- Home
- /
- SAS Viya
- /
- Visual Analytics
- /
- Sankey Diagrams in SAS VA
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I would like to create a Sankey diagram that shows the path that 6 different categories of Customers take during a week.
Example, I have 2000 New Customers last week, during the week 1,500 may have ordered a Product, 400 may have not ordered anything & 100 may have Cancelled their subscription.
As well as New Customers, I have another 6 categories to track.
The info at the below link has been very helpful but I can't get the data to display the flow of the Number of Customers performing a certain action.
http://blogs.sas.com/content/sascom/2014/08/19/path-analysis-with-sas-visual-analytics/
Can anyone suggest a video or step by step tutorial to help me understand the fields that need to be populated in VA to create a Sankey diagram to suit.
Thanks, hope this makes some sense, otherwise feel free to ask questions.
Peter
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You are getting there!
Assuming you meant extending EXISTING node since your path as per previous examples was NEW->EXISTING!? So do get a path such as NEW->EXISTING->HOLIDAY and NEW->EXISTING->ORDERED you would have a data structure such as:
| Time | Sequence | Event | Weight |
|---|---|---|---|
| 01/01/2015 | 200 | NEW | 0 |
| 01/01/2015 | 200 | EXISTING | 0 |
| 01/01/2015 | 200 | ORDERED | 100 |
| 02/01/2015 | 201 | NEW | 0 |
| 02/01/2015 | 201 | EXISTING | 0 |
| 02/01/2015 | 201 | HOLIDAY | 80 |
| 03/01/2015 | 202 | NEW | 0 |
| 03/01/2015 | 202 | CANCELLED | 20 |
Note, that I only apply a weight to leaf nodes for simplicity and the fact the path analysis will aggregate weights across all common sequences. In general every single path need to be represented in your data structure by a sequence of events (that's what path analysis really is). While its relatively simple in your scenario - it's quite challenging in typical transacational data bases with millions of transacations and potential paths.
Hope this helps. Cheers, Falko

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
Two SAS Global Forum 2015 papers on Sankey Diagrams in SAS Visual Analytics you may want to look at are as follows:
Paper SAS1808-2015 - Sankey Diagrams in SAS Visual Analytics by Varsha Chawla and Renato Luppi
Hope these help.
Kind Regards,
Michelle
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Michelle,
Appreciate this info, my main issue is trying to understand what to info to assign to the Event, Sequence, TransID & Weight.
I've tried many variations so maybe your info can help. Cheers Peter.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
Can you share any more details about your data?
About the data roles, here is a quick attempt to explain each role:
TransID identifies the entity whose status or actions you are tracking through the path. Depending on the type of data you have, this might be a user ID, a customer account number, a session ID (like for website traffic), a case number, and so on.
Event contains the statuses or actions that will be represented as nodes in the diagram. For sales data, Event might be the products that are sold. For customer status, the Event role might be actions like "Account created", "Account canceled", "Service request filed", etc.
Sequence specifies the order in which the events take place. Often this would be a date, but it doesn't have to be.
Weight is an optional measure that can be used as a modifier for the path width. For example, for sales data, you might assign the sale price as the weight.
You can only assign a single column each to the TransID and Event data roles, so if you need to visualize six categories, I believe you will need to either create multiple diagrams or somehow combine the categories as part of your data preparation.
I hope that helps a little.
Thanks,
Sam
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sam,
Thanks for your info, I have found that I can get the 6 (or more) Customer Types into my Diagram by using different 'Sequence Orders' for the same 'Event'.
The problem I have is that The Weight value (which for this purpose is the Customer Count in each category) are added together throughout the diagram.
Please see attachments;
Each shaded area is for a different Customer category, what action they take & what category they end up in.
