- Home
- /
- SAS Communities Library
- /
- Tip: Guidelines for Choosing a Clustering Method in the Cluster Node
- RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Tip: Guidelines for Choosing a Clustering Method in the Cluster Node
- Article History
- RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
The Cluster Node in SAS® Enterprise Miner™ gives you two options for specifying the number of clusters. You can specify a fixed number of clusters or let Enterprise Miner find the number of clusters for you by selecting the “Automatic” option.
If you use the "Automatic" option, the options under “Selection Criterion” allow you to set different parameters and methods used in the automatic selection process.
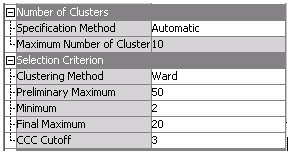
Figure 1: Screenshot of the options
In this tip I will explain the available clustering methods used in the automatic selection process. But before we begin, let me summarize how the automatic selection process works in the Cluster Node:
- A large number of preliminary cluster seeds are selected and observations in the training data are assigned to the closest cluster seed. Means of the input variables in each of these preliminary clusters are computed. Note that you can specify the initial number of seeds using the “Preliminary Maximum” option.
- An agglomerative hierarchical algorithm is used to consolidate the preliminary clusters. The Cubic Clustering Criterion (CCC) is calculated at each step of the consolidation and the number of clusters is estimated using these CCC values.
- The smallest number of clusters is chosen that meets all four of the following criteria:
- The number of clusters is greater than or equal to the Minimum specified in Selection Criterion properties.
- The number of clusters has CCC values that are greater than the CCC Cutoff specified in the Selection Criterion properties.
- The number of clusters is less than or equal to the Final Maximum value.
- A peak in the number of clusters exists.
If none of these criteria are met, then the number of clusters is set to the first local peak.
Agglomerative hierarchical clustering starts with each observation in preliminary clusters and combines the clusters that are most similar in terms of distance between the clusters at each stage. The inter-cluster distance measure can be calculated in many ways. In the Cluster Node, three methods are available:
- Average linkage method: The distance between two clusters is the average pairwise distance between each cluster. This method:
- Tends to join clusters with small variances.
- Is slightly biased to finding clusters with the equal variance.
- Avoids the extremes of either large clusters or tight compact clusters.
- Centroid method: The distance between two clusters is the squared Euclidean distance between their means. This method is more robust to outliers than most of the other hierarchical methods, but does not generally perform as well as Ward`s method or the Average method.
- Ward`s method. This method does not use cluster distances to combine clusters. Instead, it joins the clusters such that the variation inside each cluster will not increase drastically. This method:
- Tends to join clusters with few observations
- Minimizes the variance within each cluster. Therefore, it tends to produce homogeneous clusters and a symmetric hierarchy.
- Is biased toward finding clusters of equal size (similar to k-means) and approximately spherical shape. It can be considered as the hierarchical analogue of k-means.
- Is poor at recovering elongated clusters.
The graphs below show how these methods perform for some simulated data sets having different characteristics. Each dataset has 100 points and I used 50 (the default) as the initial number of cluster seeds in the first step. The other half of the points were used for estimating the number of clusters.
- Well separated data: In this example, there are three well separated and compact clusters. For such data sets, any of the methods will perform very well. All three methods selected 3 as the number of clusters.
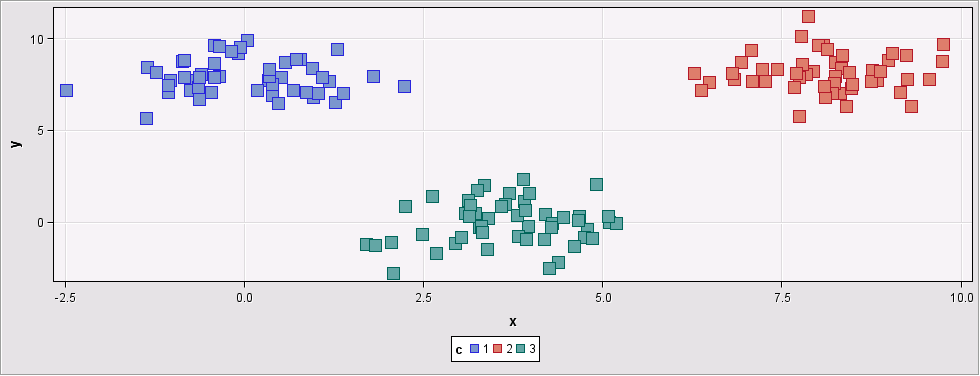
Figure 2: Input data set with 3 clusters
- Poorly separated data: In this example, there are three poorly separated and compact clusters.
