In an earlier tip, my colleague Jagruti showed how to use SAS® Enterprise Miner™ to derive variables for better predictive models. In particular, she extracted passenger titles like “Mr.”, “Mrs.”, “Lady”, from Titanic name records and used them to achieve higher classification accuracy in a decision tree model.
Things can get trickier when work with free-text responses. For one thing, you cannot rely on a fixed structure (e.g., title followed by firstname then lastname) when manually parsing the text. In addition, there is often considerable linguistic variation to account for.
I was recently working with a dataset that consisted of physical activity records from a recreational facility. During each visit, patrons filled out a form that included both fixed-choice options like “Weight Lifting” and “Basketball” as well as a free-text field for recording another activity.
Here are a few rows of the unstructured responses, which I have simplified for purpose of this tip:

My goal was to transform these free-text responses into binary inputs for predictive modeling. In particular, I wanted to create a new variable, “Run_walk” that indicates whether each person performed some form of running or walking activity. And when categorizing each response, I wanted to differentiate terrestrial running and walking activities from aquatic variants like water walking, as well as unrelated activities like cycling.
Using SAS Data Step Code
To create the run_walk variable, I tried several approaches in a SAS Data step.
1. I tried using the IN operator, which checks whether a variable’s value is among a list of values:
run_walk_IN = upcase(other_act) in('RUN', 'RUNNING', 'WALK', 'WALKING', 'TREADMILL', 'JOG', 'JOGGING');
2. I also used the Index function, which checks for occurrences of a string within a variable:
run_walk_INDEX = (
(index(upcase(other_act),"RUN")) or
(index(upcase(other_act),"WALK")) or
(index(upcase(other_act),"JOG")) or
(index(upcase(other_act),"TREADMILL")))
and
not ((index(upcase(other_act),"WATER")) or (index(upcase(other_act),"POOL"))
);
This statement sets run_walk_INDEX to 1 if the variable other_act contains a value of “run”, “walk”, “jog”, or “treadmill”, and does not contain “water” or “pool”. Otherwise, run_walk_index is set to 0. Note the use of the UPCASE function to ignore upper- and lower-case variation in the responses.
3. Finally, after hunting around a bit, I found that SAS supports Perl Regular Expression matching. That seemed like a nice way to simplify my code, so I also tried the PRXMATCH function:
run_walk_PRX= prxmatch("/run|walk|treadmill|jog/i",other_act) and not(prxmatch("/water|pool/i",other_act));
The following table shows the output of each expression. For each new column, 1 represents a match and 0 represents a non-match.
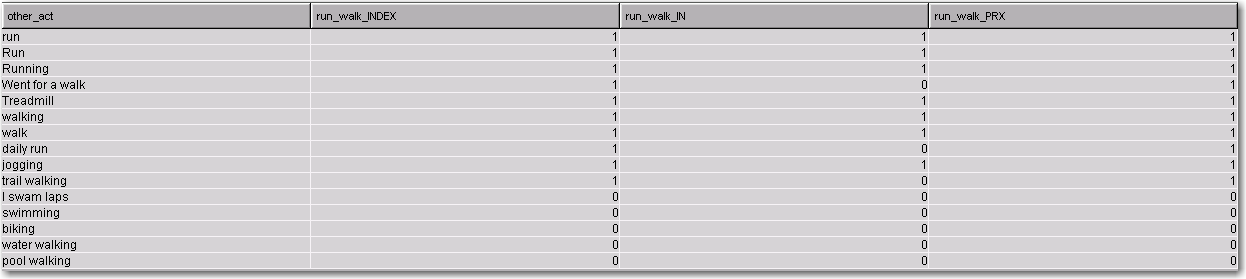
The results are similar for the three methods, but not identical:
- The IN form (run_walk_IN) while nice and compact, was too simplistic for my purposes. Because IN looks for matches between a particular string like ‘run’ and the full text of “other_act”, it misses matches like ‘daily run’. Of course, I could have included ‘daily run’ and other variants as matches, but with all of the possible variants that could occur with real data, this approach could quickly become unmanageable.
- The INDEX form (run_walk_INDEX) captured the various forms of terrestrial running and walking, and correctly handled the counterexamples.
- The Perl Regular Expression Form (run_walk_PRX) gave the same results as the Index form with a much more compact expression.
More on Perl Regular Expressions
Accuracy and compactness are a good combination. So let’s take a closer look at the PRX form.
Here’s the first part of the expression:
run_walk_PRX= prxmatch("/run|walk|treadmill|jog/i",other_act) …
The basic form of the PRXMATCH function is PRXMATCH(perl-regular-expression, source).
Here the Perl regular expression, specified within forward slashes is: “/run|walk|treatmill|jog/i” and the source is the text variable Other_act. This expression declares a match if “Other_Act” includes “run”, “walk”, “treadmill” or “jog”. The “i” modifier tells the function to ignore case when checking for matches.
