- Home
- /
- Programming
- /
- Programming
- /
- Find circular routes using Hash Objects
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sure, once you get table WANT , you can code something like :
proc sql noprint;
select max(countw(loop)) into : n separated by ' ' from want;
quit;
data final_want;
id+1;
set want;
array x{*} $ 40 c1-c&n ;
do i=1 to dim(x);
x{i}=scan(loop,i);
end;
drop i loop;
run;
Xia Keshan

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Once I have my output as:
ID C1 C2 C3 C4 C5 C5 C7
--------------------------------------
1 A B C D E F A
Can I again save that in the format as:
ID F T
---------
1 A B
1 B C
1 C D
1 D E
1 E F
1 F A
Thanks,
Deep
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sure. You own me some money . ![]()
data have;
input (ID C1 C2 C3 C4 C5 C6 C7 ) ($);
cards;
1 A B C D E F A
;
run;
data x;
set have;
array x{*} c:;
do i=1 to dim(x)-1;
F=x{i};T=x{i+1};output;
end;
drop i c: ;
run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Xia,
I ran the above code using:
data have;
INFILE CARDS MISSOVER;
input (ID C1 C2 C3 C4 C5 C6 C7 ) ($);
cards;
1 A B C D E F A
2 G H I G
;
run;
But it's not giving me proper output!
Deep
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Sure . You need consider the missing value.
data have;
infile cards truncover;
input (ID C1 C2 C3 C4 C5 C6 C7 ) ($);
cards;
1 A B C D E F A
2 G H I G
;
run;
data x;
set have;
array x{*} c:;
do i=1 to dim(x)-1;
if missing(x{i+1}) then leave;
F=x{i};T=x{i+1};output;
end;
drop i c: ;
run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Xia,
I made minor changes in the code, to show just the straight path traversed:
data have;
infile datalines;
length From To $11.;
input ID From $ To $;
datalines;
100 c1 c2
100 c2 c3
100 c3 c4
100 c4 c5
100 c5 c6
100 c6 c7
100 c3 c8
100 c9 c10
100 c4 c11
100 c5 c12
;
run;
data want (keep = ID path);
if _n_ eq 1 then do;
length path _path $ 32000 ;
if 0 then set have;
declare hash ha(hashexp:20,dataset:'have(where=(From is not missing and To is not missing))',multidata:'Y');
ha.definekey('ID','From');
ha.definedata('To');
ha.definedone();
declare hash pa(ordered:'Y');
declare hiter hi_path('pa');
pa.definekey('count');
pa.definedata('path');
pa.definedone();
end;
set have;
count=1;
path=catx(' ',From,To);
pa.add();
do while(hi_path.next()=0);
_path=path;
From=scan(path,-1,' ');
rc=ha.find();
do while(rc=0);
if not find(path,strip(To)) then do;
count+1;
path=catx(' ',path,To);
pa.add();
path=_path;
end;
/*else if scan(path,1,' ')=To then do;loop=catx(' ',path,To);output;end;*/
rc=ha.find_next();
end;
end;
pa.clear();
run;
proc sql noprint;
select max(countw(path)) into : n separated by ' ' from want;
quit;
data final_want;
id+1;
set want;
array x{*} $ 40 c1-c&n ;
do i=1 to dim(x);
x{i}=scan(path,i);
end;
drop i path id;
run;
The output I am getting is as below:
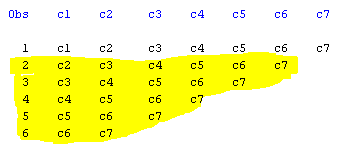
The obs from 2 to 6 are part of obs 1. How can I avoid them in the ouput dataset?
Deep
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
This is last time I answer your questions . If there were one more question, I will ask you to pay me some money .
data have;
infile datalines;
length From To $11.;
input ID From $ To $;
datalines;
100 c1 c2
100 c2 c3
100 c3 c4
100 c4 c5
100 c5 c6
100 c6 c7
100 c3 c8
100 c9 c10
100 c4 c11
100 c5 c12
200 c1 c2
200 c2 c3
200 c3 c4
;
run;
data ancestor;
if _n_ eq 1 then do;
if 0 then set have;
declare hash h(dataset:'have',hashexp:20);
h.definekey('id','to');
h.definedone();
end;
set have;
if h.check(key:id,key:from) ne 0;
run;
data want (keep = ID path);
if _n_ eq 1 then do;
length path _path $ 32000 ;
if 0 then set have;
declare hash ha(hashexp:20,dataset:'have(where=(From is not missing and To is not missing))',multidata:'Y');
ha.definekey('ID','From');
ha.definedata('To');
ha.definedone();
declare hash pa(ordered:'Y');
declare hiter hi_path('pa');
pa.definekey('count');
pa.definedata('path');
pa.definedone();
end;
set ancestor;
count=1;
path=catx(' ',From,To);
pa.add();
do while(hi_path.next()=0);
_path=path;
From=scan(path,-1,' ');
rc=ha.find();
do while(rc=0);
if not find(path,strip(To)) then do;
count+1;
path=catx(' ',path,To);
pa.add();
path=_path;
end;
/*else if scan(path,1,' ')=To then do;loop=catx(' ',path,To);output;end;*/
rc=ha.find_next();
end;
end;
pa.clear();
run;
proc sql noprint;
select max(countw(path)) into : n separated by ' ' from want;
quit;
data final_want;
set want;
array x{*} $ 40 c1-c&n ;
do i=1 to dim(x);
x{i}=scan(path,i);
end;
drop i path ;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Seems I got solution to it. Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
"But I want to restrict that, if there is no circular route found till 8 nodes i.e. A->B->C->D->E->F->G->H, then it should move to next observation and check for the circular route."
No, You can't. how you make sure there is no circular , if only searching the first 8 nodes .
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Yes, agree that there is no surity regarding circular route, by only searching first 8 nodes.
But I have to have some control on the output.
Just to give you an example is said 8, else one should be able to define upto how many nodes he want to check for the circular route.
If one defines it 20, the code should be able to check it for 20 nodes.
Deep
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If your table was huge, I really suggest you to split them into lots of small tables according to ID , That would be a better choice .

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
DeepH,
I have heard about recursive lookups (chained relationship) but not circular routes.
For id = 2, can you explain how you get i->j->i.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi datasp,
Actually I have made a minor change in my input data, which now looks as:
data have;
input (id From_City To_City) ($) @@;
cards;
1 a b
1 b c
1 c e
1 b a
1 e f
2 h i
2 i j
2 j i
;
So now for ID = 2 you can see i -> j -> i.
Circular route is what I want to accomplish, and recursive lookup might be a way to achieve it.
Can you pls share further details about it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi DeepH,
For ID = 2, the recursive lookup works the way you want but not for ID = 1.
In the former, you take From_City as KEY Part and get To_City as Data Part. Again take To_City(i) as KEY Part and get J as Data Part. And finally take J as Key Part and get I as the Data Part.
In the latter, you will get a->b->c->e->f
- « Previous
-
- 1
- 2
- Next »

Available on demand!
Missed SAS Innovate Las Vegas? Watch all the action for free! View the keynotes, general sessions and 22 breakouts on demand.
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
 Click image to register for webinar
Click image to register for webinar
Classroom Training Available!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
-
28 replies
-
01-19-2015 03:41 AM
-
1746 views
-
3 likes
-
3 in conversation
-