- Example, in Grey, in the Event Column there's (200 - Weight) 'New' Customers
- 150 of these Customers Ordered a Product
- 50 complained
- 180 of the 200 (150 + 50) became 'Existing' customers
- 20 of them cancelled
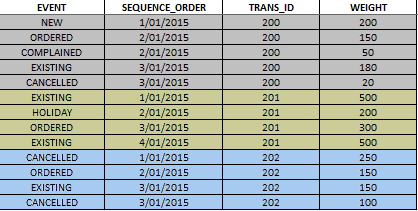
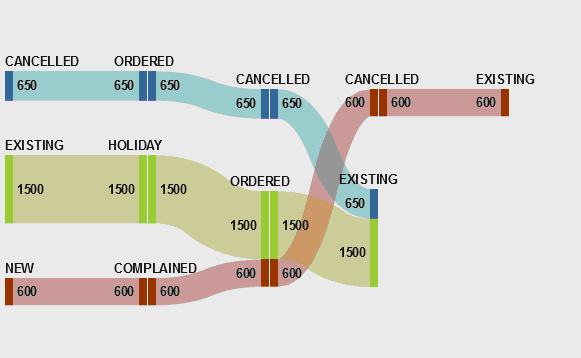
What I would like to see is the 'NEW' category be represented as '200', the path then splits into 2 parts with 150 Ordering & 50 Complaining.
Then the 200 Customers would be split into 180 Existing & 20 Cancelled Customers.
I've already done the tracking of the Customers to know where they came from & what they did, I just need to graph it as such.
Any suggestions welcome.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Peter,
The way path analysis works is by looking at the transactions first and then sorts each each event by their sequence order. In your example the NEW, EXISTING and CANCELLED events are all in different transacations (200, 201, 202) and as such represent different paths. You may have noticed that all three events are on the left side since they start off a new path. In order to have them appear within one path (and split into exisiting and cancelled customers as you describe) you would need to represent these within the same transaction or by grouping your data by the paths you describe.
Example:
| Time | Sequence | Event | Weight |
|---|---|---|---|
| 01/01/2015 | 200 | NEW | 0 |
| 01/01/2015 | 200 | EXISTING | 180 |
| 02/01/2015 | 201 | NEW | 0 |
| 02/01/2015 | 201 | CANCELLED | 20 |
Note, that the first event (NEW) starts with 0 count since child sequences carry the actual weight. The example only shows the first two sequences but hope this gets you started.
Cheers, Falko
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Falco,
That's very helpful!
I'm now into the part where I need to represent what Category the Customer went into & prepared the below to join onto the end of the 'New' 'Node'.
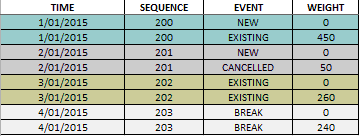
But I got this instead, I'm unsure where to use the '0' again to get the correct Weights where I need them?

What am I doing wrong?
Appreciate your help, I think I'm close to following you.
Cheers
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You are getting there!
Assuming you meant extending EXISTING node since your path as per previous examples was NEW->EXISTING!? So do get a path such as NEW->EXISTING->HOLIDAY and NEW->EXISTING->ORDERED you would have a data structure such as:
| Time | Sequence | Event | Weight |
|---|---|---|---|
| 01/01/2015 | 200 | NEW | 0 |
| 01/01/2015 | 200 | EXISTING | 0 |
| 01/01/2015 | 200 | ORDERED | 100 |
| 02/01/2015 | 201 | NEW | 0 |
| 02/01/2015 | 201 | EXISTING | 0 |
| 02/01/2015 | 201 | HOLIDAY | 80 |
| 03/01/2015 | 202 | NEW | 0 |
| 03/01/2015 | 202 | CANCELLED | 20 |
Note, that I only apply a weight to leaf nodes for simplicity and the fact the path analysis will aggregate weights across all common sequences. In general every single path need to be represented in your data structure by a sequence of events (that's what path analysis really is). While its relatively simple in your scenario - it's quite challenging in typical transacational data bases with millions of transacations and potential paths.
Hope this helps. Cheers, Falko
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Again Falko,
I have another couple of questions if you don't mind.
I've been studying the behaviour of the data entered vs the output &wanted to check a couple of things.
Your response advised "the path analysis will aggregate weights across all common sequences" does 'Sequence' refer to the Date values or the Transaction IDs ie (201, 202...) ? - I'm still trying to figure out what makes them split the totals...
Also, is there a relationship between the 'Event' & the order of the Sequence to get the Events to merge?
What I mean is just as an example - if you have 2 Trans IDs & the second sequence for both has the same Event ie 'Ordered', they would be displayed as merged?
Thanks Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
The weight aggregation shown in the diagram is based on the total weight of the in/out bound paths. The main driver here is the transaction identifier. The time/date values are just used to specifiy the correct order of events within the given transaction. Keep in mind - the weight indicates the 'path' weight - not individual event weights.
