One of the core features of any master data management solution is the ability to identify matching data in disparate data systems and resolve slight variations into a “best record” that is suitable for use by other users or applications. This best record is a business rule-derived combination of all the data elements from the different source systems rolled into a single authoritative representation.
Matching Data to Master It
A key concept in SAS Master Data Management (MDM) is the match cluster. A match cluster is made up of one or more records from contributing source systems and the derived best record. In other words, all records that match each other based on the conditions defined by the data steward end up in a cluster together. So if SAS MDM can find similar data across different systems and combine it into a consistent single view, what’s the problem?
While the goal is to be able to automatically and fully resolve all matching data into completely reliable match clusters, in practice this can be difficult to do. There will always be cases where one or more records grouped together look very similar to each other but are in fact unique. This is called over-matching and ideally it should be addressed by data stewards through a defined process that identifies and then corrects the specious matches.
The key to finding issues like these in SAS MDM is to create an over-match report that scans all clusters individually for data values that appear to be exceptions. For example, consider the following:
- The name and address for individuals match but the birth date is different. This could represent different family members with the same name.
Robert Smith – June 3, 1965
Robert Smith – Oct 10, 1989
- The name and phone number for individuals approximately match but the gender code is different. These could represent family members with similar names but who are not the same individual.
Sal Jacobsen – 740-264-0979 – M
Sally Jacobsen – 740-264-0979 – F
To look for and correct these kinds of over-matched records in the SAS MDM system data stewards can create an MDM Tool that identifies the problem match clusters. They can then use standard Recluster functionality to fix them. MDM Tools can expose any data flow or job logic through SAS MDM web application components that can be authored in batch jobs or real-time services in Data Management Studio. To design and use an MDM Tool for over-match correction, a data steward would do the following:
- Create a real-time data service that finds incorrectly matched data in the SAS MDM database.
- Upload the real-time data service to Data Management Server.
- Create a new MDM Tool in the Data Model component of SAS MDM.
- Invoke the new tool from the Master Data Management component of SAS MDM and view the report.
- From the report, drill through to the potentially erroneous cluster and use standard Recluster functionality to move one or more records out of the original match cluster.
Finding Over-matches
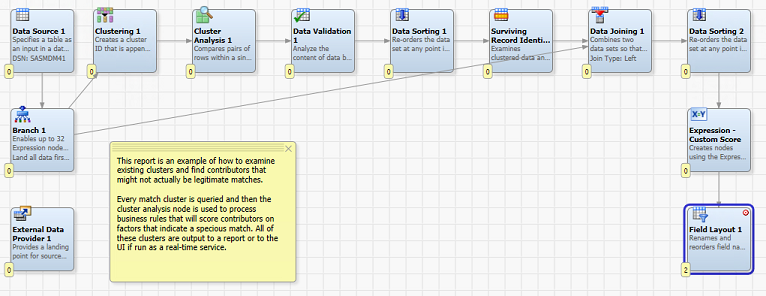
To begin, the data steward will design a real-time service in Data Management Studio that will perform the over-match processing. In this example, the data steward will build the tool for use with the standard sample INDIVIDUAL entity type. The new real-time service for an over-match report for an INDIVIDUAL entity type might implement this kind of data flow logic:
- Create a query for all INDIVIDUAL master data or for larger MDM hubs, select a subset of INDIVIDUAL master data for evaluation. Exclude best records. The MDM_INDIVIDUAL_MA view will provide data in this desired format.
- Create a branch of the data at this point. The data flow will later join original source system records back to records identified in the job logic as being potentially over-matched records.
- Use a Clustering node to limit the results of the initial query to just clusters that have more than one contributing record in each cluster under evaluation.
- Use a Cluster Analysis node to define business rules to be used for finding anomalies in clusters. For example: BIRTH_DATE [does not equal] BIRTH_DATE. Provide a score in a SCORE field for each rule.
- Use a Data Validation node to filter the results on only rows that have a score greater than 0, which means a business rule was triggered and a potential over-match condition was found.
- Sort the data by MDM_ENTITY_CLUSTER_ID in preparation of the next step.
- Use a Surviving Record Identification node with MDM_ENTITY_CLUSTER_ID as the cluster ID field to isolate potentially anomalous records.
- Again, using the MDM_ENTITY_CLUSTER_ID field, use a Data Joining node to join possibly questionable records from the match logic branch back to the entire match cluster branch coming from the Branch node.
- Sort again on MDM_ENTITY_CLUSTER_ID.
- Use an Expression node step to create a user-friendly score value. Something like this might be appropriate: SCORE = 100-(SCORE*15).
- Arrange the output fields using a Field Layout node. Mark this node as the default target node.
- Add an External Data Provide node so that the process can be invoked as a real-time data service. Do not connect this node to other parts of the data flow. Be sure to pass the MDM_ENTITY_TYPE_ID field and the MDM_ENTITY_CLUSTER_ID field out of the real-time data service you create so that the “Open Entity” functionality described below is enabled.
- Save this real-time service as tool_individual_over-match.ddf. (This name is not required but is used in the rest of this example.)
When complete, the real-time service will look something like this:
Defining the MDM Tool
Now that the real-time data service is ready, use Data Management Studio to upload the service into the Real-Time Data Services/sasmdm directory on Data Management Server. Once the service is available on the server, the next step is to define the tool in your SAS MDM web application environment.
- Login to SAS MDM through the Data Management Console and select the Data Model component.
- Open the INDIVIDUAL entity type and click on the Tools tab.
