- Home
- /
- Analytics
- /
- Stat Procs
- /
- Re: More than 2 Repeated variables in PROC MIXED
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm running a study in which I have 3 repeated measures (within subjects) variables and one independent groups (between subjects) variable. My outcome is a continuous one so I was hoping to use PROC MIXED. Here's my code:
PROC MIXED DATA = Data;
CLASS Group RM1 RM2 RM3 SubjectID;
MODEL Outcome = Group RM1 RM2 RM3;
REPEATED RM1 RM2 RM3 / TYPE = UN@UN SUBJECT = SubjectID;
RUN;
This analysis works just fine if I only have 2 repeated measures variables in it. However, with three (as in the above code), I get the following error message: "ERROR: Two REPEATED effects are required with this covariance structure."
I tried changing the "TYPE", but nothing I change it to will let me run the model. In my previous analyses with SPSS, there was never a problem with using 3 repeated measures variables, and so I'm wonder if there is a way to do this in SAS (it doesn't have to necessarily be with PROC MIXED).
Thanks,
Fearghal

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
There is no easy work around for this as described. Could you define RM1, RM2 and RM3 and how many levels you have for each of these three variables? Is there any possibility of nesting them within one another?
On the other hand, if RM1, RM2 and RM3 are simply three levels of a single variable, then it is just a matter of reshaping your data, and working a little bit on the code.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply Steve.
The variables are all separate ones with two levels. There's Time (time 1 vs. time 2), task (control vs. experimental) and speed (fast vs. slow). All participants have an outcome at each level of these variables (that's 8 outcomes in total). I'm not so sure the model would make theoretical sense if any were to be combined or nested. Perhaps I'm using the REPEATED statement incorrectly??
I basically want to replicate the kind of analyses that I've done in SPSS plenty of times (just through the General Linear Model>>Repeated Measures option). My experience so far with SAS is that it's way more versatile and powerful than SPSS, I can't believe there's something the latter can do that the former can't.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I should say that I'm interested in looking at interactions between the variables. If I combine them in any way, I'm not sure how I can do this.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Very interesting. I guess I would consider time and task to be the two repeated factors, and deal with speed as a continous covariate. Something like (assuming RM3 to be speed--WARNING: untested code, there may be some glitches to work through yet):
PROC MIXED DATA = Data;
CLASS Group RM1 RM2 RM3 SubjectID;
MODEL Outcome = Group|RM1|RM2|RM3; /*fits all possible interactions*/
REPEATED RM1 RM2 / TYPE = UN@UN SUBJECT = SubjectID;
RUN;
Then, I would address differences in speed through interactions and the use of the AT= option in the LSMEANS statement later on.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That's an interesting idea. I'm going to expose my ignorance about these analyses by asking -can I just include speed as a covariate with a stacked data layout such as the one below? I'm using a simplified layout showing two hypothetical participants.
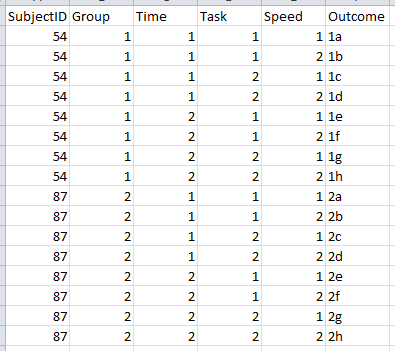
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That layout of the dataset is perfect for this approach
I would now consider changing the subject= option in the repeated statement to
subject=subjectID*time*task
to guarantee that there were unique records per covariate. This is in anticipation of the code with subject=subjectID perhaps/maybe/possibly causing an error of an infinite likelihood. However, try the original first, and if that error doesn't show up, you should be in good shape.
Steve Denham
Message was edited by: Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Steve,
Unfortunately, none of these analysis seem to work. Whether I leave Speed in the MODEL line or take it out, the analysis does not produce results and gives the following message (in Blue font) : "An infinite likelihood is assumed in iteration 0 because of a nonpositive definite estimated R matrix for SubjectID 1011" (note that SubjectID 1011 is the first participant in the data). Furthermore, the error occurs regardless of what the "SUBJECT = " is in the REPEATED sentence e.g..
The only way I can get the error to go away is my only focusing on one of the two levels of speed (RM3). However, speed obviously has to be taken out of the model for this to work.