Whether or not a path will be split just depends whether you have two or more paths which share a sequence of events. If they do - the shared sequence of events are displayed as one path. In my last example above I define a path NEW->EXISTING-ORDERD (row 1-3) and a second path NEW->EXISTING->HOLIDAY (row 4-7). As you can see NEW->EXISTING is a sequence of shared events although ORDERED and HOLIDAY are not - hence the path will be split at this point. However - as mentioned before - the aggregation weight is for the entire path. So in your example the total weight is calculated by aggregating all weight values from row 1-3 (NEW->EXISTING-ORDERD) and row 4-7 for the second path.
It's sometimes easier to see and understand weight calculations if you switch the link color (Properties panel) to 'Event' or 'Path' - dependent what you want to see. This will color each sequence differently and also show individual weights for each path.
Hope this helps. Cheers, Falko
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks again,
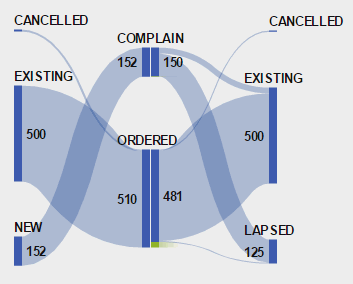
Do you think it's possible then to reproduce a diagram like I've attached to display Customers actions?
Each of 3 Segments start with a value (Count of Customers), then may perform one action like Complain (also displayed as a Customer count) & then move to a final 'End of week' segment.
They all need to represent each event with a customer count number.
Can this be done with VA Sankey diagrams?
I've read your articles Franco which have the table format to use for certain situations, I wonder if there's an example for this kind of display?
Any suggests welcome!
Thanks Peter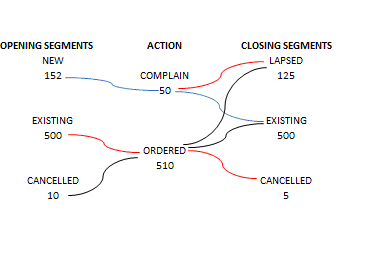
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well, I would say yes - although I'm struggling to fully understand your diagram. The way path analysis works in VA is by aggregating all transactions for a given path. This means you will always end up with the full count on the right most nodes unless you have drop-offs somewhere along the paths. The diagram you have above doesn't show any drop-offs but still doesn't add up across sequences. In your example we have 662 customers (NEW/152 + EXISTING/500 + CANCELLED/10) and only 560 took an action (COMPLAIN/50 + ORDERED/510). Can I assume some of the customers just didn't do any actions at all?
Here is a sample data file which has weight values specified based on your example - although you will see that I had to introduce some drop offs in order to get your counts right.
| id | event | time | weight |
| 198 | NEW | 100 | 0 |
| 198 | COMPLAIN | 101 | 2 |
| 200 | NEW | 100 | 0 |
| 200 | COMPLAIN | 101 | 0 |
| 200 | LAPSED | 102 | 120 |
| 201 | NEW | 100 | 0 |
| 201 | COMPLAIN | 101 | 0 |
| 201 | EXISTING | 102 | 30 |
| 202 | EXISTING | 100 | 0 |
| 202 | ORDERED | 101 | 0 |
| 202 | LAPSED | 102 | 5 |
| 199 | EXISTING | 100 | 0 |
| 199 | ORDERED | 101 | 29 |
| 203 | EXISTING | 100 | 0 |
| 203 | ORDERED | 101 | 0 |
| 203 | EXISTING | 102 | 465 |
| 204 | EXISTING | 100 | 0 |
| 204 | ORDERED | 101 | 0 |
| 204 | CANCELLED | 102 | 1 |
| 206 | CANCELLED | 100 | 0 |
| 206 | ORDERED | 101 | 0 |
| 206 | EXISTING | 102 | 5 |
| 207 | CANCELLED | 100 | 0 |
| 207 | ORDERED | 101 | 0 |
| 207 | CANCELLED | 102 | 5 |