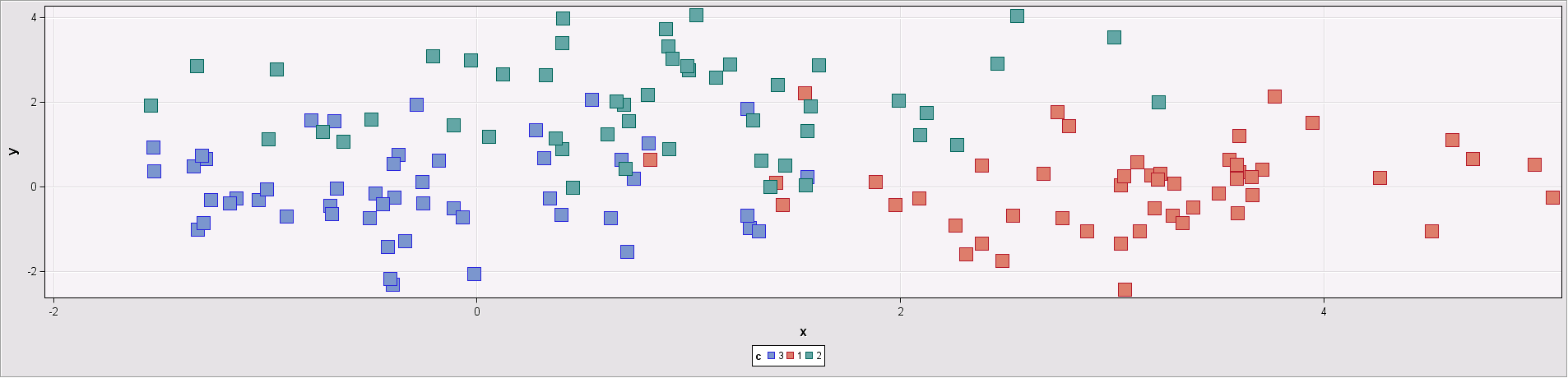
Figure 2: Input data set with 3 poorly separated clusters
For data sets containing clusters with these characteristics, different methods with different parameters need to be investigated. In this case, Ward’s method found 7 clusters:
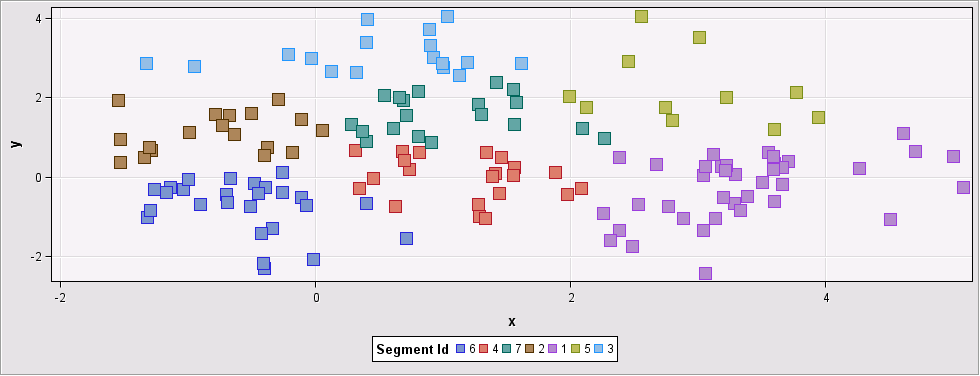
Figure 3: Input data set grouped into 7 clusters using Ward`s method
By comparison, the Average method found 6 clusters, while the Centroid method found 9 clusters.
When we increase the “Preliminary Maximum” to 100 (basically using all points to estimate the number of clusters), the Ward and Average methods both found 3 as the number of clusters, while the Centroid method found 5.