For example, this works:
PROC MIXED DATA = Data;
CLASS Group RM1 RM2 RM3 SubjectID;
MODEL Outcome = Group|RM1|RM2; /*fits all possible interactions*/
REPEATED RM1 RM2 / TYPE = UN@UN SUBJECT = SubjectID;
WHERE RM3 = 0;
RUN;
*RM3 has been removed from the MODEL line and a WHERE statement has been added.;
However, this produces the infinity message I mention above:
PROC MIXED DATA = Data;
CLASS Group RM1 RM2 RM3 SubjectID;
MODEL Outcome = Group|RM1|RM2|RM3; /*fits all possible interactions*/
REPEATED RM1 RM2 / TYPE = UN@UN SUBJECT = SubjectID;
RUN;
*And this won't run happens even if I take out RM3 from the CLASS and MODEL or if I change "SUBJECT = " to something like SubjectID*Task*Time.;
Could it be possible that SAS is just not able to handle more than two repeated measures variables in one model?
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
What you are running into is a duplication of records situation. Consider the following, adapted from the repeated measures example in the PROC MIXED documentation:
data pr;
input Person Gender $ y1 y2 y3 y4;
y=y1; time=1; task=1; output;
y=y2; time=1; task=2; output;
y=y3; time=2; task=1; output;
y=y4; time=2; task=2;; output;
drop y1-y4;
datalines;
1 F 21.0 20.0 21.5 23.0
2 F 21.0 21.5 24.0 25.5
3 F 20.5 24.0 24.5 26.0
4 F 23.5 24.5 25.0 26.5
5 F 21.5 23.0 22.5 23.5
6 F 20.0 21.0 21.0 22.5
7 F 21.5 22.5 23.0 25.0
8 F 23.0 23.0 23.5 24.0
9 F 20.0 21.0 22.0 21.5
10 F 16.5 19.0 19.0 19.5
11 F 24.5 25.0 28.0 28.0
12 M 26.0 25.0 29.0 31.0
13 M 21.5 22.5 23.0 26.5
14 M 23.0 22.5 24.0 27.5
15 M 25.5 27.5 26.5 27.0
16 M 20.0 23.5 22.5 26.0
17 M 24.5 25.5 27.0 28.5
18 M 22.0 22.0 24.5 26.5
19 M 24.0 21.5 24.5 25.5
20 M 23.0 20.5 31.0 26.0
21 M 27.5 28.0 31.0 31.5
22 M 23.0 23.0 23.5 25.0
23 M 21.5 23.5 24.0 28.0
24 M 17.0 24.5 26.0 29.5
25 M 22.5 25.5 25.5 26.0
26 M 23.0 24.5 26.0 30.0
27 M 22.0 21.5 23.5 25.0
;
data pr1;
set pr;
speed=mod(_n_,2);
run;
data pr2;
set pr ;
speed=mod(_n_+1,2);
run;
data pr3;
set pr1 pr2;
run;
proc sort data=pr3;
by person gender time task;
run;
PROC MIXED DATA = pr3;
CLASS Gender time task person ;
MODEL y = Gender|time|task|speed; /*fits all possible interactions*/
REPEATED time task / TYPE = UN@CS SUBJECT = person*time*task*speed;
RUN;
Look carefully at pr3, for the first person:
Person Gender y time task speed
1 F 21 1 1 1
1 F 21 1 1 0
1 F 20 1 2 0
1 F 20 1 2 1
1 F 21.5 2 1 1
1 F 21.5 2 1 0
1 F 23 2 2 0
1 F 23 2 2 1
Note that for any combination of time, task and speed there is a unique record. The key is the correct specification of the subject, so that only one record is referred to. I think if you try:
PROC MIXED DATA = Data;
CLASS Group RM1 RM2 RM3 SubjectID;
MODEL Outcome = Group|RM1|RM2|RM3; /*fits all possible interactions*/
REPEATED RM1 RM2 / TYPE = UN@UN SUBJECT = SubjectID*RM1*RM2*RM3;
RUN;
you will get what you need.
Steve Denham
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Steve,
Thank you for your detailed response. I think I eventually cracked a way of doing this by using the Genmod function as follows:
*Data needs to be in Long Format;
PROC GENMOD DATA = MyData;
CLASS ParticipantID;
MODEL y = Time|Task|Speed|Group;
REPEATED SUBJECT= ParticipantID / TYPE=exch COVB CORRW;
RUN;
This model doesn't explicitly detail the nested structure of Time, Task and Speed, but according to this SAS link, this isn't too big a deal:
http://support.sas.com/kb/24/200.html
It seems to work well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Good enough!!!
Steve Denham

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I realize this is an old post, but it does not appear to have a satisfactory answer.
I suggest reviewing Moser's Paper:
https://support.sas.com/resources/papers/proceedings/proceedings/sugi29/188-29.pdf
Extending the code on page 6, we have:
proc mixed data=data
class group rm1 rm2 rm3 id;
model outcome = group rm1|rm2|rm3 / solution ddfm=kr;
random id rm1(id) rm2(id) rm3(id) / v vcorr;
run;
Alternatively, a more computationally efficient coding will be:
proc mixed data=data
class group rm1 rm2 rm3 id;
model outcome = group rm1|rm2|rm3 / solution ddfm=kr;
random int rm1 rm2 rm3 / subject=id v vcorr;
run;
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →ANOVA, or Analysis Of Variance, is used to compare the averages or means of two or more populations to better understand how they differ. Watch this tutorial for more.

Find more tutorials on the SAS Users YouTube channel.
-
11 replies
-
12-04-2014 01:20 PM
-
8570 views
-
0 likes
-
3 in conversation
-
