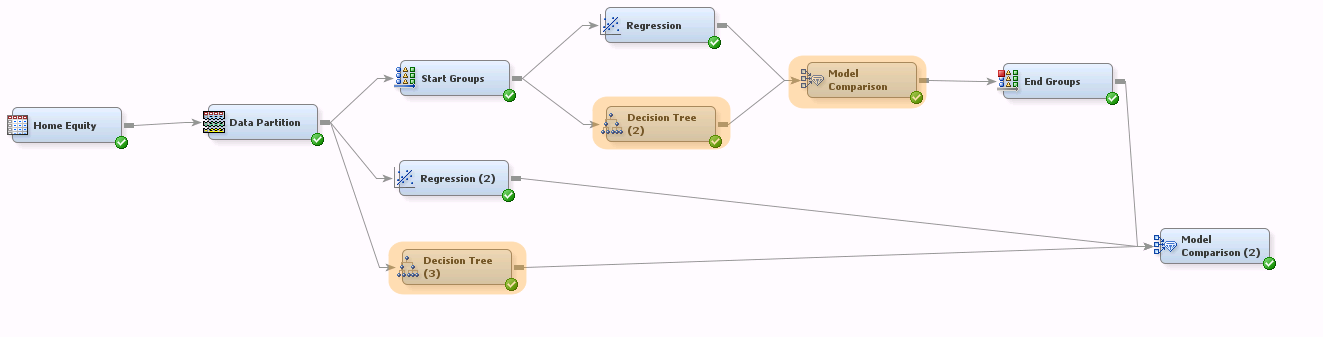
This flow will generate a stratified model that uses the best algorithm (Regression or Decision Tree, whichever happens to be the champion) for each stratum. It also compares this stratified model to two simpler unstratified models built using regression and decision trees.
Run the flow and examine Model Comparison results for the stratified model:
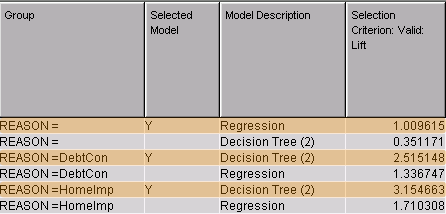
The Model Comparison node choose the best model (Selected Model = Y) for each stratum based on their lift in validation. For two of the Reason strata, Decision Tree worked best; for the other, Regression was best.
Now examine the Model Comparison results for the overall comparison between the stratified multi-algorithm model vs. the two unstratified models:
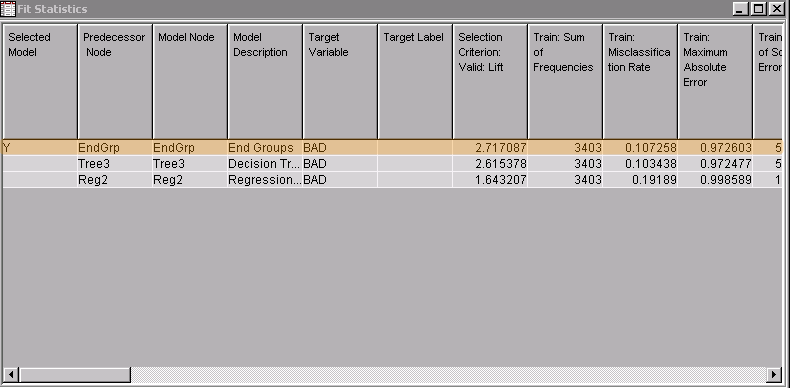
This time the stratified model is the champion. It has the highest overall lift in validation, outperforming both the simple Decision Trees and Regression models (although the Decision Tree model is not far behind).
Summary
We’ve seen how to use the group processing nodes to build models tuned to the characteristics of individual strata. When we allowed the modeling algorithm to vary by strata, saw an improvement in lift compared to simpler challengers.
Stratified models generally perform best when the strata are unique and homogeneous. If you suspect that you have fairly homogeneous groups in your training sample, it may be worth giving stratification a try. If stratification fails to deliver a better model, you will have more confidence in the other more parsimonious alternatives. The strata do not need to be fixed categories like reason for loan, education level, or sales territory--they could be segments derived from the input data via a clustering technique.
The group processing nodes are very flexible and capable. In addition to stratification, you can also use them to:
- Analyze multiple target variables in the same process flow
- Loop repeatedly through subflows
- Resample the data set to perform boosting and bagging
Here are some useful reading materials to help you learn more about the powerful group processing nodes:

