A successful direct marketing campaign can maximize the return on investment by motivating more customers to respond to a certain marketing action. To achieve the goal, it is necessary to analyze the marketing database carefully at the preparatory stage and select the optimal targets that are expected to generate incremental revenue.
The Incremental Response (IR) node in SAS® Enterprise Miner™ models the incremental impact of a campaign in order to optimize customer targeting for maximum return on investment. One response variable is required as the binary target variable for determining the likelihood that a customer responds to the campaign; the node also accepts one optional interval target which indicates the sales amount if the customer does respond. The node runs the incremental response model and subsequently the incremental outcome model when a secondary interval target is specified. In this tip, you will see one feature of the IR node which helps you select the optimal business targets based on the incremental revenue.
In the Results window of the IR node, there is a bar plot named as Average Incremental Revenue which is displayed along with more model diagnostics plots. The Average Incremental Revenue shows the expected incremental revenue averaged by decile. The expected revenue for each customer is calculated as
Expected Revenue (per response) = Expected Response Probability × Expected Sales – Cost.
Then for a given customer, the expected incremental revenue can be formulated as
Expected Incremental Revenue = Expected Revenue in Treatment - Expected Revenue in Control.
The Average Incremental Revenue plot provides important guidelines about which customers are considered as the optimal targets in terms of generating more incremental revenue that exceeds, or at least covers, the cost of campaign.
Let’s use the data set sampsio.dmretail and the flow as shown in Figure 1 to illustrate how to utilize the Average Incremental Revenue plot to select the optimal target.

Figure 1: EM flow running Incremental Response Node on DMRETAIL data set
Variable SALES which indicates the sales amount of a customer if the customer respond to the marketing action is set as the secondary target variable as shown in Figure 2. When a secondary interval target variable is specified, it will then be used to calculate the expected sales per response in the previous formula of expected revenue. Otherwise, you can also specify constant revenue for all the respondents through the node properties. In such case, the expected revenue for each customer is then calculated as
Expected Revenue (per response) = Expected Response Probability × Constant Revenue - Cost.

Figure 2: Variable list of DMRETAIL data set. Variable SALES is set as secondary interval target.
Figure 3 shows the key properties for the revenue calculation.
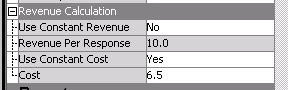
Figure 3: Properties for Revenue Calculation
The Average Incremental Revenue plot (Figure 4) clearly shows the cutoff between the 5th and 6th decile. The top bar plot is based on the analyses on Train data and the bottom one is from Validation data. To achieve the expected revenue higher or at least covering the campaign cost, only the customers in the top 5 decile should be targeted, and the results are consistent in this case for both Train and Validation data.
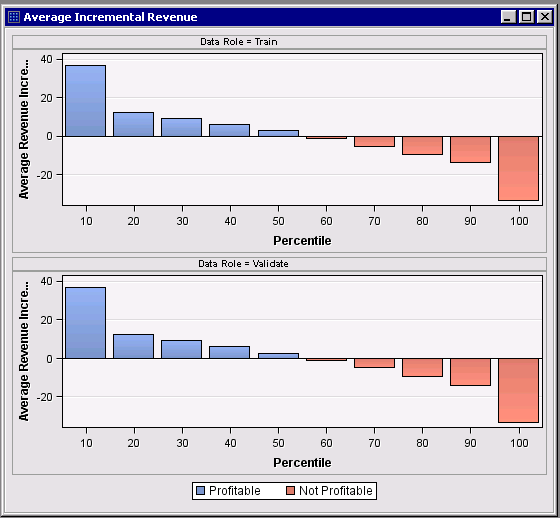
Figure 4: Average Incremental Revenue Plot of the Incremental Response Node
In summary, EM Incremental Response node offers various analyses besides the calculation of the average incremental revenue to identify the customers who generate incremental responses so as to maximize the net profit. For more details about the node, please refer to the paper “Incremental Response Modeling Using SAS® Enterprise Miner™”, SUGI proceedings, 2013.
.jpg")
