
Introduction
This is the second post in this series, a test to see how well Data Iintegration Studio handles different update scenarios. For an introduction to the different slowly changing dimension types, and the basis for these articles, see my previous article.
SAS DI Studio and Slowly Changing Dimension Types 2, 3 and 4
In this second part, we’ll discover how we handle the SCD types 2 through 4. Types 2 and 3 are conceptually well known, but no 4 is new to many of us, I believe.
SCD Type 2
Type 2 is quite common in data marts, but it’s in the detail layer of the data warehouse where this one is king. When a history of change is needed, and generation of surrogate keys are involved, this is the most common choice.
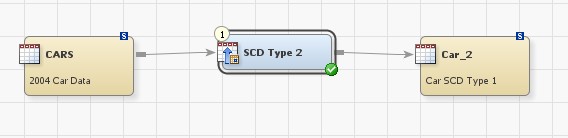
Like the Type 1 Loader, the SCD Type 2 Loader transformation is documented within the product. A few notes about the usage though.
On the Change Tracking tab, specify which columns in the target table handles the data versioning (change date history).
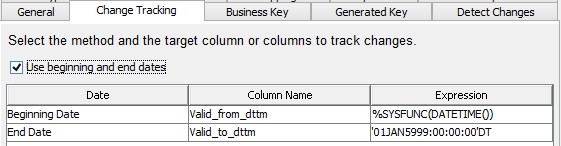
Date and Datetime columns are supported. For date columns, you need to change the expressions. If you map the Beginning Date column, and that contains values, existing values take precedence over the expression in this window.
In the Type 2 Loader you have a choice of creating retained surrogate keys (or not). Retained means that if a new record is being created for a business key, the new record will use the same surrogate key as the original record. This more common in detail data stores but could require additional filtering on change dates. Using a non-retained key (generating a new surrogate key value) makes it easier to join Type 2 dimensions with fact tables in star schemas.
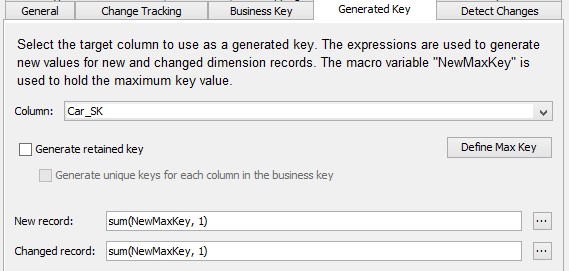
The Generated Key tab in the SCD Type 2 Loader.
SCD Type 3
As mentioned earlier, this is not a popular update type for a dimension, because of its static nature – you need to specify in the schema the number of generations you wish to store. Here is an example how it can be implemented:
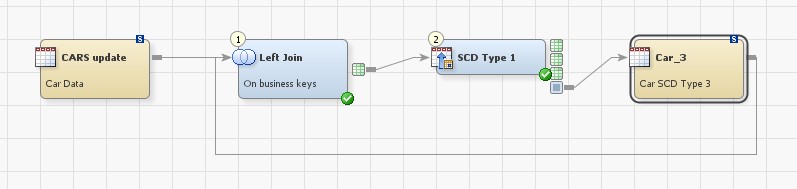
Since there is no ready-made transformation for this type, we have to do part of the logic ourselves. Before loading the source data into the dimension, we need to compare the current values with the transaction, which could be done in a join transformation.
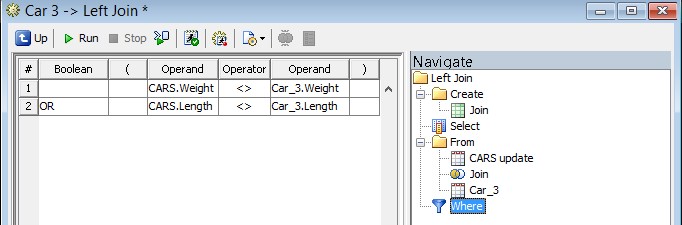
At the end, we use the SCD Type 1 Loader so a surrogate key is generated for us. In this example CARS is the transaction data, Car_3 is data from the dimension.
 .
.
In the join, we can filter out records that have not changed (in the where section), this to optimize the job for the SCD Type 1 Loader processing.
And here is the part of the select clause where we compare source and target data :
case
when CARS.Weight <> Car_3.Weight and Car_3.Weight <> .
then Car_3.Weight
else Car_3.Weight_prev
end as Weight_prev
case
when CARS.Length <> Car_3.Length and Car_3.Length <> .
then Car_3.Length
else Car_3.Length_prev
end as Length_prev
If there is a change, we move the current dimension value to the “prev” (or the type 3) column, and map the transaction value to the current column.

And the result from the join. The Audi A6 and the BMW have their weight changed, while the Audi TT have a length change.
In the final step SCD Type 1 Loader overwrites our dimensional records we have spotted changes in, and potentially inserts new records.
Just remember, with this type of job, you need to create the dimension physically in some way before you run the job the first time, since it’s needed in the initial join.
SCD Type 4
The different SCD Types so far have described in what manner values in the dimension will be updated. This is not really the case for type 4, it’s more of different style of dimension. A mini dimension could in practice be updated using any of the other SCD Types. Bet let’s assume it will use the simple SCD Type 1.

It is challenging to show an example of a mini-dimension update, since it can be created in un-countable ways: grouping, intervals, scoring etc. In my example, I grouped by cars using percentiles, on three different continuous attributes.
I keep my code hidden in the User Written transformation since this is not what this article will focus on, just see it as a place holder for your own logic.
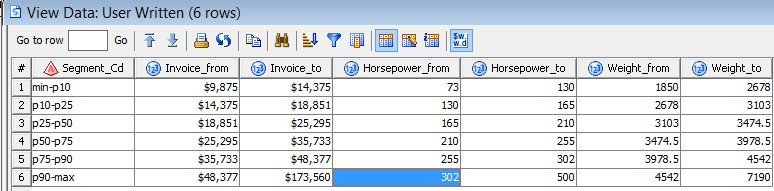
But for you to follow, here how the data looks like. My little program created six groups for P10, P25, P50 P75 and P90. I store the intervals in the result so that I easily can do a lookup from the source data during fact table load.
A Cartesian join is used to combine all possible combinations between those groups. This means that we join the same table with itself - one alias table per group column.

This join will result in table which probably will include combinations that will never have a corresponding row in the fact table: long cars tend have a higher weight than short cars. If you have more grouping columns than in my example, with more values, you may
wish to find ways just to store the combinations that exists in the fact– otherwise the dimension may grow unnecessary large.
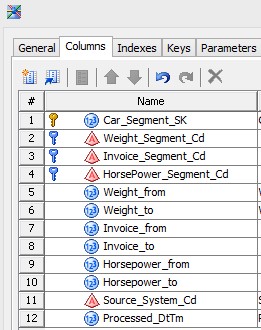
The dimension will have each percentile group as part of the business key (right):
So this was the end of part 2. Please return for the final SCD types 5-7. Until then, please leave any comments regarding this post.