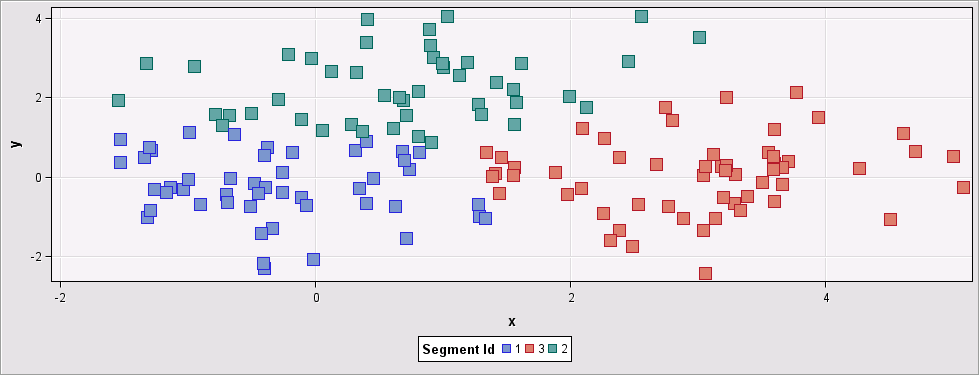
Figure 4: Input data set grouped into 3 clusters using Ward`s method
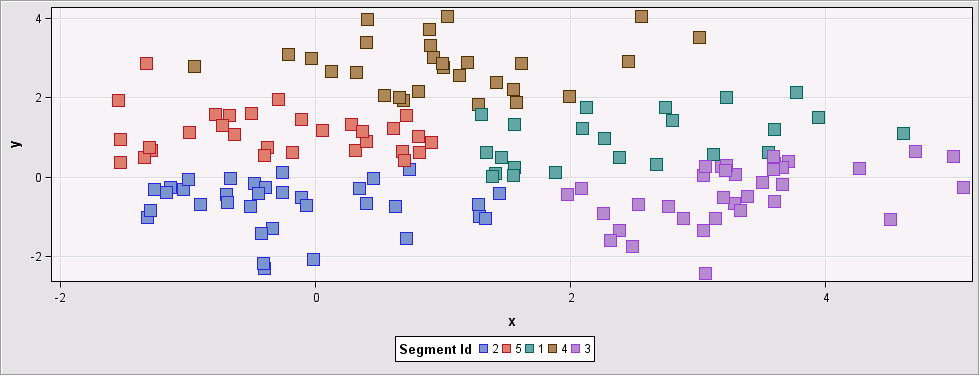
Figure 5: Input data set grouped into 5 clusters using Centroid method
- Multinormal clusters of unequal size and dispersion:
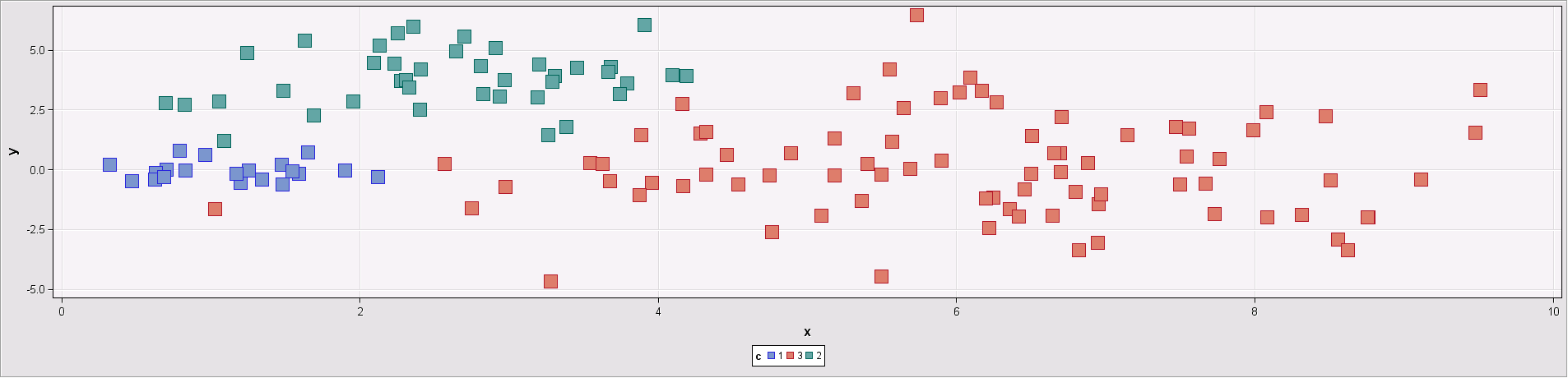
Figure 6: Input data set with three multinormal clusters that differ in size and dispersion.
For this data set, the Ward and Average methods both found 5 clusters, while the Centroid method found 4 clusters.