Visualizing this in VA would produce something like:
Since sankey diagram will always show the path width based on the frequency or weight some paths will appear quite thin. If you need to see detail values behind such paths - the 'show details' option (button top right corner) usually helps:
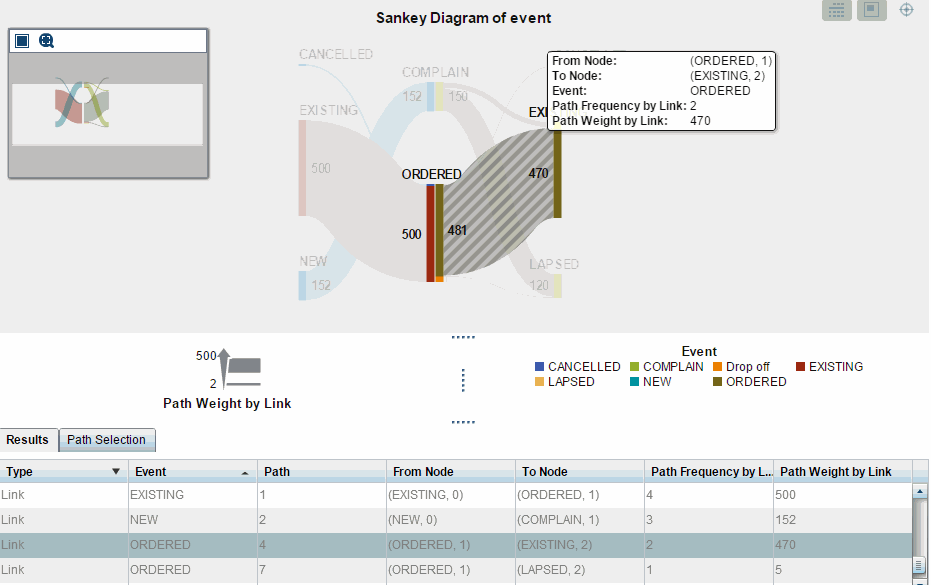
Note, I should also mention that instead of using weights - you probably would just use the standard frequency as in a real environment you typically have one transaction represent one customer touch point. As such the total count of these transactions will give you the same diagram. Using weights here - just simplifies the sample data and reduces the overal number of rows required.
Hope this helps. Cheers, Falko
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks again Falko,
Apologies for my chart as it only had dummy figures as an illustration rather than numbers that were supposed to aggregate to both sides.
This last table is a good guide, I still have a question about the rules for merging.
Correct me if I'm wrong but the 'Event' (NEW, EXISTING etc) & 'Trans ID' (100, 101, 102 etc) both must be the same to get the paths to merge?
Is that right?
If not, what must be the same or not the same to get the merge happening.
Cheers Peter
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well, it's more about the sequence of events which must be the same in order to have paths merged. The transaction ID is just used to differentiate between these sequences (for every customer visit you would get a new transaction ID in your example). Let's take the last transaction of my previous example (ID: 207). You will notice the weight is 5 - indicating we have 5 customers who took this particular path.
Alternatively in using a weight - you could just use the frequency and represent the same using the following. This is likely a common scenario in transactional data since every customer is traced a single entity.
| ID | EVENT | TIME | CUSTOMER_ID |
| 207 | CANCELLED | 100 | 1 |
| 207 | ORDERED | 101 | 1 |
| 207 | CANCELLED | 102 | 1 |
| 208 | CANCELLED | 100 | 2 |
| 208 | ORDERED | 101 | 2 |
| 208 | CANCELLED | 102 | 2 |
| 209 | CANCELLED | 100 | 1 |
| 209 | ORDERED | 101 | 1 |
| 209 | CANCELLED | 102 | 1 |
| 210 | CANCELLED | 100 | 3 |
| 210 | ORDERED | 101 | 3 |
| 210 | CANCELLED | 102 | 3 |
| 211 | CANCELLED | 100 | 4 |
| 211 | ORDERED | 101 | 4 |
| 211 | CANCELLED | 102 | 4 |
In this scenario all transactions with the event order of CANCELLED->ORDERED->CANCELLED are merged as one path. The overall path frequency is 5 since there are 5 transactions representing this sequence of events.
Hope this makes sense. Cheers, Falko
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi Falko,
I meant to say that the 'Time' (Sequence) value & the Event should be the same to get the merge.
The (Trans) ID would create a path in the graph.
Therefore if the Event & Time value were the same, they would merge?
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand in the Innovate Hub.
Watch Now →See how to use one filter for multiple data sources by mapping your data from SAS’ Alexandria McCall.

Find more tutorials on the SAS Users YouTube channel.
-
20 replies
-
05-09-2015 02:12 AM
-
14068 views
-
9 likes
-
4 in conversation
-