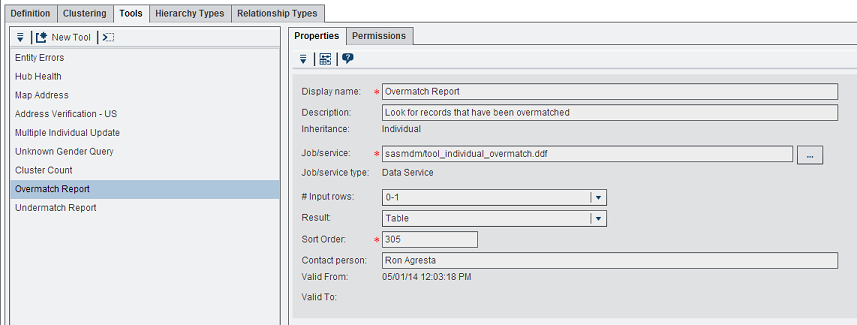
- Using the Action menu, select New Tool and enter the following information:
- Display Name: Over-match Report
- Description: Look for records that have been over-matched
- Job/service: sasmdm/tool_individual_overmatch.ddf
- # Input rows: 0-1
- Result: Table
- Sort Order: 305 (or any available sort order number)
- Contact person: (your name)
- Save the tool.
For the tool to be accessible in other parts of SAS MDM, either log out of the system and log back in or use the refresh action in your browser. This will refresh MDM metadata in all SAS MDM web application components.
Now that the new tool is in place, it can be invoked in the Master Data Management component of SAS MDM.
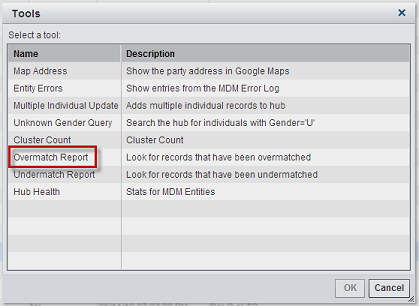
- Navigate to the Master Data Management component from Data Management Console.
- From the Search screen on the right side of the menu bar, change the entity type to Individual.
- From the Action menu, select Tools.
- From the Tools dialog window, select Over-match Report.
Evaluating Match Issues
After the tool has been run successfully, a new tab with a table full of possible over-matched clusters appears in the Data Management Console.
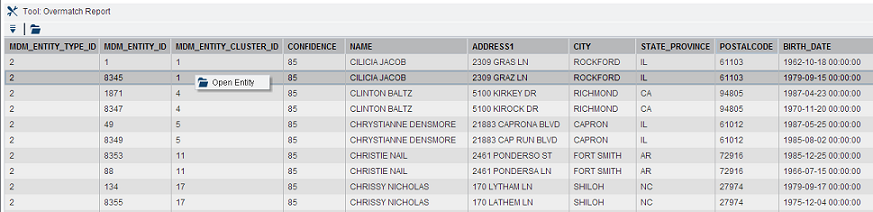
The interesting columns in this table are the MDM_ENTITY_CLUSTER_ID column and the CONFIDENCE column. Records with the same MDM_ENTITY_CLUSTER_ID are in the same match cluster. The CONFIDENCE column has a value between 0 and 100. The closer it is to 100, the closer the match among the records in the match cluster. SAS MDM’s real-time service job logic dictates that any cluster with a potential bad match will appear in the report and the lower the CONFIDENCE value, the more likely it is that invalid matches have appeared in the given cluster.
In the screenshot provided, all of the clusters in this portion of the results have been flagged because the BIRTH_DATE information indicates that the individuals thought to be the same are actually different people living at the same location. It’s also possible that there is intentional fraudulent activity going on or that incorrect information is coming from one or more of the source system. In any of these cases, a data steward has been alerted to a suspicious issue that needs to be addressed.
Correcting Over-matches
Now that possible mismatches have been found, the next step is to correct the problem. Assuming we are really dealing with legitimate data and not invalid or intentionally incorrect data (circumstances that would involve further investigation), using standard SAS MDM functionality, data stewards can pull apart mismatched data and move it to other more appropriate clusters or to new unique clusters depending on the data.
By right-clicking on the report results and selecting Open Entity, data stewards can access the entire match cluster for further review.

Once in this view, data stewards can explore the record and determine if this match cluster really represents two unique individuals instead of one. If the data steward deems this to be the case, she can access the Recluster feature from the Action menu item. This brings the data steward to a screen where the original cluster is on the top and a new or target cluster is on the bottom.
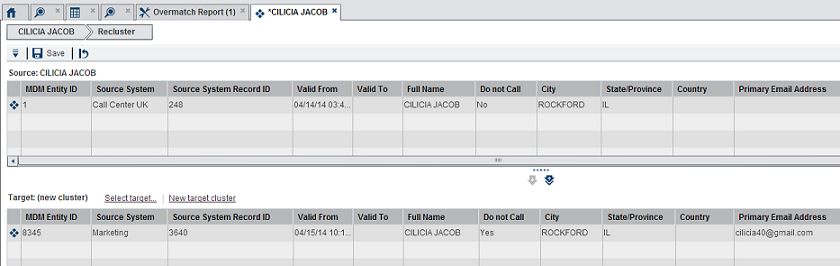
In this example, the data steward has decided that the cluster really represents two distinct individual so she has chosen to move one of the contributing records to a brand new cluster. In doing so, a new best record is created and there are now two individuals recognized as master data in our system. In this way, a data steward can review and revise incorrectly matched records in an ongoing fashion as new data enters the SAS MDM system.
We have explored just one example of how MDM Tools can be used. Many data-centric MDM business requirements can be met by encapsulating data workflows as MDM Tools built in SAS Data Management Platform. Data Stewards may choose to build an entire set of MDM Tools to help find and correct issues in their master data repository.
What other tools would be useful additions to a data steward’s MDM toolbox?