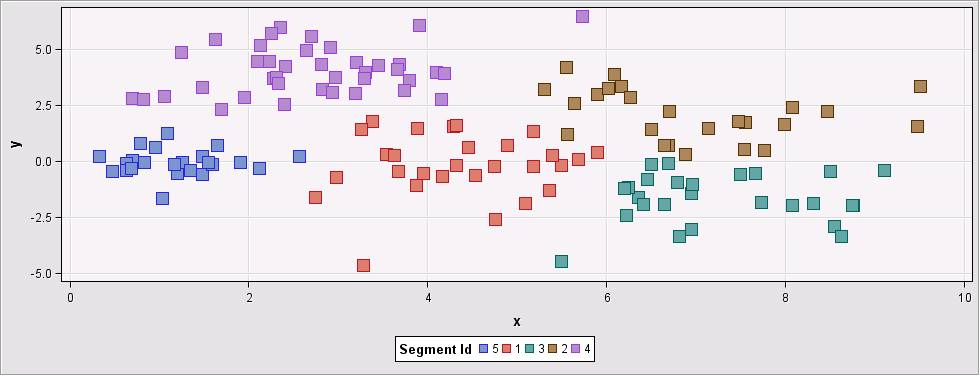
Figure 7: Input data set grouped into 5 clusters using Ward`s method
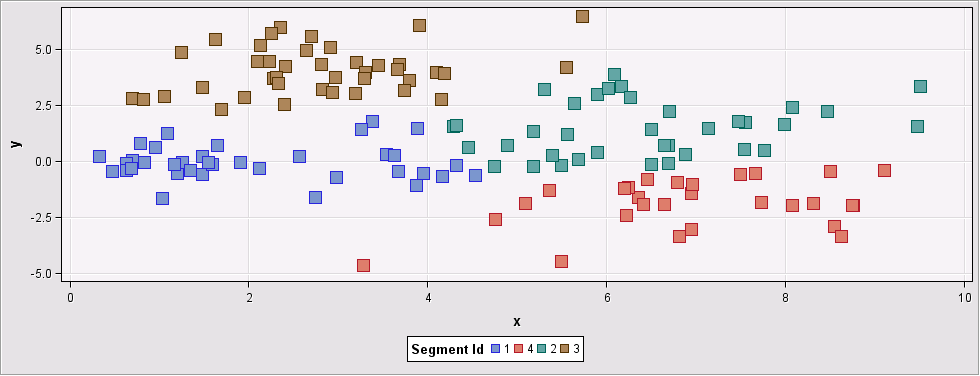
Figure 8: Input data set grouped into 5 clusters using Centroid method
When we increase the “Preliminary Maximum” to 100, all methods find 5 as number of clusters.
Conclusions
We`ve seen how to use the Automatic selection method in Cluster Node. Each of the methods discussed here has its own advantages. Here are some rules of thumb that can help you choose the right method for your data:
- The Cluster Node uses the Ward, Average and Centroid methods for finding the number of clusters. After the number of clusters is determined, the clusters are obtained using a k-means algorithm.
- If the natural clusters are well separated from each other, any of the above algorithms will perform very well.
- If the clusters overlap, the methods will find different numbers of clusters. To choose the best number of clusters, you can view the CCC plot from the results section and check how the values change depending on the number of clusters. (For details on the CCC method, see the SAS Technical Report.) You may also want to check the Cluster node log to see whether there are any warnings regarding the number of clusters.
When the clusters have elongated or irregular shapes, consider transforming the input variables before clustering. Some transformations on variables can generate more spherical clusters, which can be more easily detected by the Cluster Node.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
IT is a great guide, thanks
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Glad you found this useful. Finding the number of clusters in a data set is a very challenging problem. I think understanding these options is really important to figure out how you should set them. I highly encourage you to check the CCC plot from the results section after you run the node. As a side information, you can also look at the tip: This tip explains another way (briefly) to find the number of clusters using the NOC=ABC option in proc HPCLUS.
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
Question: how did you create the scatter plots (variables used)?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
I used %em_report to create the scattered plots. I used _SEGMENT_ for the GROUP option. Below is an example. Please let me know if you have any questions.
%em_register(type=Data,key=MyKey2);
data &em_user_MyKey2;
set &em_import_Data;
run;
%em_report(KEY=MyKey2,VIEWTYPE=scatter,X=x,Y=y,GROUP=_SEGMENT_, DESCRIPTION=AutoAverage , AUTODISPLAY=y);
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
hello,
You said: "After the number of clusters is determined, the clusters are obtained using a k-means algorithm."
i want to know : which clustering Method is really performs in Cluster Node ? hierarchical cluster algorithm or non hierarchical ?
because your colleague tell me that cluster node performs a hierarchical cluster algorithm
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
how to create a scatter plot for data with five variable in Sas EMINER?
we don 't have a canonical node
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
How to create the dendogram from the clusters output of SAS EM? I checked the tree but I want to look at dendogram tree diagram or line printer of clusters to variables ? would you please provide info on which cluster export datasets to utilize to produce the tree diagrams?
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Report Inappropriate Content
@ilknurkabul Hey, thanks for sharing the code. I'm currently trying to implement this in a project, however would like some clarity on the code. Could you explain the data you have passed as MyKey2 in the first line of your snippet?

Ready to see what SAS Viya Copilot can do?
Visit the Tips & Tricks page for setup guidance, demos, and practical examples that show how Copilot supports your workflows.
SAS AI and Machine Learning Courses
The rapid growth of AI technologies is driving an AI skills gap and demand for AI talent. Ready to grow your AI literacy? SAS offers free ways to get started for beginners, business leaders, and analytics professionals of all skill levels. Your future self will thank you.
- Find more articles tagged with:
- machine_learning