The second part of the expression tells SAS to ignore responses that include “water” or “pool” when looking for matches:
… and not(prxmatch("/water|pool/i",other_act));
PRXMATCH is just one function in a family of PRX functions that you can use to validate data, replace text, and extract a substring from a string. You can write SAS programs that do not use regular expressions but Perl regular expressions often result in code that is less prone to error, easier to maintain, and clearer to read.
Using SAS® Text Miner™
One issue with the above approaches is that I needed to manually account for the relevant linguistic variations of “running” and “walking” as well the many possible counterexamples. That can be both tedious and error prone. Suppose one of the responses were “doing crunches” (also known as “sit ups” or “abdominals”), where "crunches" includes the substring "run". Without further modifications, the INDEX and PRX statements above would have incorrectly treated it as an instance of “run_walk”.
SAS Text Miner easily handles linguistic variations and, as a bonus, does not require coding. Here I created a simple flow that uses three SAS text mining nodes:

Text Mining Flow
- Other Activities. A SAS Code node that defines my input datasource with the Other_Act column.
- Metadata. Assigns a role of “Text” to the Other_Act column.
- Text Parsing. Parses the responses. In node properties, I specified that parts-of-speech variations should be ignored (i.e., treated as the same term).
- Text Filter. While the Text Filter node is normally used to filter infrequent terms, for this small dataset I set the Minimum Number Of Documents property to 1 so infrequent terms would not be excluded.
- Text Topic. The Text Topic node can be used to derive new topics from the data and define user (a priori) topics. In this case, I used it for the latter purpose. Here are my user topic specifications:
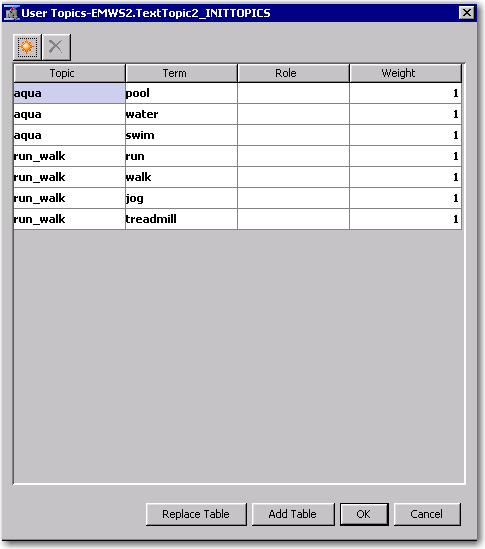
This specifies that “pool”, “water”, and “swim” are examples of the “Aqua” topic and the other terms listed below belong under the “Run_walk” topic. Note that there is no need to manually handle variations like “run” and “running”, or "swimming" and “swam”. That is taken care of by the text mining components.
The result? Let’s look at the data exported from the Text Topic node:
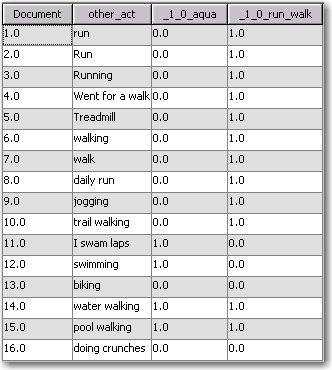
We’ve actually gone one step beyond the Data step approaches described above and created two columns. The first, _1_0_aqua, represents aquatic activities. The other, _1_0_run_walk, represents terrestrial running and walking activities. Both are binary (0,1) variables ready to use in a predictive model. And note the final row, document (response) #16, which I added to the input dataset before running the flow. Text Miner correctly classified “doing crunches” as being an instance of neither “run_walk” nor “aqua”.
In summary, Text Miner saved me from having to manually deal with linguistic variations in the responses, or even write code, for that matter. Some final cleanup is still needed here, because if both _1_0_aqua and _1_0_run_walk are positive, as in the last two observations, I would want to consider the response an instance of aquatic activities. But that can be done easily using Enterprise Miner nodes.
Conclusions
We’ve seen how to use SAS Data step code and text mining capabilities to categorize free text responses. Each of the approaches discussed here has its place depending on your goals and the complexity of your free text responses. But note that linguistic variations can be a real issue any approach that is not language aware.
Also keep in mind that I had an a priori category structure in mind when working with the physical activity data: I knew the topics in advance, and just wanted to “score” the responses accordingly. The Text Topic node can also be used to discover new topics from unstructured text data, but that’s the subject for another tip.
Caveat for Enterprise Miner Users
PRXMATCH transformations are included in optimized score code if you use the Transform Variable Node or put them in the Score tab of a SAS Code node; However, PRXMATCH is notused in exported C or JAVA code.
References
SAS PRXMATCH Function
Perl Regular Expression Reference
SAS Text Miner

